使用 Pandas 操作数据帧 – Python
在使用 Pandas 操作数据框之前,我们必须了解什么是数据操作。现实世界中的数据是非常令人不快和无序的,因此通过执行某些操作,我们可以根据自己的要求使数据易于理解,这种将无序数据转换为有意义信息的过程可以通过数据操作来完成。
在这里,我们将学习如何使用 Pandas 操作数据帧。 Pandas 是一个开源库,用于从数据操作到数据分析,是非常强大、灵活且易于使用的工具,可以使用 import pandas as pd 进行导入。 Pandas 主要处理一维和二维数组中的数据;虽然,pandas 处理这两者的方式不同。在 Pandas 中,一维数组被表示为一个系列,而数据帧只是一个二维数组。这里使用的数据集是 country_code.csv。
以下是用于操作数据框的各种操作:
- 首先,导入用于数据操作的库,即pandas,然后分配并读取数据帧:
Python3
# import module
import pandas as pd
# assign dataset
df = pd.read_csv("country_code.csv")
# display
print("Type-", type(df))
dfPython3
df.head(10)Python3
df.shapePython3
df.describe()Python3
df.dropna()Python3
df.dropna(axis=1)Python3
df1 = pd.read_csv("country_code.csv")
merged_col = pd.merge(df, df1, on='Name')
merged_colPython3
country_code = df.rename(columns={'Name': 'CountryName',
'Code': 'CountryCode'},
inplace=False)
country_codePython3
student = pd.DataFrame({'Name': ['Rohan', 'Rahul', 'Gaurav',
'Ananya', 'Vinay', 'Rohan',
'Vivek', 'Vinay'],
'Score': [76, 69, 70, 88, 79, 64, 62, 57]})
# Reading Dataframe
studentPython3
student.sort_values(by=['Score'], ascending=True)Python3
student.sort_values(by=['Name', 'Score'],
ascending=[True, False])Python3
student['Percentage'] = (student['Score'] / student['Score'].sum()) * 100
studentPython3
# Selecting rows where score is
# greater than 70
print(student[student.Score>70])
# Selecting rows where score is greater than 60
# OR less than 70
print(student[(student.Score>60) | (student.Score<70)])Python3
# Printing five rows with name column only
# i.e. printing first 5 student names.
print(student.loc[0:4, 'Name'])
# Printing all the rows with score column
# only i.e. printing score of all the
# students
print(student.loc[:, 'Score'])
# Printing only first rows having name,
# score columns i.e. print first student
# name & their score.
print(student.iloc[0, 0:2])
# Printing first 3 rows having name,score &
# percentage columns i.e. printing first three
# student name,score & percentage.
print(student.iloc[0:3, 0:3])
# Printing all rows having name & score
# columns i.e. printing all student
# name & their score.
print(student.iloc[:, 0:2])Python3
# explicit function
def double(a):
return 2*a
student['Score'] = student['Score'].apply(double)
# Reading Dataframe
student输出:
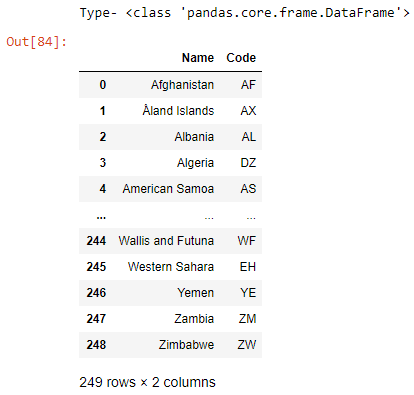
- 我们可以使用head()函数读取数据帧,该函数也有一个参数 (n),即要显示的行数。
蟒蛇3
df.head(10)
输出:
- 使用shape()计算 DataFrame 中的行和列。它返回编号。包含在元组中的行和列。
蟒蛇3
df.shape
输出:

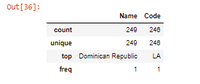
- 使用describe()方法的 DataFrame 统计摘要。
蟒蛇3
df.describe()
输出:
- 删除 DataFrame 中的缺失值,可以使用dropna()方法完成,它删除数据框中的所有 NaN 值。
蟒蛇3
df.dropna()
输出:
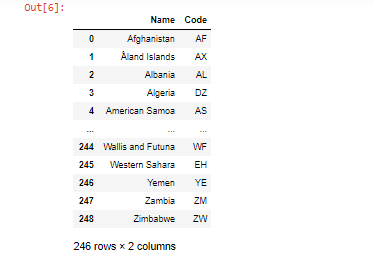
另一个例子是:
蟒蛇3
df.dropna(axis=1)
这将删除具有任何缺失值的所有列。
输出:
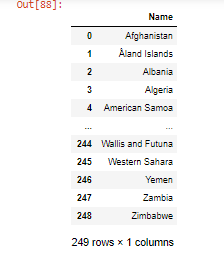
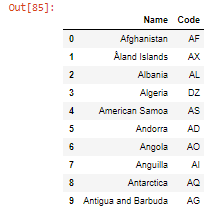
- 使用merge() 合并数据帧,传递的参数是要与列名称合并的数据帧。
蟒蛇3
df1 = pd.read_csv("country_code.csv")
merged_col = pd.merge(df, df1, on='Name')
merged_col
输出:
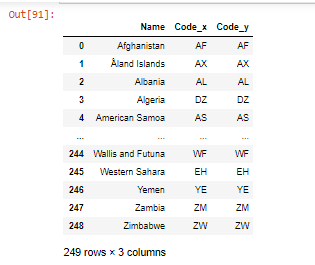
- 另一个参数 'on' 是公共列的名称,这里的 'Name' 是提供给 merge()函数的公共列。 df 是第一个数据帧,df1 是要合并的第二个数据帧。
- 使用rename() 重命名数据帧的列,传递的参数是要重命名和就地的列。
蟒蛇3
country_code = df.rename(columns={'Name': 'CountryName',
'Code': 'CountryCode'},
inplace=False)
country_code
输出:
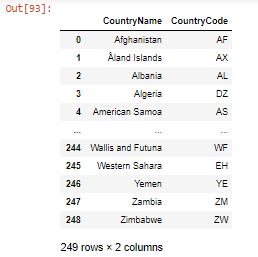
代码 'inplace = False' 意味着结果将存储在一个新的 DataFrame 而不是原来的 DataFrame 中。
- 手动创建数据框:
蟒蛇3
student = pd.DataFrame({'Name': ['Rohan', 'Rahul', 'Gaurav',
'Ananya', 'Vinay', 'Rohan',
'Vivek', 'Vinay'],
'Score': [76, 69, 70, 88, 79, 64, 62, 57]})
# Reading Dataframe
student
输出:
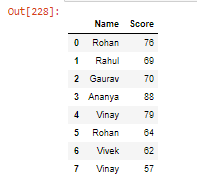
- 使用sort_values()方法对 DataFrame 进行排序。
蟒蛇3
student.sort_values(by=['Score'], ascending=True)
输出:
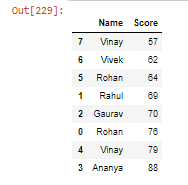
- 使用多列对 DataFrame 进行排序:
蟒蛇3
student.sort_values(by=['Name', 'Score'],
ascending=[True, False])
输出:
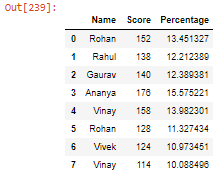
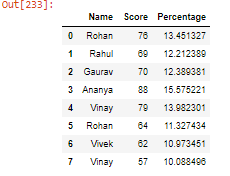
- 在 DataFrame 中创建另一列,这里我们将创建列名百分比,它将使用聚合函数sum() 计算学生分数的百分比。
蟒蛇3
student['Percentage'] = (student['Score'] / student['Score'].sum()) * 100
student
输出:
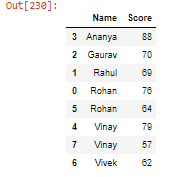
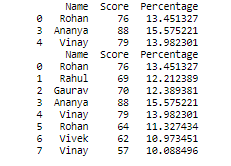
- 使用逻辑运算符选择 DataFrame 行:
蟒蛇3
# Selecting rows where score is
# greater than 70
print(student[student.Score>70])
# Selecting rows where score is greater than 60
# OR less than 70
print(student[(student.Score>60) | (student.Score<70)])
输出:
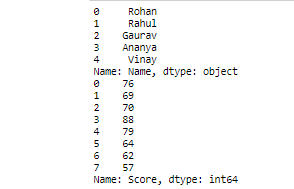
- 索引和切片:
这里.loc是标签库, .iloc是用于数据切片和索引的基于整数位置的方法。
蟒蛇3
# Printing five rows with name column only
# i.e. printing first 5 student names.
print(student.loc[0:4, 'Name'])
# Printing all the rows with score column
# only i.e. printing score of all the
# students
print(student.loc[:, 'Score'])
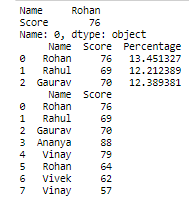
# Printing only first rows having name,
# score columns i.e. print first student
# name & their score.
print(student.iloc[0, 0:2])
# Printing first 3 rows having name,score &
# percentage columns i.e. printing first three
# student name,score & percentage.
print(student.iloc[0:3, 0:3])
# Printing all rows having name & score
# columns i.e. printing all student
# name & their score.
print(student.iloc[:, 0:2])
输出:
.loc:
.iloc:
- 应用功能,此函数用于数据帧沿的轴线应用一个函数可以不管它排(轴= 0)或柱(轴= 1)。
蟒蛇3
# explicit function
def double(a):
return 2*a
student['Score'] = student['Score'].apply(double)
# Reading Dataframe
student
输出: