Python| Pandas 中的数据比较和选择
Python是一种用于进行数据分析的出色语言,主要是因为以数据为中心的Python包的奇妙生态系统。 Pandas就是其中之一,它使导入和分析数据变得更加容易。
数据分析中最重要的是比较值并相应地选择数据。 “==”运算符也适用于 Pandas 数据框中的多个值。以下两个示例将展示如何比较和选择 Pandas 数据框中的数据。
要下载使用的 CSV 文件,请单击此处。
示例 #1:比较数据
在以下示例中,数据框由 csv 文件构成。在 Gender 列中,只有 3 种类型的值(“Male”、“Female”或 NaN)。性别列的每一行都与“男性”进行比较,然后返回一个布尔系列。
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("employees.csv")
# storing boolean series in new
new = data["Gender"] == "Male"
# inserting new series in data frame
data["New"]= new
# display
data
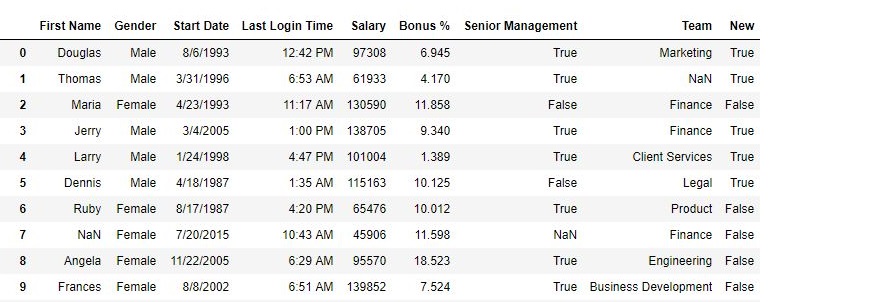
输出:
如输出图像所示,对于 Gender=“Male”,New Column 中的值为 True,对于“Female”和 NaN 值为 False。
 示例 #2:选择数据
示例 #2:选择数据
在以下示例中,布尔系列被传递给数据,并且仅返回 Gender=”Male” 的 Rows。
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("employees.csv")
# storing boolean series in new
new = data["Gender"] != "Female"
# inserting new series in data frame
data["New"]= new
# display
data[new]
# OR
# data[data["Gender"]=="Male"]
# Both are the same
输出:
如输出图像所示,返回 Gender=”Male” 的数据框。
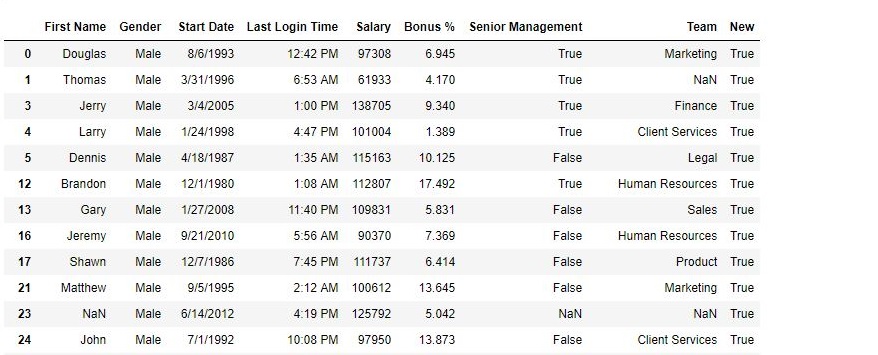
注意:对于 NaN 值,布尔值为 False。