Node.js 傀儡师
Puppeteer 是 Node.js 的一个开源库,它通过提供对开发人员工具的控制来帮助自动化和简化开发。它允许开发人员编写和维护简单的自动化测试。大多数在浏览器中手动完成的事情都可以通过使用 puppeteer 来完成。 Puppeteer 的特点是——
- 它可以作为 Web Srawler 工作。
- 它可以生成页面的屏幕截图。
- 它可以制作网页的PDF。
- 它可以自动化测试和表单提交的过程。
- 它可用于测试 Chrome 扩展。
- 它为测试创建了一个更新和自动化的环境,以便可以直接在浏览器(Google Chrome)中运行测试。
- 它创建自己的浏览器用户配置文件,每当运行此库时都会对其进行清理。
安装:第一步,使用package.json文件初始化应用程序。因此,运行以下命令 -
npm init要安装库,请编写以下命令 -
npm install puppeteer --save安装后,我们的 package.json 文件将如下所示——
{
"name": "day37",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "Pranjal Srivastava",
"license": "ISC",
"dependencies": {
"puppeteer": "^3.1.0"
}
}
实现: Puppeteer 基本上是创建浏览器的一个实例,然后操作浏览器的页面。让我们看看用于导航到网页的 puppeteer 的实现——
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.geeksforgeeks.org/');
await browser.close();
})();
首先,我们正在创建一个浏览器实例并允许 puppeteer 库启动。这里,
browser.newPage()用于创建一个新页面,然后导航到page.goto()作为参数提供的 URL。最后browser.close()用于关闭整个运行过程。我们的 javascript 文件的名称是index.js ,因此,要运行应用程序,只需在终端中键入以下命令 -
node index.js上面的代码将启动系统中的默认 Web 浏览器并导航到 https://www.geeksforgeeks.org/
截取网页截图:要截取网页截图,请编写以下代码 -
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.geeksforgeeks.org/');
await page.screenshot({ path: 'GFG.png' });
await browser.close();
})();
在这里, page.screenshot方法将截取页面的屏幕截图并将其保存为文件名GFG.png 。上面的代码会先打开页面,然后对页面进行截图。
使用命令运行应用程序 –
node index.js上述代码的输出将是 - 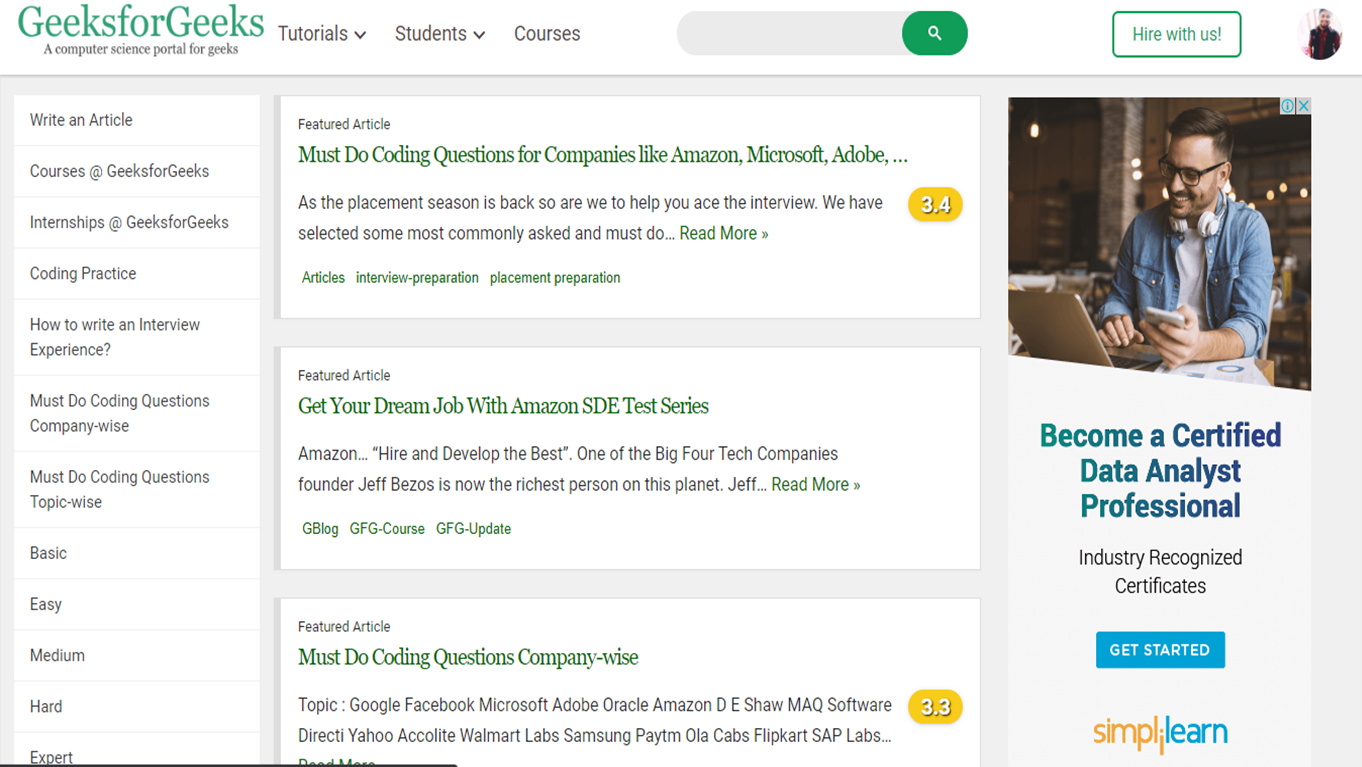
要为给定网站创建 PDF:要创建网站的 PDF,请编写以下代码 -
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.geeksforgeeks.org/');
await page.pdf({ path: 'gfg.pdf' });
await browser.close();
})();
在这里, page.pdf()将创建给定网站的 PDF 并将其保存为名称gfg.pdf 。使用命令运行应用程序 –
node index.js上面的代码将生成页面的 PDF。
上述代码的输出将是 - 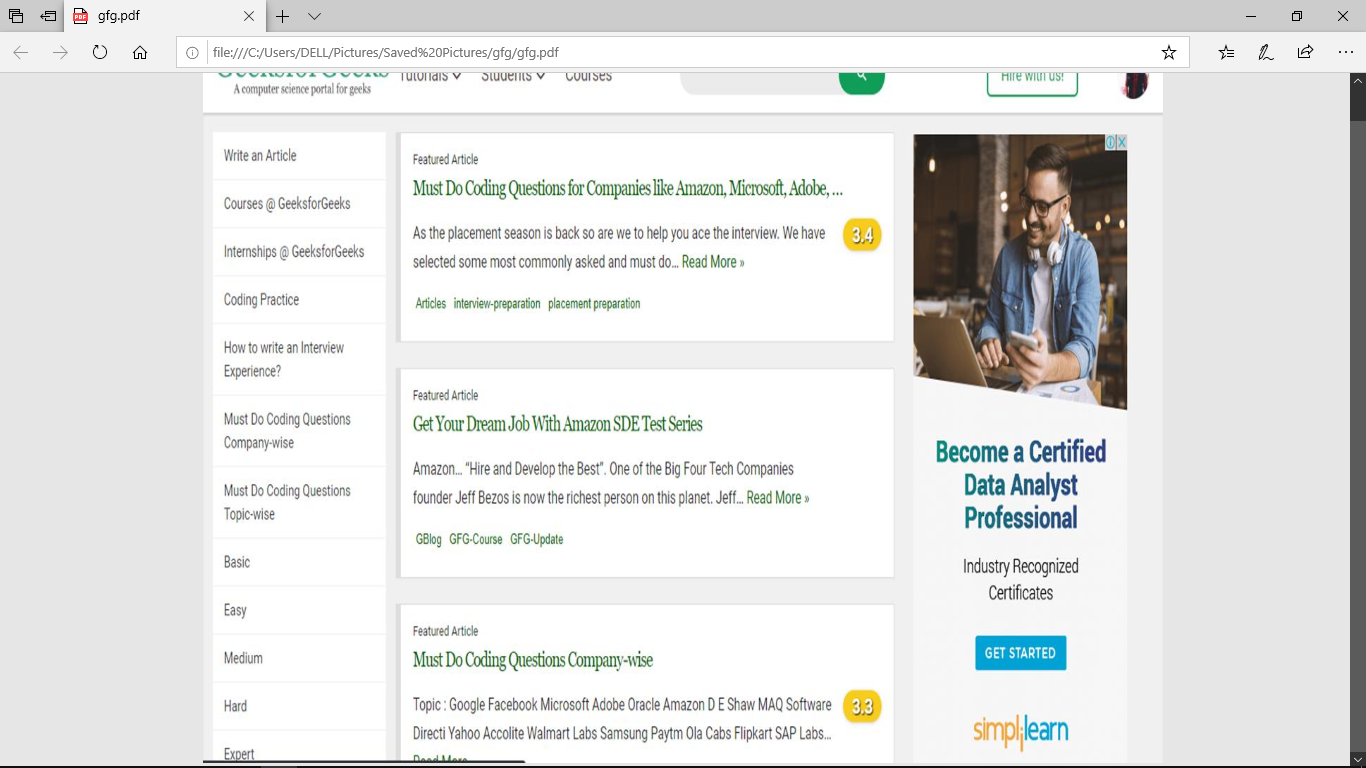
获取打开网页的尺寸:获取页面的尺寸,编写以下代码 -
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.geeksforgeeks.org/');
const getDimensions = await page.evaluate(() => {
return {
width: document.documentElement.clientWidth,
height: document.documentElement.clientHeight
};
});
console.log(getDimensions);
await browser.close();
})();
在这里, getDimensions将首先评估页面,然后返回页面的宽度和高度。属性clientWidth和clientHeight分别用于获取页面的宽度和高度。使用命令运行应用程序 –
node index.js上述代码的输出将是 -
{
width: 1366px,
height: 695px
}
默认设置:
- 它以无头模式运行:浏览器的无头模式提供自动化测试和服务器环境。这是一种在没有完整 GUI 的情况下运行浏览器的方式。在无头模式下使用浏览器的优点是它可以连续运行 javascript 测试。在 puppeteer 中,无头浏览器的默认设置为true 。要使其为假,请编写以下代码 -
const browser = await puppeteer.launch({ headless: false }) - 它运行特定版本的 Chrome:默认情况下,puppeteer 使用特定版本的 Chrome。如果要运行其他版本的代码,请编写以下内容 -
const browser = await puppeteer.launch({ executablePath: '/path/to/your/version/of/Chrome' });在这里, executablePath属性允许您指定您的 Chrome 版本的路径。
结论:在本文中,我们了解了 Node.js 的pupeteer库。我们还了解了这个库的各种特性。我们已经看到了它的实现和这个库使用的默认设置。