- 自然语言工具包-转换树
- 自然语言工具包-转换块
- 自然语言工具包教程
- 自然语言工具包教程(1)
- 自然语言工具包-简介
- 自然语言工具包-简介(1)
- 讨论自然语言工具包
- 讨论自然语言工具包(1)
- 更多自然语言工具包标记(1)
- 更多自然语言工具包标记
- 自然语言工具包-入门(1)
- 自然语言工具包-入门
- 自然语言工具包-标记文本
- 自然语言工具包-标记文本(1)
- 自然语言工具包-单词替换
- 自然语言工具包-单词替换(1)
- 自然语言工具包-文本分类
- 自然语言工具包-文本分类(1)
- 自然语言工具包-有用的资源(1)
- 自然语言工具包-有用的资源
- 自然语言工具包-组合标记(1)
- 自然语言工具包-组合标记
- 工具包 (1)
- 工具包 - 任何代码示例
- 自然语言工具包-Unigram Tagger
- 自然语言工具包-Unigram Tagger(1)
- 自然语言编程
- 自然语言处理 |使用正则表达式进行部分解析(1)
- 自然语言处理 |使用正则表达式进行部分解析
📅 最后修改于: 2020-10-14 09:25:13 🧑 作者: Mango
解析及其在NLP中的相关性
源自拉丁语单词“ pars” (意为“ part” )的单词“ Parsing”用于从文本中得出确切含义或字典含义。也称为语法分析或语法分析。比较形式语法的规则,语法分析检查文本的意义。例如,诸如“给我热冰淇淋”之类的句子将被解析器或语法分析器拒绝。
从这个意义上讲,我们可以定义解析或语法分析或语法分析,如下所示:
可以将其定义为分析自然语言中符合形式语法规则的符号字符串的过程。
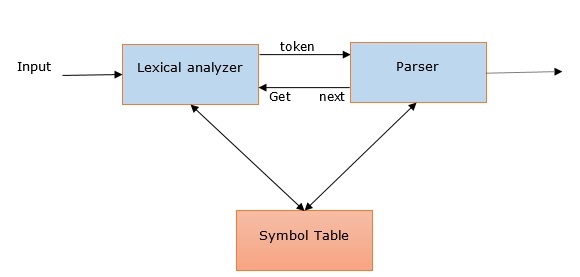
我们可以通过以下几点来理解NLP中解析的相关性-
-
解析器用于报告任何语法错误。
-
它有助于从常见错误中恢复,以便可以继续处理程序的其余部分。
-
解析树是在解析器的帮助下创建的。
-
解析器用于创建符号表,它在NLP中起着重要的作用。
-
解析器还用于生成中间表示(IR)。
深度VS浅解析
| Deep Parsing | Shallow Parsing |
|---|---|
| In deep parsing, the search strategy will give a complete syntactic structure to a sentence. | It is the task of parsing a limited part of the syntactic information from the given task. |
| It is suitable for complex NLP applications. | It can be used for less complex NLP applications. |
| Dialogue systems and summarization are the examples of NLP applications where deep parsing is used. | Information extraction and text mining are the examples of NLP applications where deep parsing is used. |
| It is also called full parsing. | It is also called chunking. |
各种类型的解析器
正如讨论的那样,解析器基本上是语法的过程解释。在搜索各种树木的空间后,它会为给定的句子找到最佳的树木。让我们在下面看到一些可用的解析器-
递归下降解析器
递归下降解析是最直接的解析形式之一。以下是关于递归下降解析器的一些要点-
-
它遵循自上而下的过程。
-
它试图验证输入流的语法是否正确。
-
它从左到右读取输入的句子。
-
递归下降解析器的一项必要操作是从输入流中读取字符,并将其与语法中的终端匹配。
移位减少解析器
以下是有关移位减少解析器的一些要点-
-
它遵循一个简单的自下而上的过程。
-
它试图找到与语法产品右侧相对应的单词和短语序列,并将其替换为产品左侧的单词和短语。
-
上面寻找单词序列的尝试一直持续到整个句子减少为止。
-
换句话说,shift-reduce解析器从输入符号开始,并尝试构造解析器树直至起始符号。
图表解析器
以下是关于图表解析器的一些要点-
-
它主要用于或适用于模棱两可的语法,包括自然语言的语法。
-
它将动态编程应用于解析问题。
-
由于采用动态编程,因此将部分假设的结果存储在称为“图表”的结构中。
-
“图表”也可以重复使用。
正则表达式解析器
正则表达式解析是最常用的解析技术之一。以下是有关Regexp解析器的一些要点-
-
顾名思义,它在POS标记的字符串的顶部使用以语法形式定义的正则表达式。
-
它基本上使用这些正则表达式来解析输入语句并由此生成一个解析树。
例
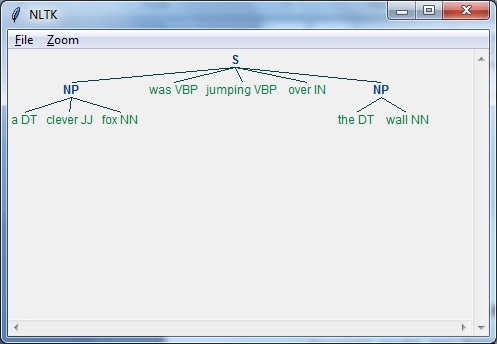
以下是Regexp解析器的工作示例-
import nltk
sentence = [
("a", "DT"),
("clever", "JJ"),
("fox","NN"),
("was","VBP"),
("jumping","VBP"),
("over","IN"),
("the","DT"),
("wall","NN")
]
grammar = "NP:{?*}"
Reg_parser = nltk.RegexpParser(grammar)
Reg_parser.parse(sentence)
Output = Reg_parser.parse(sentence)
Output.draw()
输出
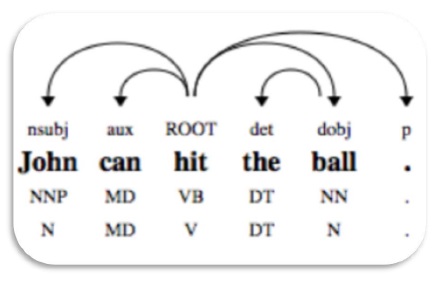
依赖解析
依赖解析(Dependency Parsing,DP)是一种现代的解析机制,其主要概念是每个语言单元(即单词)通过直接链接相互关联。这些直接链接实际上是语言上的“依赖项” 。例如,下图显示了句子“约翰可以击球”的依存语法。
NLTK套件
我们遵循以下两种方法来使用NLTK进行依赖项解析-
概率投影依赖解析器
这是我们可以使用NLTK进行依赖项解析的第一种方法。但是此解析器在训练数据集有限的情况下具有训练的限制。
斯坦福解析器
这是我们可以使用NLTK进行依赖项解析的另一种方法。斯坦福解析器是最新的依赖解析器。 NLTK周围有包装纸。要使用它,我们需要下载以下两件事:
所需语言的语言模型。例如,英语语言模型。
例
下载模型后,我们可以通过NLTK使用它,如下所示-
from nltk.parse.stanford import StanfordDependencyParser
path_jar = 'path_to/stanford-parser-full-2014-08-27/stanford-parser.jar'
path_models_jar = 'path_to/stanford-parser-full-2014-08-27/stanford-parser-3.4.1-models.jar'
dep_parser = StanfordDependencyParser(
path_to_jar = path_jar, path_to_models_jar = path_models_jar
)
result = dep_parser.raw_parse('I shot an elephant in my sleep')
depndency = result.next()
list(dependency.triples())
输出
[
((u'shot', u'VBD'), u'nsubj', (u'I', u'PRP')),
((u'shot', u'VBD'), u'dobj', (u'elephant', u'NN')),
((u'elephant', u'NN'), u'det', (u'an', u'DT')),
((u'shot', u'VBD'), u'prep', (u'in', u'IN')),
((u'in', u'IN'), u'pobj', (u'sleep', u'NN')),
((u'sleep', u'NN'), u'poss', (u'my', u'PRP$'))
]