毫升 | K-Means 中的随机初始化陷阱
随机初始化陷阱是K-means算法中出现的一个问题。在随机初始化陷阱中,当要生成的集群的质心由用户明确定义时,可能会产生不一致,这有时可能导致在数据集中生成错误的集群。所以随机初始化陷阱有时可能会阻止我们开发正确的集群。
例子 :
假设你有一个数据集,如图所示,你想通过 K-means 聚类,根据它们的属性在这个数据集中生成三个簇。从图中,我们可以直观地了解需要生成哪些簇。 K-means 将根据输入算法的质心进行聚类,并根据这些质心生成所需的聚类。

初审
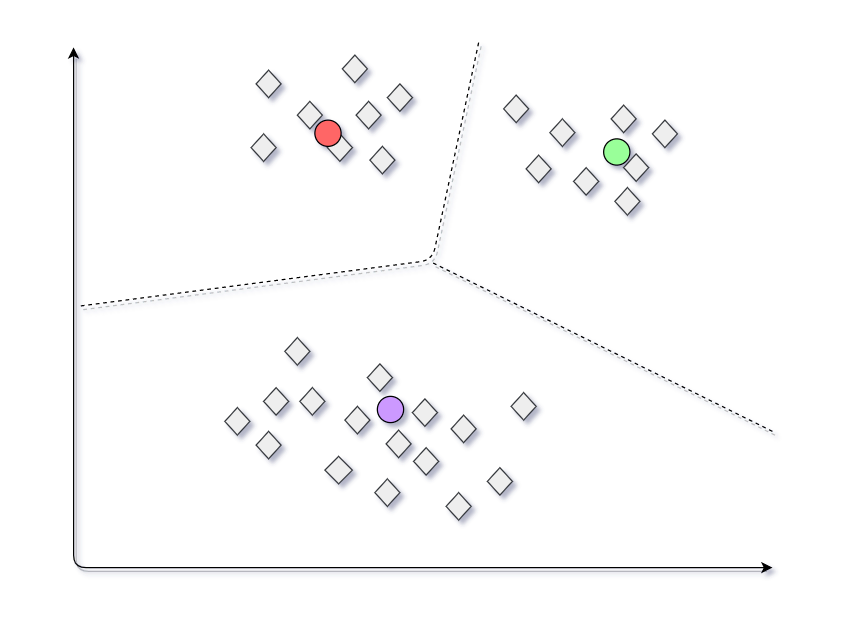
假设我们按照下图选择3组质心。与这些质心对应生成的簇如下图所示。

最终模型

二审
考虑另一种情况,我们为数据集选择另一组质心,如图所示。现在生成的集群集合将不同于之前实践中生成的集群。
最终模型

同样,我们可能会在同一数据集上获得不同的模型输出。当向 K-means 算法提供一组不同的质心使其不一致且不可靠时,会生成一组不同的簇,这种情况称为随机初始化陷阱。