根据值对 Pandas Dataframe 中的行或列进行排序
在本文中,让我们讨论如何根据值对 Pandas Dataframe 中的行或列进行排序。 Pandas sort_values()方法按传递的列的升序或降序对数据框进行排序。它与 sorted Python函数不同,因为它无法对数据框进行排序并且无法选择特定列。
Syntax: DataFrame.sort_values(by, axis=0, ascending=True, inplace=False, kind=’quicksort’, na_position=’last’)
Parameters: This method will take following parameters :
by: Single/List of column names to sort Data Frame by.
axis: 0 or ‘index’ for rows and 1 or ‘columns’ for Column.
ascending: Boolean value which sorts Data frame in ascending order if True.
inplace: Boolean value. Makes the changes in passed data frame itself if True.
kind: String which can have three inputs(‘quicksort’, ‘mergesort’ or ‘heapsort’) of the algorithm used to sort data frame.
na_position: Takes two string input ‘last’ or ‘first’ to set position of Null values. Default is ‘last’.
Return Type: Returns a sorted Data Frame with Same dimensions as of the function caller Data Frame.
现在,让我们创建一个示例数据框:
# import pandas library as pd
import pandas as pd
# List of Tuples
students = [('Ankit', 22, 'Up', 'Geu'),
('Ankita', 31, 'Delhi', 'Gehu'),
('Rahul', 16, 'Tokyo', 'Abes'),
('Simran', 41, 'Delhi', 'Gehu'),
('Shaurya', 33, 'Delhi', 'Geu'),
('Harshita', 35, 'Mumbai', 'Bhu' ),
('Swapnil', 35, 'Mp', 'Geu'),
('Priya', 35, 'Uk', 'Geu'),
('Jeet', 35, 'Guj', 'Gehu'),
('Ananya', 35, 'Up', 'Bhu')
]
# Create a DataFrame object from
# list of tuples with columns
# and indices.
details = pd.DataFrame(students, columns =['Name', 'Age',
'Place', 'College'],
index =[ 'b', 'c', 'a', 'e', 'f',
'g', 'i', 'j', 'k', 'd'])
# show the dataframe
details
输出: 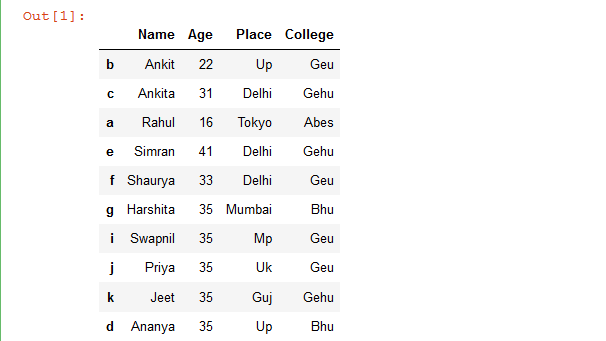
示例 1:基于单个列对 Dataframe 行进行排序。
# import pandas library as pd
import pandas as pd
# List of Tuples
students = [('Ankit', 22, 'Up', 'Geu'),
('Ankita', 31, 'Delhi', 'Gehu'),
('Rahul', 16, 'Tokyo', 'Abes'),
('Simran', 41, 'Delhi', 'Gehu'),
('Shaurya', 33, 'Delhi', 'Geu'),
('Harshita', 35, 'Mumbai', 'Bhu' ),
('Swapnil', 35, 'Mp', 'Geu'),
('Priya', 35, 'Uk', 'Geu'),
('Jeet', 35, 'Guj', 'Gehu'),
('Ananya', 35, 'Up', 'Bhu')
]
# Create a DataFrame object from
# list of tuples with columns
# and indices.
details = pd.DataFrame(students, columns =['Name', 'Age',
'Place', 'College'],
index =[ 'b', 'c', 'a', 'e', 'f',
'g', 'i', 'j', 'k', 'd'])
# Sort the rows of dataframe by 'Name' column
rslt_df = details.sort_values(by = 'Name')
# show the resultant Dataframe
rslt_df
输出: 
示例 2:基于多列对 Dataframe 行进行排序。
# import pandas library as pd
import pandas as pd
# List of Tuples
students = [('Ankit', 22, 'Up', 'Geu'),
('Ananya', 31, 'Delhi', 'Gehu'),
('Rahul', 16, 'Tokyo', 'Abes'),
('Simran', 41, 'Delhi', 'Gehu'),
('Shaurya', 33, 'Delhi', 'Geu'),
('Harshita', 35, 'Mumbai', 'Bhu' ),
('Priya', 35, 'Mp', 'Geu'),
('Priya', 34, 'Uk', 'Geu'),
('Jeet', 35, 'Guj', 'Gehu'),
('Ananya', 35, 'Up', 'Bhu')
]
# Create a DataFrame object from
# list of tuples with columns
# and indices.
details = pd.DataFrame(students, columns =['Name', 'Age',
'Place', 'College'],
index =[ 'b', 'c', 'a', 'e', 'f',
'g', 'i', 'j', 'k', 'd'])
# sort Dataframe rows based on a 'Name' & 'Age' columns
# if duplicate value is present in 'Name' column
# then sorting will be done according to 'Age' column
rslt_df = details.sort_values(by = ['Name', 'Age'])
# show the resultant Dataframe
rslt_df
输出: 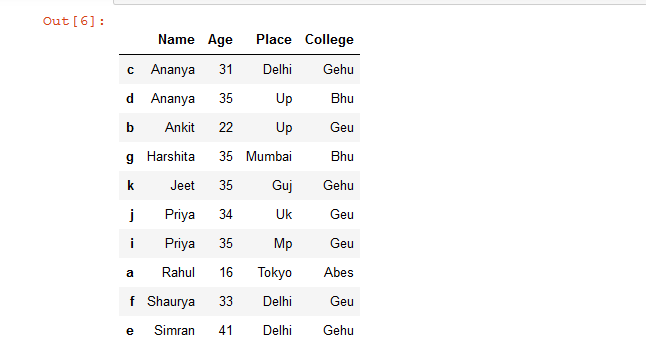
示例 3:根据降序排列的列对 Dataframe 行进行排序。
# import pandas library as pd
import pandas as pd
# List of Tuples
students = [('Ankit', 22, 'Up', 'Geu'),
('Ananya', 31, 'Delhi', 'Gehu'),
('Rahul', 16, 'Tokyo', 'Abes'),
('Simran', 41, 'Delhi', 'Gehu'),
('Shaurya', 33, 'Delhi', 'Geu'),
('Harshita', 35, 'Mumbai', 'Bhu' ),
('Priya', 35, 'Mp', 'Geu'),
('Priya', 34, 'Uk', 'Geu'),
('Jeet', 35, 'Guj', 'Gehu'),
('Ananya', 35, 'Up', 'Bhu')
]
# Create a DataFrame object from
# list of tuples with columns
# and indices.
details = pd.DataFrame(students, columns =['Name', 'Age',
'Place', 'College'],
index =[ 'b', 'c', 'a', 'e', 'f',
'g', 'i', 'j', 'k', 'd'])
# sort Dataframe rows based on "Name'
# column in Descending Order
rslt_df = details.sort_values(by = 'Name', ascending = False)
# show the resultant Dataframe
rslt_df
输出: 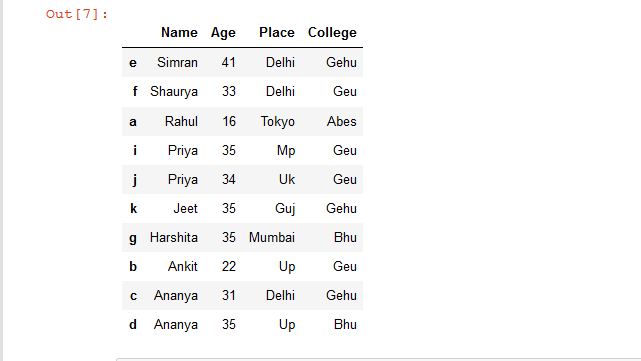
示例 4:根据就地列对 Dataframe 行进行排序。
# import pandas library as pd
import pandas as pd
# List of Tuples
students = [('Ankit', 22, 'Up', 'Geu'),
('Ananya', 31, 'Delhi', 'Gehu'),
('Rahul', 16, 'Tokyo', 'Abes'),
('Simran', 41, 'Delhi', 'Gehu'),
('Shaurya', 33, 'Delhi', 'Geu'),
('Harshita', 35, 'Mumbai', 'Bhu' ),
('Priya', 35, 'Mp', 'Geu'),
('Priya', 34, 'Uk', 'Geu'),
('Jeet', 35, 'Guj', 'Gehu'),
('Ananya', 35, 'Up', 'Bhu')
]
# Create a DataFrame object from
# list of tuples with columns
# and indices.
details = pd.DataFrame(students, columns =['Name', 'Age',
'Place', 'College'],
index =[ 'b', 'c', 'a', 'e', 'f',
'g', 'i', 'j', 'k', 'd'])
# Sort the rows of dataframe by 'Name'
# column inplace
details.sort_values(by = 'Name', inplace = True)
# show the resultant Dataframe
details
输出: 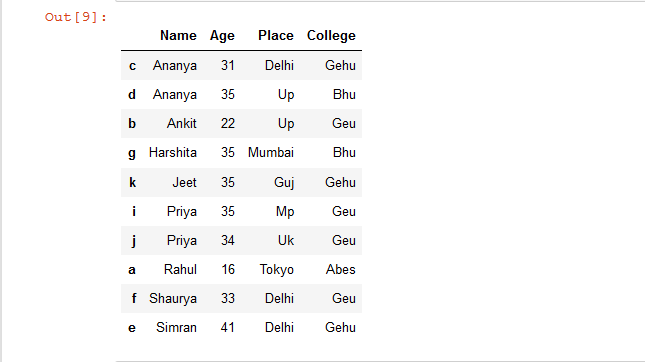
让我们看看另一个简单的 Dataframe,我们可以在其上根据行对列进行排序。
# import pandas library as pd
import pandas as pd
# List of Tuples
students = [
(75, 50, 60, 70),
(75, 55, 65, 75),
(75, 35, 45, 25),
(75, 90, 60, 70),
(76, 90, 70, 60),
(90, 80, 70, 60),
(65, 10, 30, 20)
]
# Create a DataFrame object from
# list of tuples with columns
# and indices.
details = pd.DataFrame(students, columns =['Hindi', 'Math',
'Science', 'English'],
index = ['Ankit', 'Rahul', 'Aishwarya',
'Shivangi', 'Priya', 'Swapnil',
'Shaurya'])
# show the dataframe
details
输出: 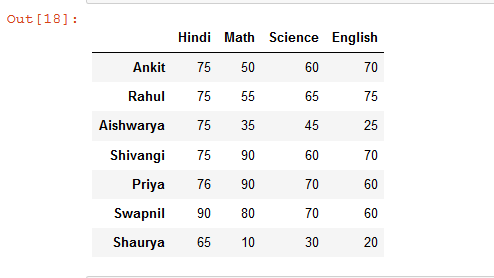
示例 1:基于单行对 Dataframe 的列进行排序。
# import pandas library as pd
import pandas as pd
# List of Tuples
students = [
(75, 50, 60, 70),
(75, 55, 65, 75),
(75, 35, 45, 25),
(75, 90, 60, 70),
(76, 90, 70, 60),
(90, 80, 70, 60),
(65, 10, 30, 20)
]
# Create a DataFrame object from
# list of tuples with columns
# and indices.
details = pd.DataFrame(students, columns =['Hindi', 'Math',
'Science', 'English'],
index = ['Ankit', 'Rahul', 'Aishwarya',
'Shivangi', 'Priya', 'Swapnil',
'Shaurya'])
# sort columns of a Dataframe based
# on a 'Shivangi' row
rslt_df = details.sort_values(by = 'Shivangi', axis = 1)
# show the dataframe
rslt_df
输出: 
示例 2:基于单行按降序对数据框的列进行排序。
# import pandas library as pd
import pandas as pd
# List of Tuples
students = [
(75, 50, 60, 70),
(75, 55, 65, 75),
(75, 35, 45, 25),
(75, 90, 60, 70),
(76, 90, 70, 60),
(90, 80, 70, 60),
(65, 10, 30, 20)
]
# Create a DataFrame object from
# list of tuples with columns
# and indices.
details = pd.DataFrame(students, columns =['Hindi', 'Math',
'Science', 'English'],
index = ['Ankit', 'Rahul', 'Aishwarya',
'Shivangi', 'Priya', 'Swapnil',
'Shaurya'])
# Sort columns of a dataframe in descending order
# based on a 'Shivangi' row
rslt_df = details.sort_values(by = 'Shivangi', axis = 1, ascending = False)
rslt_df
输出: 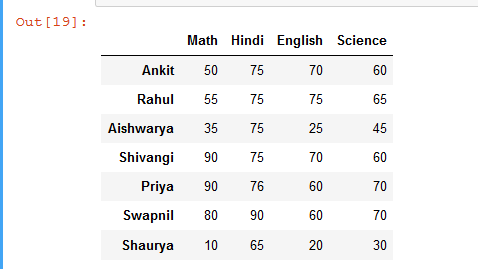
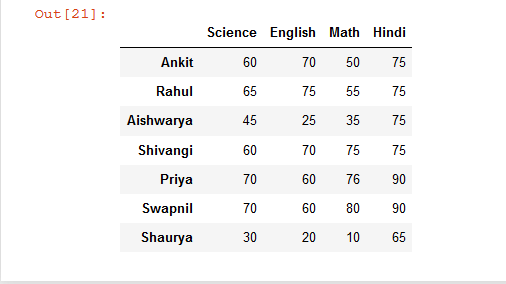
示例 3:基于多行对 Dataframe 的列进行排序。
# import pandas library as pd
import pandas as pd
# List of Tuples
students = [
(75, 50, 60, 70),
(75, 55, 65, 75),
(75, 35, 45, 25),
(75, 90, 60, 70),
(76, 90, 70, 60),
(90, 80, 70, 60),
(65, 10, 30, 20)
]
# Create a DataFrame object from
# list of tuples with columns
# and indices.
details = pd.DataFrame(students, columns =['Hindi', 'Math',
'Science', 'English'],
index = ['Ankit', 'Rahul', 'Aishwarya',
'Shivangi', 'Priya', 'Swapnil',
'Shaurya'])
# sort Dataframe columns based on a 'Shivangi' & 'Priya' rows
# if duplicate value is present in 'Shivangi' row
# then sorting will be done according to 'Priya' row
rslt_df = details.sort_values(by = ['Shivangi', 'Priya'], axis = 1)
rslt_df
输出: