使用 DataComPy 比较 Pandas 数据帧
众所周知, Python是一种多范式、通用语言,因其广泛的库支持和活跃的社区而被广泛用于数据分析。使用Python比较两个 Pandas 数据帧的最常见方法是:
- 使用 difflib
- 使用fuzzywuzzy
- 正则表达式匹配
这些方法被经验丰富的开发人员和新开发人员广泛使用,但是如果我们需要一份报告来查找所有匹配/不匹配的列和行怎么办?这是 DataComPy 库出现的时候。
DataComPy是由 capitalone 开源的 Pandas 库。它最初的目的是为了取代 Pandas 数据帧的 PROC COMPARE。它需要两个数据框作为输入,并为我们提供一个包含统计信息的可读报告,让我们知道两个数据框之间的相似之处和不同之处。
通过 pip3 安装:
pip3 install datacompy
例子:
from io import StringIO
import pandas as pd
import datacompy
data1 = """employee_id, name
1, rajiv kapoor
2, rahul agarwal
3, alice johnson
"""
data2 = """employee_id, name
1, rajiv khanna
2, rahul aggarwal
3, alice tyson
"""
df1 = pd.read_csv(StringIO(data1))
df2 = pd.read_csv(StringIO(data2))
compare = datacompy.Compare(
df1,
df2,
# You can also specify a list
# of columns
join_columns = 'employee_id',
# Optional, defaults to 0
abs_tol = 0,
# Optional, defaults to 0
rel_tol = 0,
# Optional, defaults to 'df1'
df1_name = 'Original',
# Optional, defaults to 'df2'
df2_name = 'New'
)
# if ignore_exra_columns=True,
# the function won't return False
# in case of non-overlapping
# column names
compare.matches(ignore_extra_columns = False)
# This method prints out a human-readable
# report summarizing and sampling
# differences
print(compare.report())
输出:
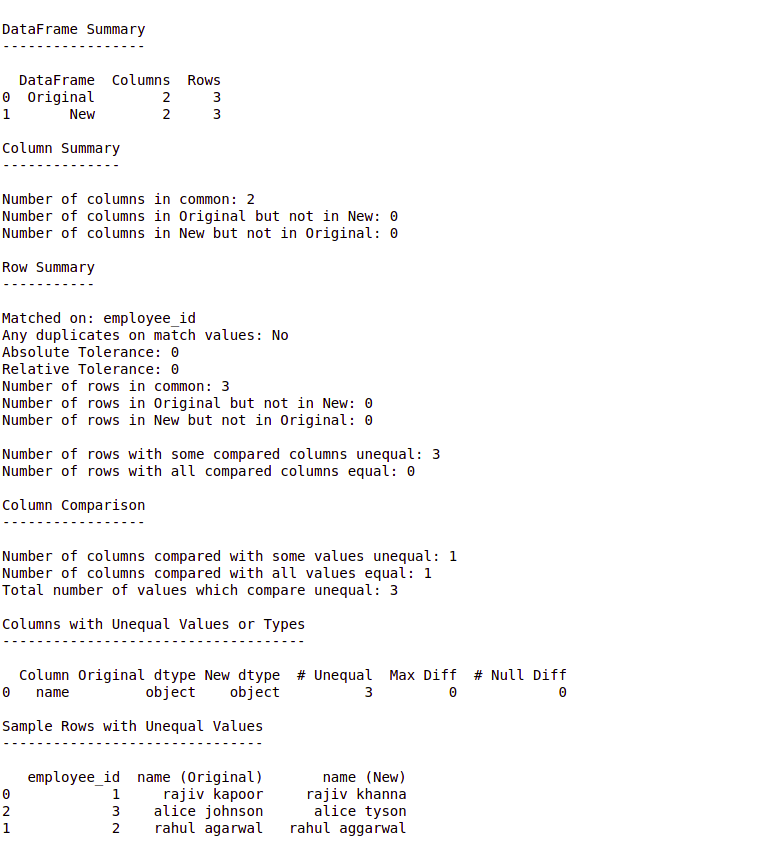
解释:
- 在上面的示例中,我们将两个数据框连接到匹配的列上。我们也可以通过:
on_index = True而不是“join_columns”来加入索引。 -
Compare.matches()是一个布尔函数。如果匹配,则返回 True,否则返回 False。 - 默认情况下,DataComPy 仅在 100% 匹配时才返回 True。我们可以通过将 abs_tol 和 rel_tol 的值设置为非零来调整这一点,这使我们能够指定可以容忍的数值之间的偏差量。它们分别代表绝对公差和相对公差。
- 从上面的示例中我们可以看到,DataComPy 是一个非常强大的库,它在我们必须生成 2 个数据帧的比较报告的情况下非常有用。