众所周知,合并排序比插入排序运行得更快。使用渐近分析,我们可以证明合并排序以O(nlogn)的时间运行,而插入排序则需要O(n ^ 2)。很明显,因为合并排序通过递归解决插入排序遵循增量方法的问题而使用了分而治之的方法。
如果进一步检查时间复杂度分析,我们将知道插入排序还不够糟糕。令人惊讶的是,插入排序优先于较小的输入大小而合并排序。这是因为在推导时间复杂度时几乎没有常量可以忽略。在10 ^ 4量级的较大输入大小上,这不会影响我们函数的行为。但是,当输入大小低于(例如小于40)时,则方程式中的常数将决定输入大小’n’。
到现在为止还挺好。但是我对这样的数学分析不满意。作为计算机科学的本科生,我们必须相信编写代码。我编写了一个C程序,以了解算法如何针对各种输入大小相互竞争。而且,为什么要在建立这些排序算法的运行时间复杂度时进行如此严格的数学分析。
执行:
//C++ code to compare performance of sorting algorithms
#include
#include
#include
#include
#define MAX_ELEMENT_IN_ARRAY 1000000001
int cmpfunc (const void * a, const void * b)
{
// Compare function used by qsort
return ( *(int*)a - *(int*)b );
}
int* generate_random_array(int n)
{
srand(time(NULL));
int *a = malloc(sizeof(int) * n), i;
for(i = 0; i < n; ++i)
a[i] = rand() % MAX_ELEMENT_IN_ARRAY;
return a;
}
int* copy_array(int a[], int n)
{
int *arr = malloc(sizeof(int) * n);
int i;
for(i = 0; i < n ;++i)
arr[i] = a[i];
return arr;
}
//Code for Insertion Sort
void insertion_sort_asc(int a[], int start, int end)
{
int i;
for(i = start + 1; i <= end ; ++i)
{
int key = a[i];
int j = i - 1;
while(j >= start && a[j] > key)
{
a[j + 1] = a[j];
--j;
}
a[j + 1] = key;
}
}
//Code for Merge Sort
void merge(int a[], int start, int end, int mid)
{
int i = start, j = mid + 1, k = 0;
int *aux = malloc(sizeof(int) * (end - start + 1));
while(i <= mid && j <= end)
{
if(a[i] <= a[j])
aux[k++] = a[i++];
else
aux[k++] = a[j++];
}
while(i <= mid)
aux[k++] = a[i++];
while(j <= end)
aux[k++] = a[j++];
j = 0;
for(i = start;i <= end;++i)
a[i] = aux[j++];
free(aux);
}
void _merge_sort(int a[],int start,int end)
{
if(start < end)
{
int mid = start + (end - start) / 2;
_merge_sort(a,start,mid);
_merge_sort(a,mid + 1,end);
merge(a,start,end,mid);
}
}
void merge_sort(int a[],int n)
{
return _merge_sort(a,0,n - 1);
}
void insertion_and_merge_sort_combine(int a[], int start, int end, int k)
{
// Performs insertion sort if size of array is less than or equal to k
// Otherwise, uses mergesort
if(start < end)
{
int size = end - start + 1;
if(size <= k)
{
//printf("Performed insertion sort- start = %d and end = %d\n", start, end);
return insertion_sort_asc(a,start,end);
}
int mid = start + (end - start) / 2;
insertion_and_merge_sort_combine(a,start,mid,k);
insertion_and_merge_sort_combine(a,mid + 1,end,k);
merge(a,start,end,mid);
}
}
void test_sorting_runtimes(int size,int num_of_times)
{
// Measuring the runtime of the sorting algorithms
int number_of_times = num_of_times;
int t = number_of_times;
int n = size;
double insertion_sort_time = 0, merge_sort_time = 0;
double merge_sort_and_insertion_sort_mix_time = 0, qsort_time = 0;
while(t--)
{
clock_t start, end;
int *a = generate_random_array(n);
int *b = copy_array(a,n);
start = clock();
insertion_sort_asc(b,0,n-1);
end = clock();
insertion_sort_time += ((double) (end - start)) / CLOCKS_PER_SEC;
free(b);
int *c = copy_array(a,n);
start = clock();
merge_sort(c,n);
end = clock();
merge_sort_time += ((double) (end - start)) / CLOCKS_PER_SEC;
free(c);
int *d = copy_array(a,n);
start = clock();
insertion_and_merge_sort_combine(d,0,n-1,40);
end = clock();
merge_sort_and_insertion_sort_mix_time+=((double) (end - start))/CLOCKS_PER_SEC;
free(d);
start = clock();
qsort(a,n,sizeof(int),cmpfunc);
end = clock();
qsort_time += ((double) (end - start)) / CLOCKS_PER_SEC;
free(a);
}
insertion_sort_time /= number_of_times;
merge_sort_time /= number_of_times;
merge_sort_and_insertion_sort_mix_time /= number_of_times;
qsort_time /= number_of_times;
printf("\nTime taken to sort:\n"
"%-35s %f\n"
"%-35s %f\n"
"%-35s %f\n"
"%-35s %f\n\n",
"(i)Insertion sort: ",
insertion_sort_time,
"(ii)Merge sort: ",
merge_sort_time,
"(iii)Insertion-mergesort-hybrid: ",
merge_sort_and_insertion_sort_mix_time,
"(iv)Qsort library function: ",
qsort_time);
}
int main(int argc, char const *argv[])
{
int t;
scanf("%d", &t);
while(t--)
{
int size, num_of_times;
scanf("%d %d", &size, &num_of_times);
test_sorting_runtimes(size,num_of_times);
}
return 0;
}
我已经比较了以下算法的运行时间:
- 插入排序:没有修改/优化的传统算法。对于较小的输入大小,它的性能很好。是的,它确实优于合并排序
- 合并排序:遵循分而治之的方法。对于10 ^ 5量级的输入大小,此算法是正确的选择。对于如此大的输入大小,它使插入排序变得不切实际。
- 插入排序和合并排序的组合版本:我对合并排序的逻辑进行了一些调整,以在较小的输入大小下获得明显更长的运行时间。众所周知,归并排序将其输入分为两半,直到对元素进行排序变得微不足道。但是在这里,当输入大小降到阈值(例如’n'<40)以下时,此混合算法将调用传统的插入排序过程。由于插入排序在较小的输入上运行更快,合并排序在较大的输入上运行更快的事实,因此该算法可以最好地利用这两个世界。
- 快速排序:我尚未执行此过程。这是库函数qsort(),可在
。为了了解实现的重要性,我考虑了该算法。它需要大量的编程专业知识,以最大程度地减少步骤数量,并最多利用底层语言原语来以最佳方式实现算法。这是建议使用库函数的主要原因。它们被编写为处理任何事情。它们最大程度地进行了优化。在我忘记之前,根据我的分析,qsort()几乎可以在任何输入大小上快速运行!
分析:
- 输入:用户必须提供他/她想要测试与测试案例数量相对应的算法的次数。对于每个测试用例,用户必须输入两个空格分隔的整数,分别表示输入大小“ n”和“ num_of_times”,该整数表示他/她想要运行分析并取平均值的次数。 (澄清:如果’num_of_times’为10,则上面指定的每个算法都会运行10次并取平均值。之所以这样做,是因为输入数组是根据您指定的输入大小随机生成的。输入数组可以是全部我们可以将其对应于最坏的情况,即降序。为了避免此类输入数组的运行时间。算法运行“ num_of_times”,并取平均值。)
clock()例程和来自的CLOCKS_PER_SEC宏用于测量所花费的时间。
编译:我已经在Linux环境(Ubuntu 16.04 LTS)中编写了以上代码。复制上面的代码段。使用gcc进行编译,输入指定的内容并欣赏排序算法的强大功能!- 结果:如您所见,对于较小的输入大小,插入排序节拍会以2 * 10 ^ -6秒的时间合并排序。但是这种时间上的差异不是很明显。另一方面,混合算法和qsort()库函数均与插入排序一样好。
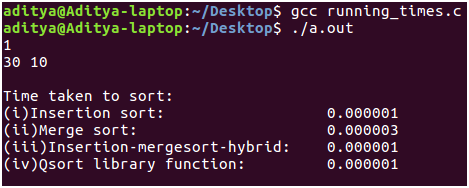
现在,输入大小从n = 30增加了大约100倍,达到n = 1000。合并排序的运行速度比插入排序快10倍。混合算法的性能与qsort()例程之间仍然存在联系。这表明qsort()的实现方式与我们的混合算法或多或少相似,即在不同算法之间切换以充分利用它们。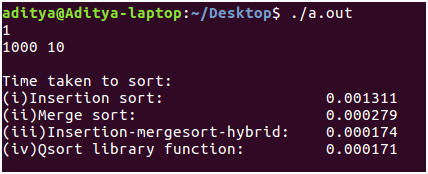
最后,输入大小增加到10 ^ 5(1 Lakh!),这很可能是实际方案中使用的理想大小。与之前的输入n = 1000相比(合并排序比插入排序快10倍),这里的差异甚至更大。合并排序比插入排序高100倍!
实际上,我们编写的混合算法通过运行0.01秒来完成传统的合并排序。最后,库函数qsort()最终向我们证明了实现也起着至关重要的作用,同时通过更快地运行3毫秒来精确测量运行时间! 😀 - 结果:如您所见,对于较小的输入大小,插入排序节拍会以2 * 10 ^ -6秒的时间合并排序。但是这种时间上的差异不是很明显。另一方面,混合算法和qsort()库函数均与插入排序一样好。
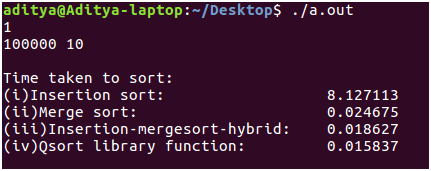
注意:不要在n> = 10 ^ 6的情况下运行上述程序,因为这会占用大量计算能力。谢谢您,祝您编码愉快! 🙂