- DBMS-死锁
- DBMS-死锁(1)
- DBMS 中的死锁(1)
- DBMS 中的死锁
- DBMS 中的死锁
- DBMS 中的死锁(1)
- 处理死锁
- 处理死锁(1)
- 处理死锁
- DBMS中的DBMS死锁(1)
- DBMS中的DBMS死锁
- 分布式DBMS-分布式数据库
- 分布式DBMS-分布式数据库(1)
- 分布式DBMS教程
- 讨论分布式DBMS(1)
- 讨论分布式DBMS
- 分布式系统——分布式死锁的类型
- 分布式系统——分布式死锁的类型(1)
- 处理死锁 laravel - PHP (1)
- 处理死锁 laravel - PHP 代码示例
- 分布式DBMS-概念
- 死锁 (1)
- 分布式DBMS-数据库环境
- 分布式 DBMS 的缺点(1)
- 分布式 DBMS 的缺点
- 分布式DBMS-有用的资源
- 分布式DBMS-有用的资源(1)
- 分布式DBMS-失败和提交(1)
- 分布式DBMS-失败和提交
📅 最后修改于: 2021-01-07 05:29:38 🧑 作者: Mango
本章概述了数据库系统中的死锁处理机制。我们将研究集中式和分布式数据库系统中的死锁处理机制。
什么是死锁?
当每个事务正在等待被某个其他事务锁定的数据项时,死锁是具有两个或多个事务的数据库系统的状态。死锁可以通过等待图中的一个循环来表示。这是一个有向图,其中顶点表示事务,边表示等待数据项。
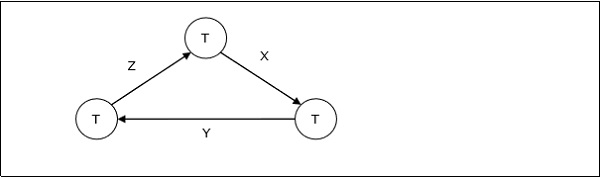
例如,在下面的等待图中,事务T1正在等待被T3锁定的数据项X。 T3正在等待被T2锁定的Y,T2正在等待被T1锁定的Z。因此,形成了一个等待周期,并且任何事务都无法继续执行。
集中式系统中的死锁处理
死锁处理有三种经典方法,即-
- 防止死锁。
- 避免死锁。
- 死锁检测和清除。
三种方法都可以并入集中式和分布式数据库系统中。
防止死锁
防止死锁的方法不允许任何事务获取将导致死锁的锁。约定是,当多个事务请求锁定同一数据项时,仅其中之一被授予锁定。
预防死锁最流行的方法之一是预先获取所有锁。在这种方法中,事务在开始执行之前先获取所有锁,并在整个事务期间保留这些锁。如果另一个事务需要任何已获取的锁,则它必须等待直到所需的所有锁可用为止。使用这种方法,可以防止系统死锁,因为没有一个等待的事务持有任何锁。
避免死锁
避免死锁的方法可以在死锁发生之前对其进行处理。它分析事务和锁,以确定是否等待导致死锁。
该方法可以简述如下。事务开始执行并请求它们需要锁定的数据项。锁管理器检查锁是否可用。如果可用,则锁管理器分配数据项,然后事务获取锁。但是,如果项目以不兼容模式被其他某个事务锁定,则锁管理器将运行算法以测试将事务保持在等待状态是否会导致死锁。因此,该算法决定该事务是否可以等待或应该中止其中一个事务。
为此,有两种算法,即wait-die和伤口等待。让我们假设有两个事务,T1和T2,其中T1尝试锁定已经被T2锁定的数据项。算法如下-
-
Wait-Die-如果T1早于T2,则允许T1等待。否则,如果T1小于T2,则T1将中止,然后重新启动。
-
Wound-Wait-如果T1早于T2,则T2中止,然后重新启动。否则,如果T1小于T2,则允许T1等待。
死锁检测和清除
死锁检测和消除方法定期运行死锁检测算法,并在有死锁的情况下消除死锁。当事务发出锁定请求时,它不会检查死锁。当事务请求锁时,锁管理器检查它是否可用。如果可用,则允许事务锁定数据项;否则,交易将等待。
由于在授予锁定请求时没有采取任何预防措施,因此某些事务可能会死锁。为了检测死锁,锁管理器会定期检查等待表是否具有周期。如果系统死锁,则锁管理器从每个周期中选择一个受害者事务。受害人被中止并回滚;然后稍后重新启动。用于受害者选择的一些方法是-
- 选择最年轻的交易。
- 选择数据项最少的交易。
- 选择执行最少更新的事务。
- 选择具有最少重启开销的事务。
- 选择两个或多个周期共有的事务。
此方法主要适用于事务处理量低且需要对锁定请求快速响应的系统。
分布式系统中的死锁处理
分布式数据库系统中的事务处理也是分布式的,即同一事务可能在多个站点进行处理。集中式系统中不存在的两个主要死锁处理问题是事务定位和事务控制。一旦解决了这些问题,就可以通过防止死锁,避免死锁或检测和消除死锁来处理死锁。
交易地点
分布式数据库系统中的事务在多个站点中进行处理,并在多个站点中使用数据项。这些站点之间的数据处理量不均匀。处理的时间段也有所不同。因此,同一笔交易可能在某些站点处于活动状态,而在另一些站点处于无效状态。当两个冲突的事务位于一个站点中时,它们之一可能处于非活动状态。在集中式系统中不会出现这种情况。此问题称为交易位置问题。
雏菊链模型可以解决此问题。在此模型中,事务从一个站点移动到另一个站点时会携带某些详细信息。其中的一些细节是所需表的列表,所需站点的列表,已访问表和站点的列表,尚未被访问的表和站点的列表以及具有类型的已获取锁的列表。事务通过提交或中止终止后,信息应发送到所有相关站点。
交易控制
事务控制与指定和控制在分布式数据库系统中处理事务所需的站点有关。关于在何处处理交易以及如何指定控制中心的选择,有很多选择,例如-
- 可以选择一台服务器作为控制中心。
- 控制中心可能从一台服务器传播到另一台服务器。
- 控制的责任可以由许多服务器共同承担。
分布式死锁预防
就像集中式死锁预防一样,在分布式死锁预防方法中,事务应在开始执行之前获取所有锁。这样可以防止死锁。
交易进入的站点被指定为控制站点。控制站点将消息发送到数据项所在的站点以锁定这些项。然后,它等待确认。当所有站点都确认它们已锁定数据项时,事务开始。如果任何站点或通信链接失败,则事务必须等待,直到它们被修复为止。
虽然实现很简单,但是这种方法有一些缺点-
-
预先获取锁需要较长的通信延迟时间。这增加了交易所需的时间。
-
如果站点或链接失败,则事务必须等待很长时间才能使站点恢复。同时,在正在运行的站点中,项目被锁定。这可能会阻止其他事务执行。
-
如果控制站点发生故障,它将无法与其他站点通信。这些站点继续将锁定的数据项保持在其锁定状态,从而导致阻塞。
分布式死锁避免
与集中式系统一样,分布式死锁避免可以在发生死锁之前进行处理。另外,在分布式系统中,需要解决交易位置和交易控制问题。由于交易的分布式性质,可能会发生以下冲突-
- 同一站点中的两个事务之间发生冲突。
- 不同站点中的两个事务之间的冲突。
在发生冲突的情况下,可以根据分布式等待模具或分布式伤口等待算法中止事务之一或允许其等待。
让我们假设有两个事务,T1和T2。 T1到达站点P并尝试锁定该站点已被T2锁定的数据项。因此,站点P发生冲突。算法如下-
-
分布式伤口模具
-
如果T1早于T2,则允许T1等待。在站点P收到一条消息,表明T2已在所有站点成功提交或中止后,T1可以恢复执行。
-
如果T1小于T2,则T1中止。站点P上的并发控制将消息发送到T1访问过的所有站点以中止T1。当所有站点中的T1成功中止时,控制站点会通知用户。
-
-
分布式等待
-
如果T1早于T2,则需要中止T2。如果T2在站点P上处于活动状态,则站点P将中止并回滚T2,然后将此消息广播到其他相关站点。如果T2已离开站点P但在站点Q处于活动状态,则站点P广播T2已中止;站点L然后中止并回滚T2并将此消息发送到所有站点。
-
如果T1小于T1,则允许T1等待。站点P收到T2已完成处理的消息后,T1可以恢复执行。
-
分布式死锁检测
就像集中式死锁检测方法一样,死锁也允许发生并在检测到死锁后将其删除。当事务发出锁定请求时,系统不执行任何检查。为了实现,创建了全局等待图。全局等待图中存在循环表示死锁。但是,由于事务等待整个网络上的资源,因此很难发现死锁。
另外,死锁检测算法可以使用计时器。每个事务都与一个计时器相关联,该计时器设置为一个期望完成事务的时间段。如果在此时间段内事务未完成,计时器将关闭,表明可能出现死锁。
用于死锁处理的另一种工具是死锁检测器。在集中式系统中,有一个死锁检测器。在分布式系统中,可以有多个死锁检测器。死锁检测器可以找到受其控制的站点的死锁。分布式系统中死锁检测有三种选择,即。
-
集中式死锁检测器-一个站点被指定为中央死锁检测器。
-
分层死锁检测器-多个死锁检测器按层次结构排列。
-
分布式死锁检测器-所有站点都参与检测死锁并删除死锁。