在数据库中,死锁是一种不需要的情况,其中两个或多个事务无限期地等待彼此放弃锁定。死锁据说是 DBMS 中最令人恐惧的并发症之一,因为它使整个系统陷入停顿。
例子——让我们通过一个例子来理解死锁的概念:
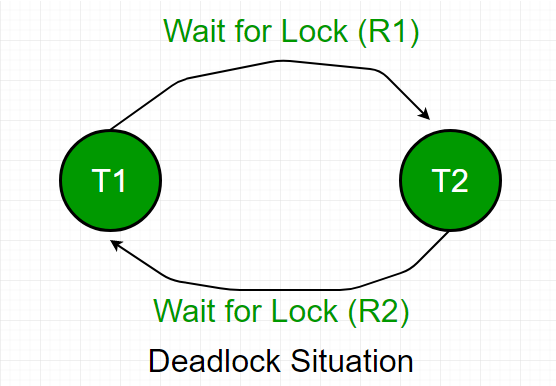
假设事务 T1 锁定了 Students 表中的某些行,并且需要更新Grades 表中的某些行。同时,事务T2 持有对 Grades 表中那些行(T1 需要更新)的锁,但需要更新事务 T1 持有的 Student 表中的行。
现在,主要问题出现了。事务 T1 会等待事务 T2 放锁,同样,事务 T2 会等待事务 T1 放锁。因此,除非 DBMS 检测到死锁并中止其中一个事务,否则所有活动都会停止并永远停止。

DBMS 中的死锁
避免死锁——
当数据库陷入死锁时,避免死锁总是比重新启动或中止数据库更好。死锁避免方法适用于较小的数据库,而死锁预防方法适用于较大的数据库。
避免死锁的一种方法是使用应用程序一致的逻辑。在上面给出的示例中,访问学生和成绩的事务应始终以相同的顺序访问表。这样,在上面描述的场景中,事务 T1 在它开始之前只是等待事务 T2 释放对 Grades 的锁。当事务 T2 释放锁时,事务 T1 可以自由进行。
另一种避免死锁的方法是同时应用行级锁定机制和 READ COMMITTED 隔离级别。但是,它并不能保证完全消除死锁。
死锁检测——
当一个事务无限期地等待获取锁时,数据库管理系统应该检测该事务是否陷入死锁。
等待图是检测死锁情况的方法之一。这种方法适用于较小的数据库。在此方法中,基于事务及其对资源的锁定绘制图形。如果创建的图形有一个闭环或一个循环,那么就会出现死锁。
对于上述场景,Wait-For 图绘制如下
死锁预防——
对于大型数据库,死锁预防方法是合适的。如果以永远不会发生死锁的方式分配资源,则可以防止死锁。 DBMS 会分析这些操作是否会造成死锁情况,如果会,则永远不允许执行该事务。
死锁预防机制提出了两种方案:
- 等待死亡计划 –
在这个方案中,如果一个事务请求被其他事务锁定的资源,那么 DBMS 只需检查两个事务的时间戳,并允许较旧的事务等待,直到资源可供执行。
假设有两个事务 T1 和 T2,让任何事务 T 的时间戳记为 TS (T)。现在,如果某个其他事务锁定了 T2,并且 T1 正在请求 T2 持有的资源,那么 DBMS 将执行以下操作:检查是否 TS (T1) < TS (T2) – 如果 T1 是较旧的事务并且 T2 持有一些资源,那么它允许 T1 等待资源可用于执行。这意味着如果一个较新的事务锁定了一些资源并且较旧的事务正在等待它,那么允许较旧的事务等待它直到它可用。如果 T1 是较旧的事务并持有一些资源,并且 T2 正在等待它,那么 T2 将被终止并稍后重新启动,但具有随机延迟但具有相同的时间戳。即,如果较旧的事务持有一些资源并且较年轻的事务等待资源,则较年轻的事务将被杀死并以相同的时间戳以非常分钟的延迟重新启动。
该方案允许较旧的事务等待但杀死较新的事务。 - 伤口等待计划 –
在这个方案中,如果一个较老的事务请求较年轻的事务持有的资源,那么较老的事务会强制较年轻的事务杀死该事务并释放资源。较新的事务以分钟延迟重新启动,但具有相同的时间戳。如果较年轻的事务正在请求由较旧的事务持有的资源,则要求较年轻的事务等待直到较旧的事务释放它。
参考 –
文档.oracle
等待死亡和伤口等待之间的区别
书 – Navathe 的数据库系统基础