自然语言处理 |使用正则表达式进行部分解析
- 定义一个语法来解析 3 种短语类型。
- ChunkRule 类用于查找可选的限定词后跟一个或多个名词,用于名词短语。
- 要将形容词添加到名词块的前面,请使用 MergeRule 类。
- 任何 IN 词都只是为介词短语分块。
- 一个可选的情态词(如应该)后跟一个动词被分块用于动词短语。
代码#1:
chunker = RegexpParser(r'''
NP:
# chunk optional determiner with nouns
{?+}
# merge adjective with noun chunk
{}
PP:
# chunk preposition
{}
VP:
# chunk optional modal with verb
{?} ''')
from nltk.corpus import conll2000
score = chunker.evaluate(conll2000.chunked_sents())
print ("Accuracy : ", score.accuracy())
输出 :
Accuracy : 0.6148573545757688
treebank_chunk corpus 是 treebank corpus 的一个特殊版本,它提供了一个 chunked_sents() 方法。由于其文件格式,常规的树库语料库无法提供该方法。
代码 #2:使用 treebank_chunk
from nltk.corpus import treebank_chunk
treebank_score = chunker.evaluate(
treebank_chunk.chunked_sents())
print ("Accuracy : ", treebank_score.accuracy()
输出 :
Accuracy : 0.49033970276008493
块分数指标
它提供了准确性以外的指标。大块的
精度意味着有多少是正确的。
召回意味着与有多少总块相比,分块器在找到正确块方面的表现如何。 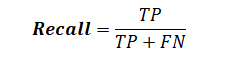
代码#3:块分数指标
print ("Precision : ", score.precision())
print ("\nRecall : ", score.recall())
print ("\nLength for missed one : ", len(score.missed()))
print ("\nLength for incorrect one : ", len(score.incorrect()))
print ("\nLength for correct one : ", len(score.correct()))
print ("\nLength for guessed one : ", len(score.guessed()))
输出 :
Precision : 0.60201948127375
Recall : 0.606072502505847
Length for missed one : 47161
Length for incorrect one : 47967
Length for correct one : 119720
Length for guessed one : 120526