根据多列中的值拆分 Pandas 中的数据框
在本文中,我们将了解如何使用Python以各种方法和基于各种参数来划分数据帧。为了根据列中存在的值将数据框划分为两个或多个单独的数据框,我们首先创建一个数据框。
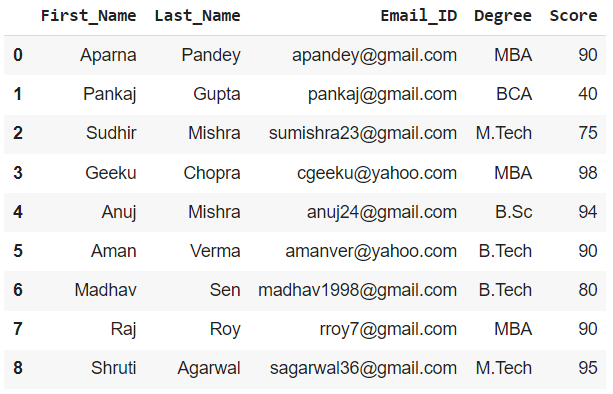
为演示创建一个 DataFrame:
Python3
# importing pandas as pd
import pandas as pd
# dictionary of lists
dict = {'First_Name': ["Aparna", "Pankaj", "Sudhir",
"Geeku", "Anuj", "Aman",
"Madhav", "Raj", "Shruti"],
'Last_Name': ["Pandey", "Gupta", "Mishra",
"Chopra", "Mishra", "Verma",
"Sen", "Roy", "Agarwal"],
'Email_ID': ["apandey@gmail.com", "pankaj@gmail.com",
"sumishra23@gmail.com", "cgeeku@yahoo.com",
"anuj24@gmail.com", "amanver@yahoo.com",
"madhav1998@gmail.com", "rroy7@gmail.com",
"sagarwal36@gmail.com"],
'Degree': ["MBA", "BCA", "M.Tech", "MBA", "B.Sc",
"B.Tech", "B.Tech", "MBA", "M.Tech"],
'Score': [90, 40, 75, 98, 94, 90, 80, 90, 95]}
# creating dataframe
df = pd.DataFrame(dict)
print(df)Python3
# creating a new dataframe by applying the required
# conditions in []
df1 = df[df['Score'] >= 80]
print(df1)Python3
# Creating on the basis of Last_Name
dfname = df[df['Last_Name'] == 'Mishra']
print(dfname)Python3
# creating the mask variable with appropriate
# condition
mask_var = df['Degree'] =='MBA'
# creating a dataframe
df1_mask = df[mask_var]
print(df1_mask)Python3
# creating dataframe with inverted mask variable
df2_mask = df[~mask_var]
print(df2_mask)Python3
# Creating an object using groupby
grouped = df.groupby('Degree')
# the return type of the object 'grouped' is
# pandas.core.groupby.generic.DataFrameGroupBy.
# Creating a dataframe from the object using get_group().
# dataframe of students with Degree as MBA.
df_grouped = grouped.get_group('MBA')
print(df_grouped)Python3
# Creating another object using groupby
grouped2 = df.groupby('Score')
# the return type of the object 'grouped2' is
# pandas.core.groupby.generic.DataFrameGroupBy.
# Creating a dataframe from the object
# using get_group() dataframe of students
# with Score = 90
df_grouped2 = grouped2.get_group(90)
print(df_grouped2)输出:
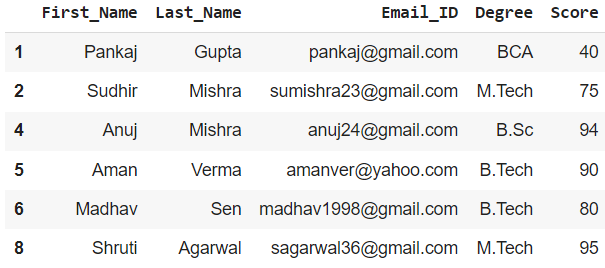
方法一:通过布尔索引
我们可以通过使用布尔索引方法并提及所需的标准,根据特定列值从给定数据帧创建多个数据帧。
示例 1:为分数 >= 80 的学生创建数据框
Python3
# creating a new dataframe by applying the required
# conditions in []
df1 = df[df['Score'] >= 80]
print(df1)
输出:

示例 2:为 Last_Name 为 Mishra 的学生创建一个数据框
Python3
# Creating on the basis of Last_Name
dfname = df[df['Last_Name'] == 'Mishra']
print(dfname)
输出:

我们也可以通过放置适当的条件对其他列执行相同的操作
方法 2:使用掩码变量进行布尔索引
我们在前面的方法中为列的条件创建了一个掩码变量
示例 1:获取具有 MBA 学位的学生的数据框
Python3
# creating the mask variable with appropriate
# condition
mask_var = df['Degree'] =='MBA'
# creating a dataframe
df1_mask = df[mask_var]
print(df1_mask)
输出 :

示例 2:获取其余学生的数据框
要获取数据框中的其余值,我们可以简单地通过在其后添加 ~(波浪号) 来反转掩码变量。
Python3
# creating dataframe with inverted mask variable
df2_mask = df[~mask_var]
print(df2_mask)
输出 :
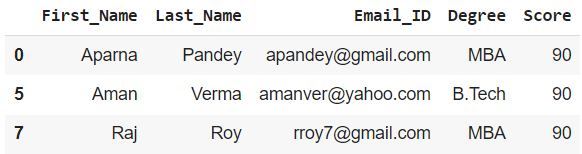
方法三:使用groupby()函数
使用 groupby() 我们可以使用特定的列值对行进行分组,然后将其显示为单独的数据框。
示例 1:根据学位对所有学生进行分组并按要求显示
Python3
# Creating an object using groupby
grouped = df.groupby('Degree')
# the return type of the object 'grouped' is
# pandas.core.groupby.generic.DataFrameGroupBy.
# Creating a dataframe from the object using get_group().
# dataframe of students with Degree as MBA.
df_grouped = grouped.get_group('MBA')
print(df_grouped)
输出:拥有MBA学位的学生数据框

示例 2:根据学生的分数对所有学生进行分组并按要求显示
Python3
# Creating another object using groupby
grouped2 = df.groupby('Score')
# the return type of the object 'grouped2' is
# pandas.core.groupby.generic.DataFrameGroupBy.
# Creating a dataframe from the object
# using get_group() dataframe of students
# with Score = 90
df_grouped2 = grouped2.get_group(90)
print(df_grouped2)
输出:分数 = 90 的学生数据框。