从 XML 文档中提取内容的Java程序
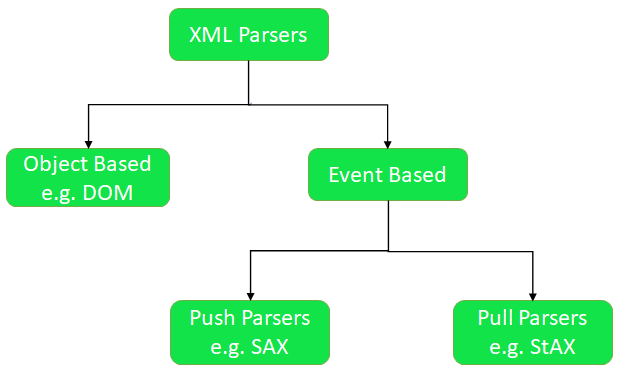
XML 文件在标签之间包含数据,因此与 docx 和 txt 等其他文件格式相比,读取数据比较复杂。有两种类型的解析器可以解析 XML 文件:
- 基于对象(例如 DOM)
- 基于事件(例如 SAX、StAX)
在本文中,我们将讨论如何使用Java DOM 解析器和Java SAX 解析器解析 XML。
Java DOM 解析器: DOM 代表文档对象模型。 DOM API 提供了读取和写入 XML 文件的类。 DOM 读取整个文档。它在读取中小型 XML 文件时很有用。它是一个基于树的解析器,与 SAX 相比有点慢,并且在加载到内存时占用更多空间。我们可以使用 DOM API 插入和删除节点。
我们必须按照以下过程从Java中的 XML 文件中提取数据。
- 实例化 XML 文件:
- 获取根节点:我们可以使用 getDocumentElement() 来获取根节点和 XML 文件的元素。
- 获取所有节点:使用 getElementByTagName() 返回文档顺序中具有给定标签名称并包含在文档中的所有元素的 NodeList。
- 通过文本值获取节点:我们可以使用 getElementByTextValue() 方法来通过其值搜索节点。
- 通过属性值获取节点:我们可以将 getElementByTagName() 方法与 getAttribute() 方法一起使用。
现在让我们看一个使用Java DOM Parser 从 XML 中提取数据的示例。
创建一个.xml文件,在本例中,我们创建了 Gfg.xml
XML
1
geek1
D.S.A
online self paced
Lifetime
2
geek2
System Design
online live course
10 Lectures
3
geek3
Compitative Programming
online live course
8 weeks
4
geek4
Complete Interview Preparation
online self paced
Lifetime
Java
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.DocumentBuilder;
import org.w3c.dom.Document;
import org.w3c.dom.NodeList;
import org.w3c.dom.Node;
import org.w3c.dom.Element;
import java.io.File;
public class GfgXmlExtractor {
public static void main(String argv[])
{
try {
// creating a constructor of file class and
// parsing an XML file
File file = new File(
"F:\\geeksforgeeks_contributions\\gfg.xml");
// Defines a factory API that enables
// applications to obtain a parser that produces
// DOM object trees from XML documents.
DocumentBuilderFactory dbf
= DocumentBuilderFactory.newInstance();
// we are creating an object of builder to parse
// the xml file.
DocumentBuilder db = dbf.newDocumentBuilder();
Document doc = db.parse(file);
/*here normalize method Puts all Text nodes in
the full depth of the sub-tree underneath this
Node, including attribute nodes, into a "normal"
form where only structure separates
Text nodes, i.e., there are neither adjacent
Text nodes nor empty Text nodes. */
doc.getDocumentElement().normalize();
System.out.println(
"Root element: "
+ doc.getDocumentElement().getNodeName());
// Here nodeList contains all the nodes with
// name geek.
NodeList nodeList
= doc.getElementsByTagName("geek");
// Iterate through all the nodes in NodeList
// using for loop.
for (int i = 0; i < nodeList.getLength(); ++i) {
Node node = nodeList.item(i);
System.out.println("\nNode Name :"
+ node.getNodeName());
if (node.getNodeType()
== Node.ELEMENT_NODE) {
Element tElement = (Element)node;
System.out.println(
"User id: "
+ tElement
.getElementsByTagName("id")
.item(0)
.getTextContent());
System.out.println(
"User Name: "
+ tElement
.getElementsByTagName(
"username")
.item(0)
.getTextContent());
System.out.println(
"Enrolled Course: "
+ tElement
.getElementsByTagName(
"EnrolledCourse")
.item(0)
.getTextContent());
System.out.println(
"Mode: "
+ tElement
.getElementsByTagName("mode")
.item(0)
.getTextContent());
System.out.println(
"Duration: "
+ tElement
.getElementsByTagName(
"duration")
.item(0)
.getTextContent());
}
}
}
// This exception block catches all the exception
// raised.
// For example if we try to access a element by a
// TagName that is not there in the XML etc.
catch (Exception e) {
System.out.println(e);
}
}
}Java
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
public class GfgSaxXmlParser {
public static void main(String args[])
{
try {
/*SAXParserFactory is a factory API that
enables applications to configure and obtain a
SAX based parser to parse XML documents. */
SAXParserFactory factory
= SAXParserFactory.newInstance();
// Creating a new instance of a SAXParser using
// the currently configured factory parameters.
SAXParser saxParser = factory.newSAXParser();
// DefaultHandler is Default base class for SAX2
// event handlers.
DefaultHandler handler = new DefaultHandler() {
boolean id = false;
boolean username = false;
boolean EnrolledCourse = false;
boolean mode = false;
boolean duration = false;
// Receive notification of the start of an
// element. parser starts parsing a element
// inside the document
public void startElement(
String uri, String localName,
String qName, Attributes attributes)
throws SAXException
{
if (qName.equalsIgnoreCase("Id")) {
id = true;
}
if (qName.equalsIgnoreCase(
"username")) {
username = true;
}
if (qName.equalsIgnoreCase(
"EnrolledCourse")) {
EnrolledCourse = true;
}
if (qName.equalsIgnoreCase("mode")) {
mode = true;
}
if (qName.equalsIgnoreCase(
"duration")) {
duration = true;
}
}
// Receive notification of character data
// inside an element, reads the text value of
// the currently parsed element
public void characters(char ch[], int start,
int length)
throws SAXException
{
if (id) {
System.out.println(
"ID : "
+ new String(ch, start,
length));
id = false;
}
if (username) {
System.out.println(
"User Name: "
+ new String(ch, start,
length));
username = false;
}
if (EnrolledCourse) {
System.out.println(
"Enrolled Course: "
+ new String(ch, start,
length));
EnrolledCourse = false;
}
if (mode) {
System.out.println(
"mode: "
+ new String(ch, start,
length));
mode = false;
}
if (duration) {
System.out.println(
"duration : "
+ new String(ch, start,
length));
duration = false;
}
}
};
/*Parse the content described by the giving
Uniform Resource
Identifier (URI) as XML using the specified
DefaultHandler. */
saxParser.parse(
"F:\\geeksforgeeks_contributions\\gfg.xml",
handler);
}
catch (Exception e) {
System.out.println(e);
}
}
}现在为Java DOM 解析器创建一个Java文件。在这种情况下,GfgXmlExtractor。Java
Java
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.DocumentBuilder;
import org.w3c.dom.Document;
import org.w3c.dom.NodeList;
import org.w3c.dom.Node;
import org.w3c.dom.Element;
import java.io.File;
public class GfgXmlExtractor {
public static void main(String argv[])
{
try {
// creating a constructor of file class and
// parsing an XML file
File file = new File(
"F:\\geeksforgeeks_contributions\\gfg.xml");
// Defines a factory API that enables
// applications to obtain a parser that produces
// DOM object trees from XML documents.
DocumentBuilderFactory dbf
= DocumentBuilderFactory.newInstance();
// we are creating an object of builder to parse
// the xml file.
DocumentBuilder db = dbf.newDocumentBuilder();
Document doc = db.parse(file);
/*here normalize method Puts all Text nodes in
the full depth of the sub-tree underneath this
Node, including attribute nodes, into a "normal"
form where only structure separates
Text nodes, i.e., there are neither adjacent
Text nodes nor empty Text nodes. */
doc.getDocumentElement().normalize();
System.out.println(
"Root element: "
+ doc.getDocumentElement().getNodeName());
// Here nodeList contains all the nodes with
// name geek.
NodeList nodeList
= doc.getElementsByTagName("geek");
// Iterate through all the nodes in NodeList
// using for loop.
for (int i = 0; i < nodeList.getLength(); ++i) {
Node node = nodeList.item(i);
System.out.println("\nNode Name :"
+ node.getNodeName());
if (node.getNodeType()
== Node.ELEMENT_NODE) {
Element tElement = (Element)node;
System.out.println(
"User id: "
+ tElement
.getElementsByTagName("id")
.item(0)
.getTextContent());
System.out.println(
"User Name: "
+ tElement
.getElementsByTagName(
"username")
.item(0)
.getTextContent());
System.out.println(
"Enrolled Course: "
+ tElement
.getElementsByTagName(
"EnrolledCourse")
.item(0)
.getTextContent());
System.out.println(
"Mode: "
+ tElement
.getElementsByTagName("mode")
.item(0)
.getTextContent());
System.out.println(
"Duration: "
+ tElement
.getElementsByTagName(
"duration")
.item(0)
.getTextContent());
}
}
}
// This exception block catches all the exception
// raised.
// For example if we try to access a element by a
// TagName that is not there in the XML etc.
catch (Exception e) {
System.out.println(e);
}
}
}
输出
Root element: class
Node Name :geek
User id: 1
User Name: geek1
Enrolled Course: D.S.A
Mode: online self paced
Duration: Lifetime
Node Name :geek
User id: 2
User Name: geek2
Enrolled Course: System Design
Mode: online live course
Duration: 10 Lectures
Node Name :geek
User id: 3
User Name: geek3
Enrolled Course: Compitative Programming
Mode: online live course
Duration: 8 weeks
Node Name :geek
User id: 4
User Name: geek4
Enrolled Course: Complete Interview Preparation
Mode: online self paced
Duration: Lifetime
方法 2 : Java SAX 解析器
Java中的 SAX Parser 提供 API 来解析 XML 文档。 SAX 解析器与 DOM 解析器有很大不同,因为它不会将完整的 XML 加载到内存中并按顺序读取 XML 文档。在 SAX 中,解析由ContentHandler接口完成,该接口由DefaultHandler类实现。
现在让我们看一个使用Java SAX Parser 从 XML 中提取数据的示例。
为 SAX 解析器创建一个Java文件。在本例中,我们创建了 GfgSaxXmlExtractor。Java
Java
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
public class GfgSaxXmlParser {
public static void main(String args[])
{
try {
/*SAXParserFactory is a factory API that
enables applications to configure and obtain a
SAX based parser to parse XML documents. */
SAXParserFactory factory
= SAXParserFactory.newInstance();
// Creating a new instance of a SAXParser using
// the currently configured factory parameters.
SAXParser saxParser = factory.newSAXParser();
// DefaultHandler is Default base class for SAX2
// event handlers.
DefaultHandler handler = new DefaultHandler() {
boolean id = false;
boolean username = false;
boolean EnrolledCourse = false;
boolean mode = false;
boolean duration = false;
// Receive notification of the start of an
// element. parser starts parsing a element
// inside the document
public void startElement(
String uri, String localName,
String qName, Attributes attributes)
throws SAXException
{
if (qName.equalsIgnoreCase("Id")) {
id = true;
}
if (qName.equalsIgnoreCase(
"username")) {
username = true;
}
if (qName.equalsIgnoreCase(
"EnrolledCourse")) {
EnrolledCourse = true;
}
if (qName.equalsIgnoreCase("mode")) {
mode = true;
}
if (qName.equalsIgnoreCase(
"duration")) {
duration = true;
}
}
// Receive notification of character data
// inside an element, reads the text value of
// the currently parsed element
public void characters(char ch[], int start,
int length)
throws SAXException
{
if (id) {
System.out.println(
"ID : "
+ new String(ch, start,
length));
id = false;
}
if (username) {
System.out.println(
"User Name: "
+ new String(ch, start,
length));
username = false;
}
if (EnrolledCourse) {
System.out.println(
"Enrolled Course: "
+ new String(ch, start,
length));
EnrolledCourse = false;
}
if (mode) {
System.out.println(
"mode: "
+ new String(ch, start,
length));
mode = false;
}
if (duration) {
System.out.println(
"duration : "
+ new String(ch, start,
length));
duration = false;
}
}
};
/*Parse the content described by the giving
Uniform Resource
Identifier (URI) as XML using the specified
DefaultHandler. */
saxParser.parse(
"F:\\geeksforgeeks_contributions\\gfg.xml",
handler);
}
catch (Exception e) {
System.out.println(e);
}
}
}
输出
ID : 1
User Name: geek1
Enrolled Course: D.S.A
mode: online self paced
duration : Lifetime
ID : 2
User Name: geek2
Enrolled Course: System Design
mode: online live course
duration : 10 Lectures
ID : 3
User Name: geek3
Enrolled Course: Compitative Programming
mode: online live course
duration : 8 weeks
ID : 4
User Name: geek4
Enrolled Course: Complete Interview Preparation
mode: online self paced
duration : Lifetime