在本文中,我们将讨论并行数据库的概述,然后重点介绍它们的需求和优势,最后,通过示例介绍诸如“加速”和“扩展”之类的性能度量因素。让我们一一讨论。
并行数据库:
如今,组织需要以高传输速率处理大量数据。对于此类要求,客户端服务器或集中式系统效率不高。随着提高系统效率的需求,并行数据库的概念浮出水面。并行数据库系统试图通过并行化概念来提高系统性能。
需要 :
并行使用多个资源,例如CPU和磁盘。与串行处理相反,这些操作是同时执行的。并行服务器可以允许多台计算机上的用户访问单个数据库。它还执行许多并行化操作,例如数据加载,查询处理,构建索引和评估查询。
好处 :
在这里,我们将讨论并行数据库的优点。我们来看一下。
- 性能改进 –
通过并行连接CPU和磁盘等多种资源,我们可以显着提高系统性能。 - 高可用性 –
在并行数据库中,节点之间的联系较少,因此一个节点的故障不会导致整个系统的故障。这大大提高了数据库的可用性。 - 合理利用资源–
由于并行执行,CPU将永远不是理想的选择。因此,存在适当的资源利用。 - 提高可靠性–
当一个站点发生故障时,可以从另一个拥有数据副本的可用站点继续执行。使系统更加可靠。
数据库性能评估:
在这里,我们将重点介绍性能度量因子,例如“加速”和“放大”。让我们借助示例逐一理解它。
加速 –
通过增加资源数量以更少的时间执行任务的能力称为加速。
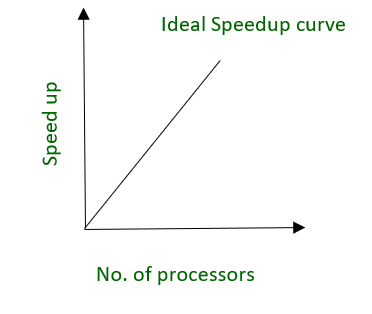
如图。理想加速曲线
例子 –
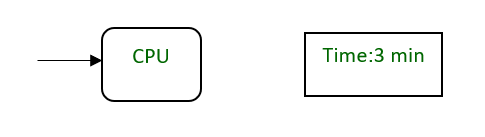
如图。 CPU需要3分钟执行一个进程
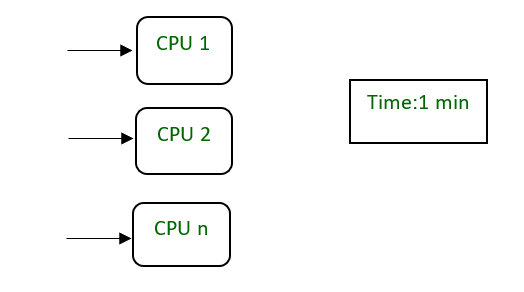
如图。 n个CPU需要1分钟才能通过划分成较小的任务来执行一个进程
放大 –
当工作负载和资源成比例增加时,保持系统性能的能力。
如图。理想的放大曲线
例子 –
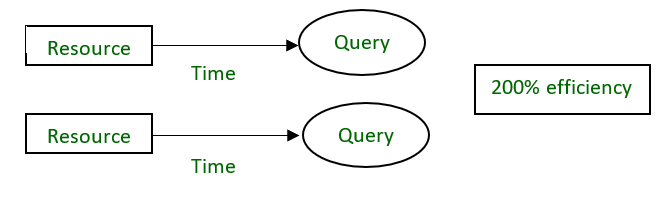
20个用户正在以100%的效率使用CPU。如果我们尝试添加更多用户,则单个处理器不可能处理更多用户。可以添加新的处理器以并行服务用户。并将提供200%的效率。