数据挖掘是指从大量数据中提取或挖掘知识。这个词实际上是用词不当。因此,数据挖掘应该更恰当地命名为知识挖掘,它强调从大量数据中进行挖掘。它是在大数据集中发现模式的计算过程,涉及人工智能、机器学习、统计和数据库系统的交叉方法。数据挖掘过程的总体目标是从数据集中提取信息并将其转换为可理解的结构以供进一步使用。
它也被定义为从大量数据中提取有趣的(非平凡的、隐含的、以前未知的和潜在有用的)模式或知识。数据挖掘是一个快速发展的领域,它涉及开发技术以帮助管理人员和决策者智能地使用大量存储库。
数据挖掘的别称:
1. Knowledge discovery (mining) in databases (KDD)
2. Knowledge extraction
3. Data/pattern analysis
4. Data archeology
5. Data dredging
6. Information harvesting
7. Business intelligence 数据挖掘和商业智能:
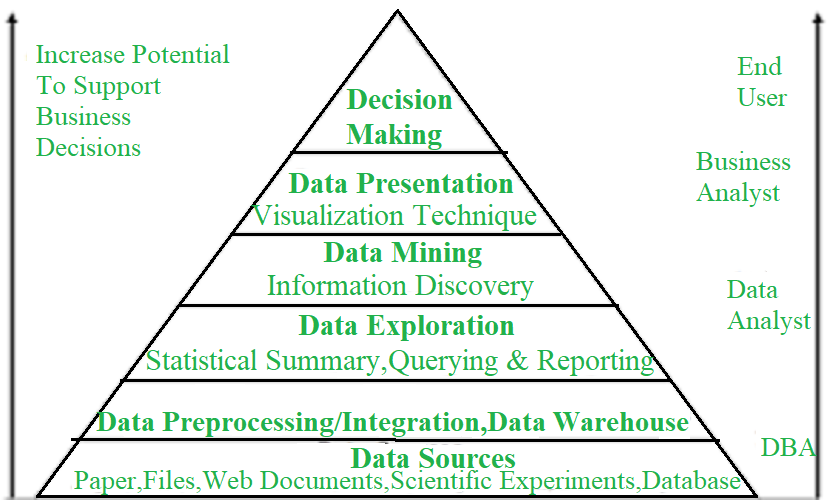
数据挖掘的关键属性:
1. Automatic discovery of patterns
2. Prediction of likely outcomes
3. Creation of actionable information
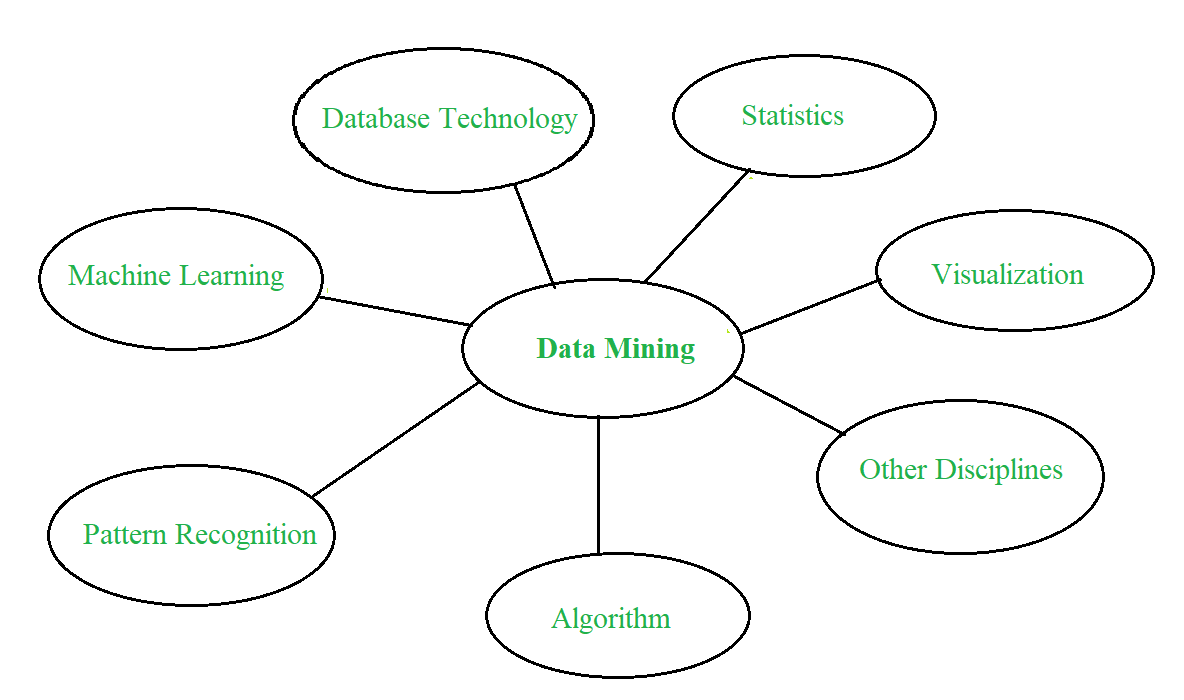
4. Focus on large datasets and databases 数据挖掘:多学科的融合——
数据挖掘过程:
数据挖掘是从给定的数据集合中发现各种模型、摘要和派生值的过程。
适用于数据挖掘问题的一般实验程序包括以下步骤:
- 陈述问题并提出假设——
在这一步中,建模者通常为未知的依赖指定一组变量,如果可能,将这种依赖的一般类型作为初始假设。在这个阶段,也可能有针对一个问题制定的几个假设。主要步骤需要结合应用领域和数据挖掘模型的专业知识。在实践中,它总是意味着数据挖掘专家和应用专家之间的深度互动。在成功的数据挖掘应用中,这种合作不会在初始阶段停止。它在整个数据挖掘过程中持续进行。 - 收集数据 –
这一步关心信息是如何生成和提取的。一般来说,有两种不同的可能性。主要是数据生成过程在专家(建模者)的控制之下。这种方法被理解为设计的实验。第二种可能性是当专家无法影响数据生成过程时。这通常被称为观察方法。在大多数数据挖掘应用程序中都假设了一种观察设置,即随机数据生成。通常,抽样分布在数据收集后完全未知,或者在数据收集过程中部分隐含地给出。然而,了解数据收集如何影响其理论分布是至关重要的,因为这样的先验知识通常对建模以及随后对结果的最终解释很有用。此外,重要的是要确保用于估计模型的信息以及稍后用于测试和应用模型的数据来自等效的未知抽样分布。如果情况并非如此,估计模型就不能成功地用于结果的最终应用。
- 数据预处理——
在观察环境中,数据通常是从流行的数据库、数据仓库和数据集市“收集”的。数据预处理通常至少包括两个常见任务:
- (i) 异常值检测(和去除):
异常值是不符合大多数观察结果的异常数据值。通常,异常值是由测量错误、编码和记录错误引起的,有时是自然的异常值。这种不具有代表性的样本会严重影响后期制作的模型。有两种处理异常值的策略:检测并最终删除作为预处理阶段邻域的异常值。并开发对异常值不敏感的稳健建模方法。
- (ii) 缩放、编码和选择特征:
数据预处理包括几个步骤,如变量缩放和不同类型的编码。例如,一个范围为 [0, 1] 的特征和另一个范围为 [100, 1000] 的特征在所应用的技术中不会具有等效权重。它们还将以不同的方式影响最终的数据挖掘结果。因此,建议对它们进行缩放,并将这两个特征传递到相同的权重以供进一步分析。此外,特定于应用程序的编码方法通常通过为后续数据建模提供较少数量的信息特征来实现降维。
这两类预处理任务只是数据挖掘过程中大量预处理活动的示例。不应将数据预处理步骤视为完全独立于其他数据挖掘阶段。在数据挖掘过程的每次迭代中,所有活动可以一起为后续迭代定义新的和改进的数据集。通常,诚实的预处理方法通过将先验知识结合到特定于应用程序的缩放和编码中来为数据挖掘技术提供最佳表示。
- (i) 异常值检测(和去除):
- 估计模型 –
选择和实施可接受的数据挖掘技术是这一阶段的主要任务。这个过程并不简单。通常,在实践中,实现取决于多个模型,选择最简单的模型是一项进一步的任务。 - 解释模型并得出结论——
在大多数情况下,数据挖掘模型应该有助于做出决定。因此,此类模型必须是可解释的,以便有用,因为人类不太可能根据复杂的“黑盒”模型做出决策。请注意,模型准确性和解释准确性的目标有些矛盾。通常,简单的模型更具可解释性,但它们也不太准确。现代数据挖掘方法有望使用高维模型产生高度准确的结果。解释这些模型的问题也很重要,需要考虑一项单独的任务,使用特定的技术来验证结果。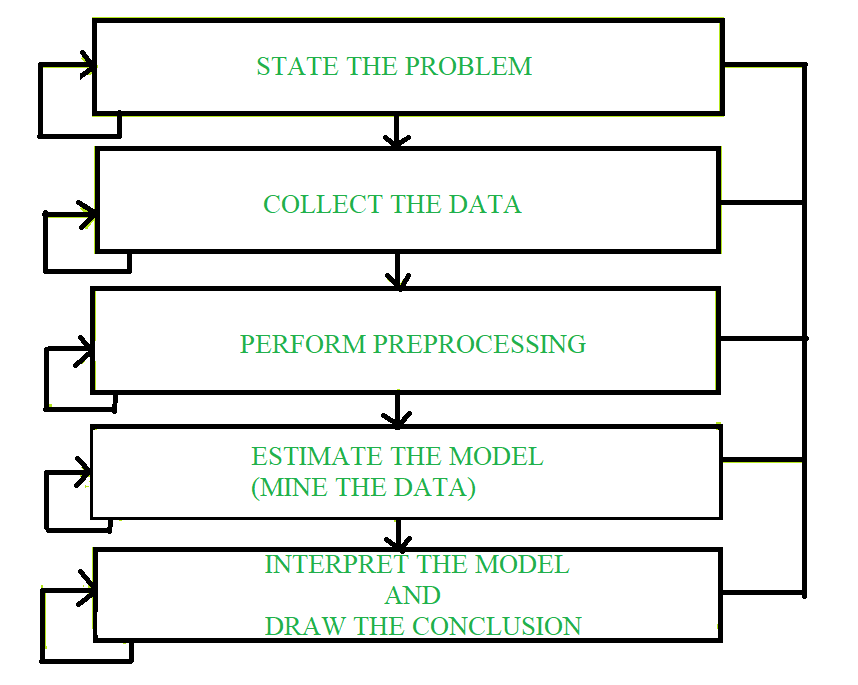
数据挖掘系统的分类:
1. Database Technology 2. Statistics 3. Machine Learning 4. Information Science 5. Visualization数据挖掘的主要问题:
- 在数据库中挖掘不同类型的知识——
不同用户的需求是不一样的。不同的用户可能对不同种类的知识感兴趣。因此,数据挖掘有必要涵盖广泛的知识发现任务。 - 在多个抽象层次上交互式挖掘知识——
数据挖掘过程需要是交互式的,因为它允许用户专注于搜索模式,根据返回的结果提供和细化数据挖掘请求。 - 结合背景知识——
为了指导发现过程和表达发现的模式,背景知识不仅可以用简洁的术语而且可以在多个抽象层次上表达发现的模式。 - 数据挖掘查询语言和即席数据挖掘——
允许用户描述临时挖掘任务的数据挖掘查询语言应该与数据仓库查询语言集成并优化以实现高效和灵活的数据挖掘。 - 数据挖掘结果的展示和可视化——
一旦发现模式,就需要用高级语言、视觉表示法来表达。这些表示应该很容易被用户理解。 - 处理嘈杂或不完整的数据——
需要能够在挖掘数据规律的同时处理噪声、不完整对象的数据清理方法。如果没有数据清理方法,那么发现模式的准确性就会很差。 - 模式评估——
它指的是问题的趣味性。发现的模式应该很有趣,因为它们要么代表常识,要么缺乏新颖性。 - 数据挖掘算法的效率和可扩展性——
为了有效地从数据库中的海量数据中提取信息,数据挖掘算法必须具有高效性和可扩展性。 - 并行、分布式和增量挖掘算法——
数据库规模庞大、数据分布广泛、数据挖掘方法复杂等因素推动了并行分布式数据挖掘算法的发展。这些算法将数据划分为进一步并行处理的分区。然后合并分区的结果。增量算法更新数据库而无需从头开始再次挖掘数据。
- 在数据库中挖掘不同类型的知识——