Que – 1.函数shiftNode() 将两个链表作为输入——目标和源。它从源中删除前端节点并将其放置到目标的前端。选择在给定函数替换 X、Y、Z 的语句集。
void shiftNode(struct node** destRoot,
struct node** srcRoot)
{
// the front of source node
struct node* newNode = *srcRoot;
assert(newNode != NULL);
X;
Y;
Z;
}
(一种)
X: *srcRoot = newNode->next
Y: newNode->next = *destRoot->next
Z: *destRoot->next = newNode(二)
X: *srcRoot->next = newNode->next
Y: newNode->next = *destRoot
Z: *destRoot = newNode->next(C)
X: *srcRoot = newNode->next
Y: newNode->next = *destRoot
Z: *destRoot = srcRoot->next(四)
X: *srcRoot = newNode->next
Y: newNode->next = *destRoot
Z: *destRoot = newNode解决方案:
X:将指针向前移动到源链表。
Y:使新节点指向旧目标链表的前面。
Z:让目标链表指向新节点。
所以,选项(D)是正确的。 Que – 2.当递归 DFS(v) 完成时,顶点 v 被称为“结束”。对于给定的图,顶点“结束”的顺序是什么?考虑 DFS 从顶点 a 开始,如果有多个可能的路径,则按字母顺序行进。 
(一) efihgcdba
(B) abdcegfhi
(C) abcdegifh
(D) efihdgcba
解决方案:
重要的是要注意,答案不是图形的 DFS。粉红色的节点给出了 DFS 的顺序。即:abdcegfh i。绿色节点给出了它们不断“超越”的顺序:efihgcdb a。 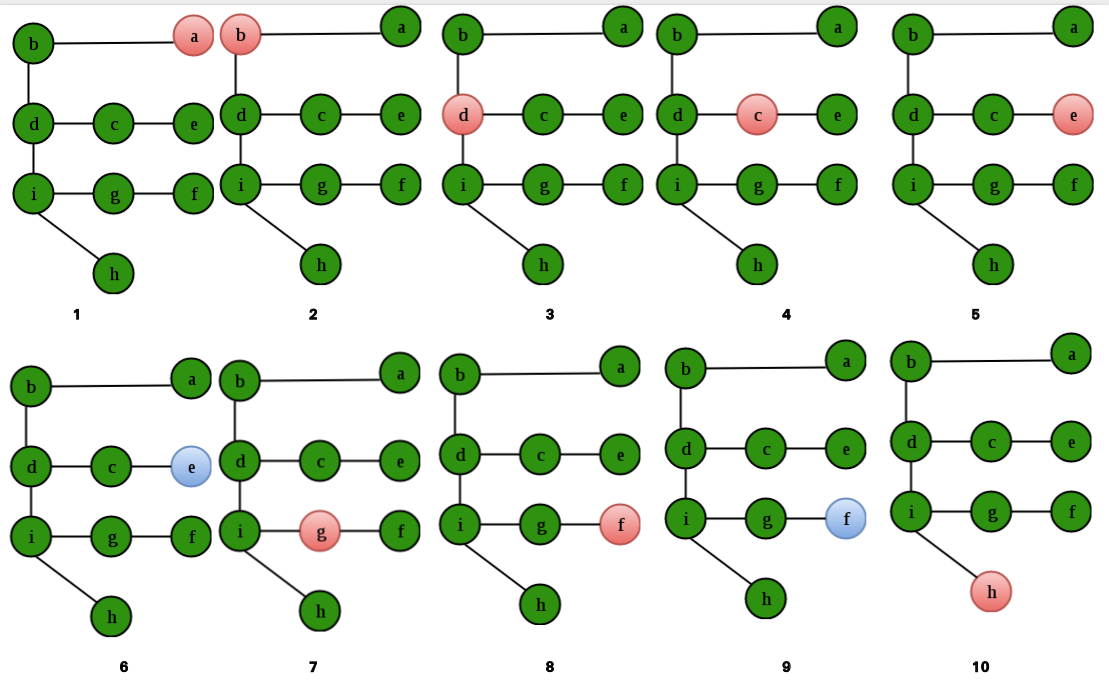
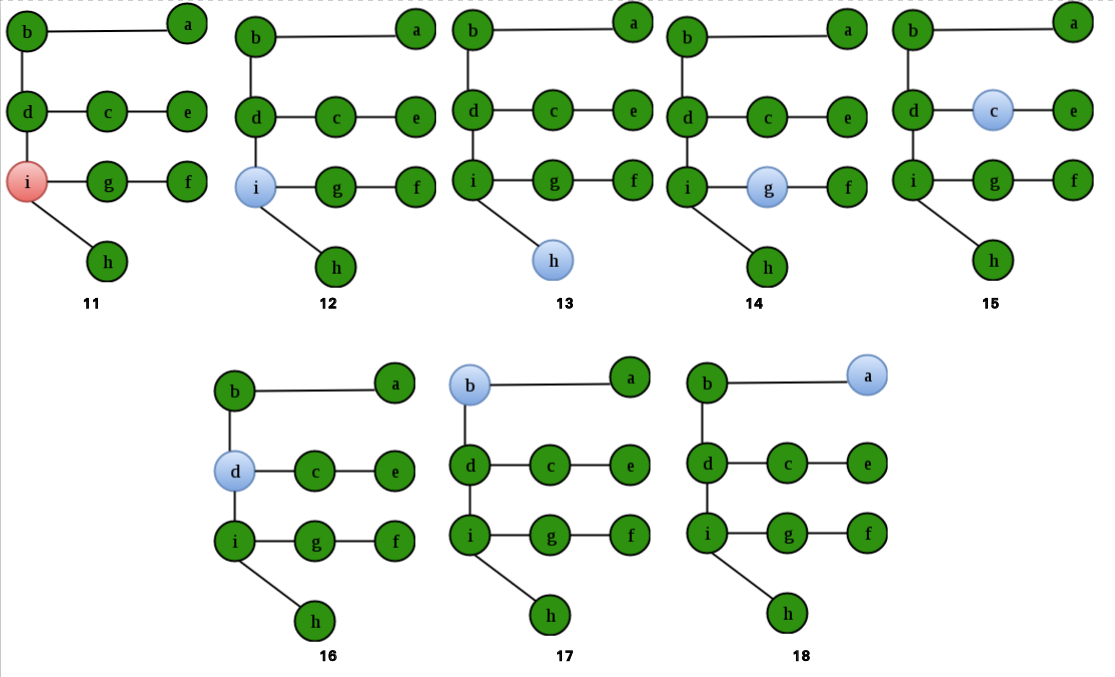
选项(A)是正确的。
Que – 3.给你两个单向链表,头分别为 head_ref1 和 head_ref2。下面的函数有什么函数?
int myFunc(Node* head_ref1, Node* head_ref2) {
Node *pointer1 = head_ref1, *pointer2 = head_ref2;
while (pointer1 != pointer2) {
pointer1 = pointer1?pointer1->next:head_ref2;
pointer2 = pointer2?pointer2->next:head_ref1;
}
return pointer1?pointer1->data:-1;
}
(A) 合并两个链表
(B) 寻找两个链表的合并点
(C) 交换两个链表的节点
(D) 程序无限循环运行
解决方案:
指向两个链表的指针在列表之间不断增加和交换,直到它们找到一个共同的交点。如果没有合并点,即当指针 1 和指针 2 在 NULL 处相遇时,该函数返回 -1。对示例链表进行试运行会使概念更加清晰。
选项(B)是正确的。
Que – 4.函数copyBSTNodes() 为二叉搜索树的每个节点创建一个副本,并将复制的节点作为原始节点的左子节点插入。结果树仍然是 BST。选择在给定函数替换 X 和 Y 的语句集。
void copyBSTNodes (struct node* root) {
struct node* prevLeft;
if (root==NULL) return;
copyBSTNodes (root->left);
copyBSTNodes (root->right);
X;
root->left = newNode(root->data);
Y;
}
(一种)
X: prevLeft->left = root->left
Y: root->left->left = prevLeft->left
(乙)
X: prevLeft = root->left
Y: root->left->left = prevLeft
(C)
X: prevLeft = root
Y: root->left = prevLeft
(四)
X: prevLeft = root->left
Y: root->left->left = prevLeft->left
解决方案: 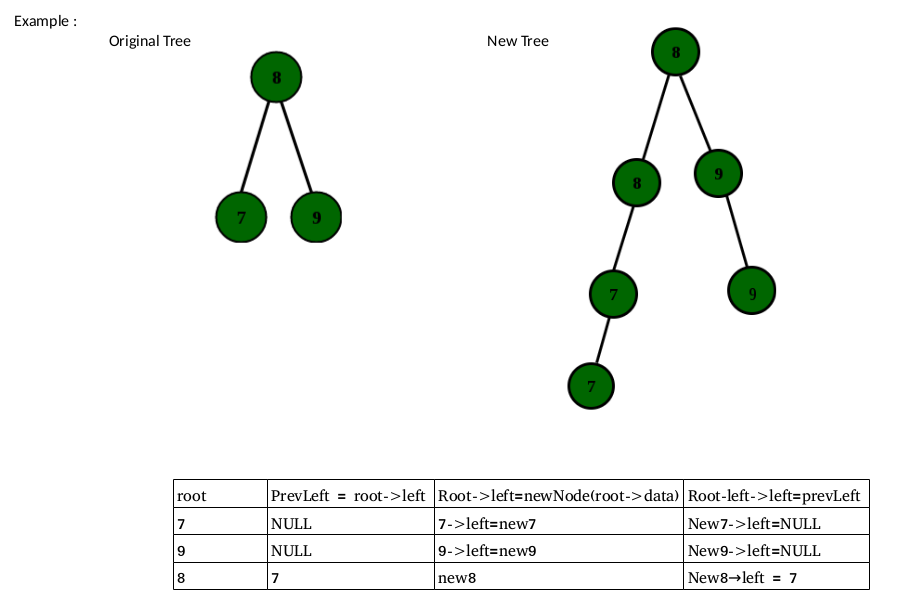
选项(B)是正确的。
Que – 5.函数eraseDup() 将按升序排序的链表作为输入。它通过只遍历一次列表从列表中删除重复的节点。选择在给定函数替换 X、Y、Z 的语句集。
void eraseDup(struct node* root) {
struct node* current = root;
if (X)
return;
while (current->next!=NULL) {
if (Y) {
struct node* nextOfNext = current->next->next;
free(current->next);
current->next = nextOfNext;
}
else {
Z
}
}
}
(一种)
X: current == NULL
Y: current = current->next
Z: current->data = current->next->data;
(二)
X: current == NULL
Y: current->data == current->next->data
Z: current = current->next;
(C)
X: current->next == NULL
Y: current->next->data == current->next->next->data
Z: current = current->next;(四)
X: current->next == NULL
Y: current->data = current->next->data
Z: current = current->next;解决方案:
由于输入链表已经排序,我们在比较相邻节点的同时向下移动列表。当相邻节点中的数据相同时,我们删除第二个节点。注意:在执行删除操作之前,需要存储下一个节点之后的节点。
选项(B)是正确的。