缓存遗忘算法
Cache oblivious是一种无需使用复杂的多级内存模型即可在任意内存层次结构中实现高效算法的方法。高速缓存遗忘算法是使用渐近最优工作量、在多级高速缓存之间渐近最优移动数据以及间接使用处理器高速缓存的算法。
本文重点讨论以下主题:
- 什么是缓存遗忘算法
- 缓存遗忘模型。
- 缓存无意识模型的证明。
- 为什么使用 Cache-Oblivious 算法?
- 高缓存假设。
- 缓存遗忘算法示例。
缓存无意识模型
缓存遗忘模型的构建方式使其可以独立于常量因素,例如缓存内存的大小。
特征:
- 它是为内存层次结构设计的,它根据响应时间将计算机存储分成一个层次结构。缓存遗忘算法只有在忽略常数因素时才是渐近的。
- 缓存无意识的概念是设计缓存效率和磁盘效率的算法和数据结构。
- Cache-oblivious 算法在不知道层次结构的任何参数的情况下在多级内存层次结构上表现良好,但要知道它们的存在。这意味着他们只需要忽略恒定因素即可有效地工作。
- 实现缓存忽略算法的方法有很多,其中一种是通过矩阵转置,然后通过各种排序方法对其进行排序。
模型的合理性
缓存无意识模型可以基于以下几点来证明:
外部存储器模型
- 下面显示的模型具有2 级内存层次结构,由缓存 (Z) 和在缓存和磁盘之间传输的数据块 (B) 组成。磁盘被分成 B 元素块,访问磁盘上的其中一个元素,将其整个块复制到缓存中。
- 缓存非常靠近 CPU 并且空间有限,磁盘远离 CPU 并且在技术上访问成本很高,这被称为缓存成本。而且它有很大的空间。
- 访问时间在缓存和磁盘之间有很大的不同。读操作背后的总体思路是读取之前存储的数据。并且写操作在内存中存储一个新值。但是当 CPU 或处理器访问一个内存位置时,如果该数据块已经在缓存中,那么它被称为缓存命中,访问它的缓存成本为 0。如果它不在缓存中已经,那么它是缓存未命中。然后从磁盘访问该内存并将其传输到缓存 (Z)。在这种情况下,缓存成本将为 1。

关联缓存:
- 缓存通常由三个因素来区分-
- 关联性(A)-关联性A指定编号。不同的帧或行(B)驻留在主存储器中。如果来自主存储器(磁盘)的块可以驻留在任何帧或行中,则完全满足关联性。
- Block(B) -块是最小内存访问大小的一部分。
- 容量(C)-容量是最小内存访问大小的一部分。
- 一个缓存等于C字节。但是由于物理强制,缓存被分成大小为B的缓存帧。这些因素会对特定的缓存产生影响。
- 当内存地址不在缓存中时( cache-miss ),我们必须将一个块或行带到缓存中,它应该决定它应该映射到缓存中的哪个位置。缓存模型假定任何缓存行或块都可以映射到缓存内存中的任何位置。大多数高速缓存是 2 路、4 路、8 路、16 路关联的。
- 什么是集合关联映射?
- 它是特定主内存块(在我们的例子中是磁盘)到缓存集的映射。当发生缓存未命中时会发生这种情况。
- 高速缓存行被组装成集合,其中每个集合包含k行。
- 然后,将一块主存映射到一组缓存。我们可以从主内存映射到任何免费可用的缓存行。
- 唯一的主内存可以映射到的缓存集由下式给出:
Cache set number = [Main Memory block address] modulo [number of sets in the cache]
最优缓存替换策略:
- 当发生高速缓存未命中时,一条新的高速缓存行从主存储器映射到高速缓存。
- 但如果缓存已满,则在从主内存中获取块之前,必须有一种方法可以将当前存在的行从缓存中逐出。现实中没有最优的替代,因为它需要我们知道未来的缓存未命中,这是不可预测的。尽管如此,最优缓存替换策略可以与实际策略相似,并且可以使用 Bélády 算法、先进先出 (FIFO)、后进先出 (LIFO)、最近最少使用 (LRU) 等算法更可预测。
为什么使用 Cache-Oblivious 算法?
- 发明了缓存忽略模型,以便数据结构可以反映缓存意识的某些属性。
- Cache oblivious 算法继承了寄存器机的一些特性,通常由少量的快速存储和随机存取机模型组成。
- 但他们有自己的分歧。寄存器是计算机系统的处理器可用的不断访问的位置。它们由快速存储的小记忆组成。当计算机将数据从相当大的内存加载到寄存器中以进行算术运算时,就会使用这些小内存。
- 缓存无意识者具有缓存意识是有原因的。即因为通过缓存无意识模型检查的缓存存储器的层次结构。
- 将所有这些结合在一起的原则是在不知道缓存大小和缓存中的块的情况下设计外部存储器算法。
高缓存假设
理想的缓存模型是一个假设,其中有一个称为“tall cache”的假设,用于计算算法的缓存复杂度。这个断言有一个数学方程——
Z = Ω(B2)
Here,
Z is the size of the cache.
B is the size of the cache line.
Ω symbol is used to represent the lower bound of the algorithm or data. And that is the top speed any algorithm can get to.
Cache-Oblivious 算法示例
1. 数组反转:
- 数组反转是在没有任何额外存储的情况下反转数组中的元素。 Bentley 的阵列反转算法从两侧构造两个平行扫描,每个扫描来自阵列的相对端。在每一次扫描或每一步中,这两个元素都会相互交换它们的位置。
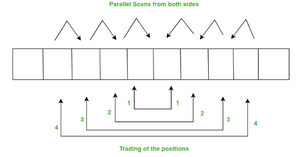
- 好处:
- cache-oblivious 算法使用与单次扫描相同数量的内存读取。
- 该算法通过按存储顺序逐个扫描元素来帮助实现 N 元素遍历。
- 局限性:
- 当数据存入主存储器时,这些算法的性能比基于 RAM 和缓存感知算法的性能差。
2.矩阵转置:
- 矩阵转置定义如下。给定存储在行优先布局中的 m × n 矩阵,我们必须计算 A T (A Transpose) 并将其存储到同样存储在行优先布局中的 n × m 矩阵 B 中。
- 使用双重嵌套循环的直接转置算法会在其中一个矩阵上导致 Θ(mn) 缓存未命中。缓存未命中背后的原因是矩阵的大小增加。
- 缓存未命中是由于一个块从主内存加载到缓存中的结果。
- 可以通过分而治之的策略获得最佳工作和缓存复杂性,但是,
If n >= m,
we partition
A = (A1, A2),
B = (B1, B2) - 然后,重复执行 TRANSPOSE (A1, B1) 和 TRANSPOSE (A2, B2)。类似地,如果 m > n,我们将矩阵 A 水平划分,矩阵 B 垂直划分,同样重复执行两次转置。
- 好处:
- 当矩阵以行或列优先顺序存储时,矩阵转置的迭代算法会导致 anxn 矩阵上的 Ω(n 2 ) 缓存未命中,其因子 Θ(B) 显然比缓存有更多的缓存未命中 -最优算法。
- 局限性:
- 尽管在 RAM 模型中是最优的并且不考虑缓存,但这些算法在缓存未命中方面并不是渐近最优的。
3、二叉搜索树(分治算法):
- 分而治之算法递归地提取问题大小。稍后,数据适合缓存(M),最终,数据将适合单个块或缓存行。分析过程考虑数据适合缓存并适合缓存行的确切时间。令人惊讶的是,它证明了在这些情况下内存传输的数量更少。
- 分治算法的一个很好的例子是二叉树。
- 在二叉树中,每棵树都有一个子树,左或右,即递归树中的每个节点只有一个分支,通常称为分而治之的退化形式。
- 在这种情况下,每个叶子的成本由根节点的成本平衡,这使我们在每个节点处具有相同级别的递归。
- 好处:
- 根据 Van Emde Boas 的布局,具有标记为特定位置的节点的二叉搜索树需要更少的递归级别。
- 局限性:
- cache-oblivious 数据结构归因于 Benders 集,它使用二叉树作为索引数据结构来有效地找到给定值的后继元素。在执行时间和内存使用方面都发现它最差。
4.合并排序:
- 将数据按一定顺序定位通常称为排序。在外部存储器算法中,排序同时显示下限和上限。在他们的论文中,Aggarwal 和 Vitter 证明了一种在比较模型中对内存传输次数进行排序的方法,即
Θ( N /B [logM/B N/ B ])
- (M/B) 合并排序是外部存储器算法排序以达到 Aggarwal 和 Vitter 界的方式。要理解 cache-oblivious 上下文,首先,我们需要看一下外部存储器算法。在合并过程中,每个数据块都维护着每个列表的前B个元素;当一个块是空的时,列表中的下一个块被加载到其中。因此,合并需要 Θ(N/B) 内存传输来建设性地扫描内存。
The total no. of memory transfers for this kind of sorting algorithm would be: T(N) = M/B T(N/ M/B) + Θ(N/B)
The recursion tree has Θ(N/B) leaves,for a leaf cost of Θ(N/B)
The number of levels in the recursion tree is logM/B N, so the total cost is Θ(N/B logM/B N/B) - 递归树不过是二叉搜索树。
- 现在,在缓存忽略条件下,使用的完美算法是经典的 2 路归并排序,但随后递归变为
T(N) = 2T(N/2) + Θ(N/B)
- 好处:
- 缓存遗忘方法允许使用 2 路合并排序比外部存储器算法更有效。
- 比较模型中要排序的内存传输次数为 Θ(N/B log M/B N/B)。
- 局限性:
- 对于输入大小为 n 的合并排序维持 Ω((n/B) lg(n/Z)) 缓存未命中,这是比缓存优化算法多 Θ(lg Z) 的缓存未命中的因子。因此,归并排序本身并不是缓存优化算法。
参考
- 缓存不经意的算法和数据结构。 Erik D. Demaine (麻省理工学院计算机科学实验室)
- 算法的缓存感知分析
- 计算机科学中的缓存意识编程。 DOI:10.1145/384266.299772。
- 缓存无意识数据结构的评估 Maks Verver
- Harald Prokop 的 Cache-Oblivious 算法