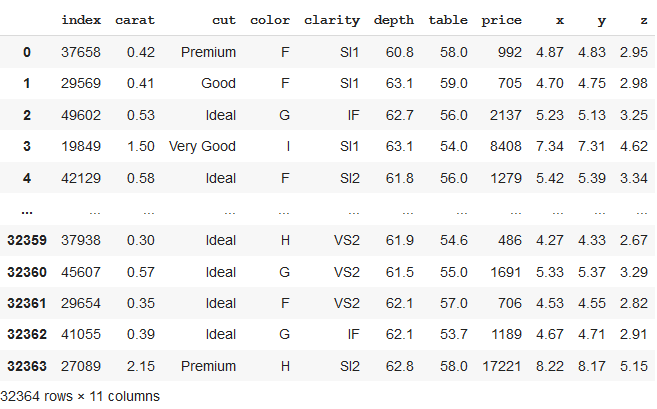
按行拆分 Pandas 数据框
我们可以尝试不同的方法来拆分 Dataframe 以获得所需的结果。让我们以钻石数据集为例。
Python3
# importing libraries
import seaborn as sns
import pandas as pd
import numpy as np
# data needs not to be downloaded separately
df = sns.load_dataset('diamonds')
df.head()Python3
# splitting dataframe by row index
df_1 = df.iloc[:1000,:]
df_2 = df.iloc[1000:,:]
print("Shape of new dataframes - {} , {}".format(df_1.shape, df_2.shape))Python3
# splitting dataframe by groups
# grouping by particular dataframe column
grouped = df.groupby(df.color)
df_new = grouped.get_group("E")
df_newPython3
# splitting dataframe in a particular size
df_split = df.sample(frac=0.6,random_state=200)
df_split.reset_index()输出:
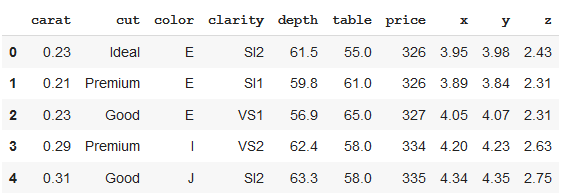
方法 1:按行索引拆分 Pandas Dataframe
在下面的代码中,数据帧分为两部分,前 1000 行,其余行。我们可以看到新形成的数据帧的形状作为给定代码的输出。
Python3
# splitting dataframe by row index
df_1 = df.iloc[:1000,:]
df_2 = df.iloc[1000:,:]
print("Shape of new dataframes - {} , {}".format(df_1.shape, df_2.shape))
输出:
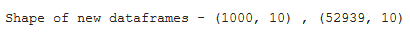
方法 2:按由唯一列值组成的组拆分 Pandas Dataframe
在这里,我们将首先按列值“颜色”对数据进行分组。新形成的数据框由颜色=“E”的分组数据组成。
Python3
# splitting dataframe by groups
# grouping by particular dataframe column
grouped = df.groupby(df.color)
df_new = grouped.get_group("E")
df_new
输出:
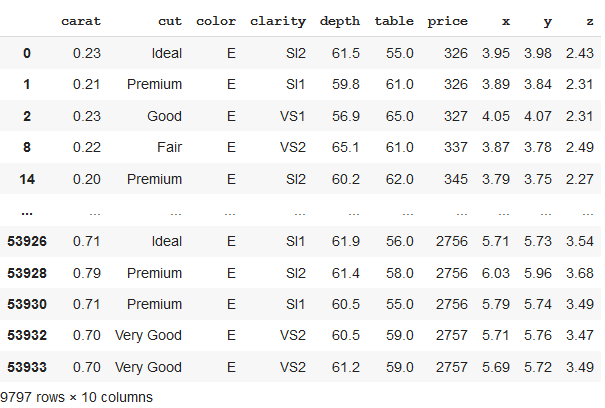
方法 3:将 Pandas 数据帧拆分为预定大小的块
在上面的代码中,我们可以看到我们已经形成了一个大小为 0.6 的新数据集,即总行数(或数据集长度)的 60%,现在由 32364 行组成。这些行是随机选择的。
Python3
# splitting dataframe in a particular size
df_split = df.sample(frac=0.6,random_state=200)
df_split.reset_index()
输出: