- 自然语言工具包-标记文本(1)
- 自然语言工具包-标记文本
- 自然语言工具包-组合标记
- 自然语言工具包-组合标记(1)
- 自然语言工具包-转换树
- 自然语言工具包-转换块
- 自然语言工具包教程
- 自然语言工具包教程(1)
- 自然语言工具包-简介(1)
- 自然语言工具包-简介
- 讨论自然语言工具包(1)
- 讨论自然语言工具包
- 自然语言工具包-解析
- 自然语言工具包-解析(1)
- 自然语言工具包-入门(1)
- 自然语言工具包-入门
- 自然语言工具包-单词替换(1)
- 自然语言工具包-单词替换
- 自然语言工具包-文本分类
- 自然语言工具包-文本分类(1)
- 自然语言工具包-有用的资源(1)
- 自然语言工具包-有用的资源
- 工具包 (1)
- 工具包 - 任何代码示例
- 自然语言处理 |退避标记以组合标记器(1)
- 自然语言处理 |退避标记以组合标记器
- 自然语言工具包-Unigram Tagger(1)
- 自然语言工具包-Unigram Tagger
- 自然语言处理 |基于分类器的标记
📅 最后修改于: 2020-10-14 09:24:10 🧑 作者: Mango
词缀匕首
ContextTagger子类的另一个重要类是AffixTagger。在AffixTagger类中,上下文是单词的前缀或后缀。这就是AffixTagger类可以基于单词开头或结尾的固定长度子字符串学习标签的原因。
它是如何工作的?
它的工作取决于名为affix_length的参数,该参数指定前缀或后缀的长度。默认值为3。但是如何区分AffixTagger类学习单词的前缀还是后缀?
-
affix_length = positive-如果affix_lenght的值为正,则意味着AffixTagger类将学习单词的前缀。
-
affix_length = negative-如果affix_lenght的值为负,则意味着AffixTagger类将学习单词的后缀。
为了更清楚一点,在下面的示例中,我们将在带标签的树库句子上使用AffixTagger类。
例
在此示例中,AffixTagger将学习单词的前缀,因为我们没有为affix_length参数指定任何值。该参数将采用默认值3-
from nltk.tag import AffixTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Prefix_tagger = AffixTagger(train_sentences)
test_sentences = treebank.tagged_sents()[1500:]
Prefix_tagger.evaluate(test_sentences)
输出
0.2800492099250667
让我们在下面的示例中看到,当我们为affix_length参数提供值4时,精度将是多少-
from nltk.tag import AffixTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Prefix_tagger = AffixTagger(train_sentences, affix_length=4 )
test_sentences = treebank.tagged_sents()[1500:]
Prefix_tagger.evaluate(test_sentences)
输出
0.18154947354966527
例
在此示例中,AffixTagger将学习单词的后缀,因为我们将为affix_length参数指定负值。
from nltk.tag import AffixTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Suffix_tagger = AffixTagger(train_sentences, affix_length = -3)
test_sentences = treebank.tagged_sents()[1500:]
Suffix_tagger.evaluate(test_sentences)
输出
0.2800492099250667
布里尔塔格
Brill Tagger是基于转换的标记器。 NLTK提供BrillTagger类,这是第一个不是SequentialBackoffTagger子类的标记器。与之相反, BrillTagger使用了一系列规则来纠正初始标记器的结果。
它是如何工作的?
要使用BrillTaggerTrainer训练BrillTagger类,我们定义以下函数-
def train_brill_tagger(initial_tagger,train_sentences,** kwargs) –
templates = [
brill.Template(brill.Pos([-1])),
brill.Template(brill.Pos([1])),
brill.Template(brill.Pos([-2])),
brill.Template(brill.Pos([2])),
brill.Template(brill.Pos([-2, -1])),
brill.Template(brill.Pos([1, 2])),
brill.Template(brill.Pos([-3, -2, -1])),
brill.Template(brill.Pos([1, 2, 3])),
brill.Template(brill.Pos([-1]), brill.Pos([1])),
brill.Template(brill.Word([-1])),
brill.Template(brill.Word([1])),
brill.Template(brill.Word([-2])),
brill.Template(brill.Word([2])),
brill.Template(brill.Word([-2, -1])),
brill.Template(brill.Word([1, 2])),
brill.Template(brill.Word([-3, -2, -1])),
brill.Template(brill.Word([1, 2, 3])),
brill.Template(brill.Word([-1]), brill.Word([1])),
]
trainer = brill_trainer.BrillTaggerTrainer(initial_tagger, templates, deterministic=True)
return trainer.train(train_sentences, **kwargs)
如我们所见,此函数需要initial_tagger和train_sentences 。它带有initial_tagger参数和模板列表,这些模板实现了BrillTemplate接口。 BrillTemplate接口位于nltk.tbl.template模块中。这种实现之一是brill.Template类。
基于转换的标记器的主要作用是生成转换规则,以更正初始标记器的输出,使其更符合训练语句。让我们看看下面的工作流程-
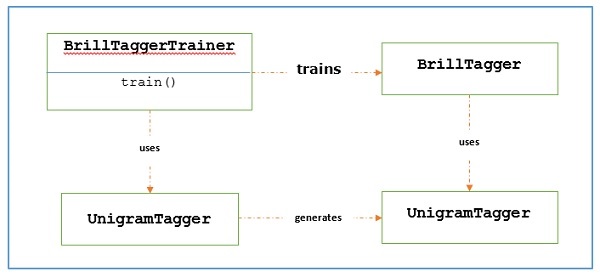
例
对于这个例子,我们将使用其中我们同时从NgramTagger类的退避链精梳标注器(在前面的配方),作为initial_tagger创建combine_tagger。首先,让我们使用Combine.tagger评估结果,然后将其用作initial_tagger来训练Brill Tagger。
from tagger_util import backoff_tagger
from nltk.tag import UnigramTagger
from nltk.tag import BigramTagger
from nltk.tag import TrigramTagger
from nltk.tag import DefaultTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
back_tagger = DefaultTagger('NN')
Combine_tagger = backoff_tagger(
train_sentences, [UnigramTagger, BigramTagger, TrigramTagger], backoff = back_tagger
)
test_sentences = treebank.tagged_sents()[1500:]
Combine_tagger.evaluate(test_sentences)
输出
0.9234530029238365
现在,让我们看看将Combine_tagger用作initial_tagger来训练brill tagger时的评估结果-
from tagger_util import train_brill_tagger
brill_tagger = train_brill_tagger(combine_tagger, train_sentences)
brill_tagger.evaluate(test_sentences)
输出
0.9246832510505041
我们可以看到,BrillTagger类有超过Combine_tagger略有提高精度。
完整的实施示例
from tagger_util import backoff_tagger
from nltk.tag import UnigramTagger
from nltk.tag import BigramTagger
from nltk.tag import TrigramTagger
from nltk.tag import DefaultTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
back_tagger = DefaultTagger('NN')
Combine_tagger = backoff_tagger(train_sentences,
[UnigramTagger, BigramTagger, TrigramTagger], backoff = back_tagger)
test_sentences = treebank.tagged_sents()[1500:]
Combine_tagger.evaluate(test_sentences)
from tagger_util import train_brill_tagger
brill_tagger = train_brill_tagger(combine_tagger, train_sentences)
brill_tagger.evaluate(test_sentences)
输出
0.9234530029238365
0.9246832510505041
TnT匕首
TnT Tagger代表Trigrams’nTags,是基于二阶马尔可夫模型的统计标记器。
它是如何工作的?
我们可以通过以下步骤来了解TnT标记器的工作方式-
-
首先基于训练数据,TnT触发程序将维护多个内部FreqDist和ConditionalFreqDist实例。
-
在这些字母组合之后,将通过这些频率分布来计算二字组和三字组。
-
现在,在标记过程中,它将通过使用频率来计算每个单词可能标记的概率。
这就是为什么它没有构造NgramTagger的补偿链,而是将所有ngram模型一起使用来为每个单词选择最佳标签。在以下示例中,让我们使用TnT标记器评估准确性-
from nltk.tag import tnt
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
tnt_tagger = tnt.TnT()
tnt_tagger.train(train_sentences)
test_sentences = treebank.tagged_sents()[1500:]
tnt_tagger.evaluate(test_sentences)
输出
0.9165508316157791
与使用Brill Tagger相比,我们的准确性稍差一些。
请注意,我们需要调用列车()之前评估(),否则,我们将获得0%的准确率。