在 21 世纪,“数据科学”和“机器学习”两个术语是技术世界中搜索次数最多的术语。从计算机科学专业的一年级学生到 Netflix、亚马逊等大型组织,都在支持这两种技术。他们也得到了原因。在数据空间的世界中,当组织处理 PB 和 EB 的数据时,大数据时代就出现了。直到 2010 年,行业对于数据的存储变得非常困难。现在,当Hadoop等流行框架解决存储问题时,重点是处理数据。在这里,数据科学和机器学习发挥着重要作用。但是大数据有多少数据呢?

- Google每天处理 20 PB (2008)
- Facebook拥有 2.5 PB 的用户数据 + 每天 15 TB(2009 年)
- eBay拥有 6.5 PB 的用户数据 + 每天 50 TB (2009)
- CERN 的大型强子对撞机 (LHC)每年产生 15 PB
但总的来说,是什么使这两个术语不同?这两种技术之间的最大区别是什么?所以让我们用一个非常流行的简单维恩图来消除混淆,它被称为德鲁康威的维恩图。在此之前,让我们先看看这两个术语的定义。
数据科学
它是对公司或组织存储库中大量数据的复杂研究。这项研究包括数据的来源、对其内容的实际研究,以及这些数据如何对公司未来的发展有用。与组织相关的数据总是有两种形式:结构化或非结构化。当我们研究这些数据时,我们会获得有关业务或市场模式的宝贵信息,这有助于该业务比其他竞争对手更具优势,因为他们通过识别数据集中的模式提高了效率。
数据科学家是擅长将原始数据转换为关键业务事项的专家。这些科学家精通算法编码以及数据挖掘、机器学习和统计等概念。数据科学被亚马逊、Netflix、医疗保健行业、欺诈检测行业、互联网搜索、航空公司等公司广泛使用。
机器学习
机器学习是一个研究领域,它使计算机能够在没有明确编程的情况下进行学习。机器学习使用算法来处理数据并接受培训以在没有人工干预的情况下提供未来预测。机器学习的输入是一组指令或数据或观察。机器学习被 Facebook、谷歌等公司广泛使用。
是什么让这两种技术不同?
下面是德鲁康威的维恩图。让我们来看看维恩图。
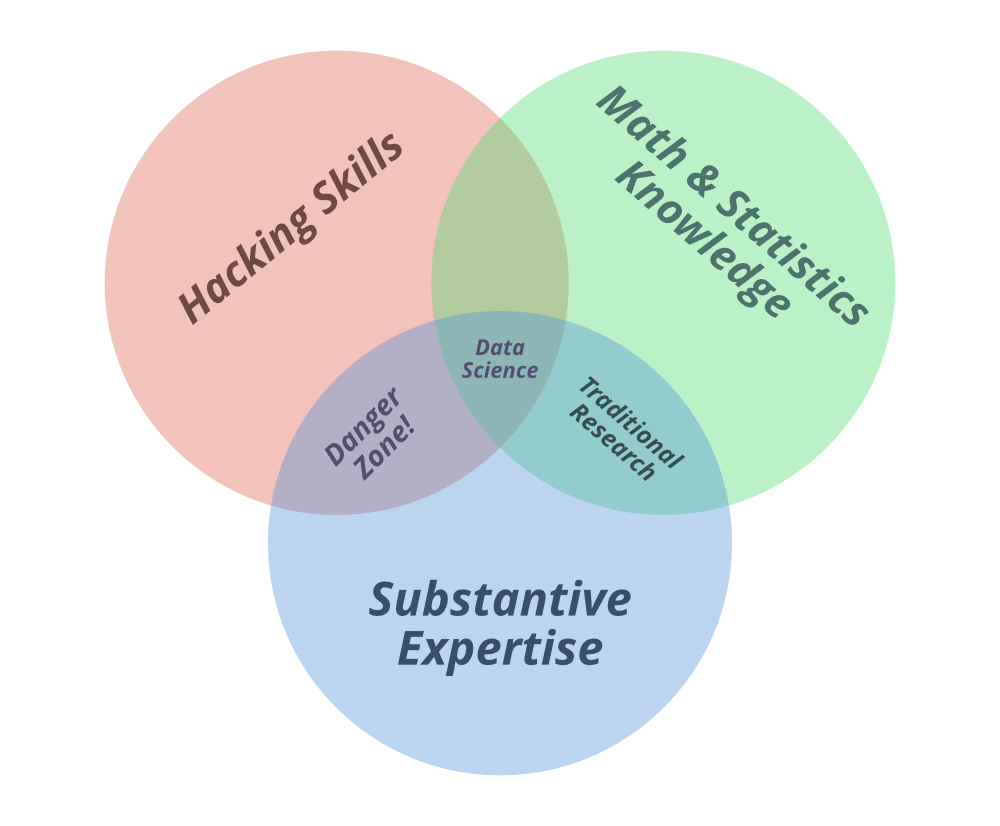
你可以在上面的维恩图中看到“数据科学”和“机器学习”这两个术语。所以让我们理解图表。在 Drew Conway 的数据科学维恩图中,数据的主要颜色是
- 黑客技能,
- 数学和统计知识,以及
- 实质性专业知识
但问题是他为什么要强调这三个? 所以让我们理解为什么这个词!!
黑客技能:众所周知,数据是数据科学的关键部分。而数据是一种以电子方式交易的商品;所以,为了进入这个市场,“一个人需要说黑客” 。那么这条线是什么意思呢?能够在命令行管理文本文件,学习矢量化操作,算法思考;是成功的数据黑客的黑客技能。
数学和统计知识:收集和清理数据后,下一步就是从中实际获得洞察力。为此,您需要使用适当的数学和统计方法,这至少需要对这些工具有基本的了解。这并不是说博士学位。在统计学中需要成为一名熟练的数据科学家,但它确实需要了解普通最小二乘回归是什么以及如何解释它。
实质性专业知识:第三个重要部分是实质性专业知识。这就是我们的困惑消除的地方。是的!!
According to Drew Conway, “Data plus Math and Statistics Knowledge only gets you Machine Learning”, which is excellent if that is what you are interested in, but not if you are doing Data Science. Science is about experimentation and building knowledge, which demands some motivating questions about the world and hypotheses that can be brought to data and tested with statistical methods.
这是这两个术语之间的主要区别点。如果您想成为数据科学家,那么您必须具备该领域的知识。但为什么?数据科学的首要目标是从该数据中提取有用的见解,以便为公司的业务带来利润。如果您不了解公司的业务方面,即公司的商业模式如何运作以及您如何构建它,那么您对这家公司毫无用处。您需要知道如何向正确的人提出正确的问题,以便您能够感知到获得所需信息所需的适当信息。以下是数据科学和机器学习之间差异的完整表格。
差异表
|
S.No |
Data Science |
Machine Learning |
|---|---|---|
| 1. | Data Science is a field about processes and systems to extract data from structured and semi-structured data. | Machine Learning is a field of study that gives computers the capability to learn without being explicitly programmed. |
| 2. | Need the entire analytics universe. | Combination of Machine and Data Science. |
| 3. | Branch that deals with data. | Machines utilize data science techniques to learn about the data. |
| 4. | Data in Data Science maybe or maybe not evolved from a machine or mechanical process. | It uses various techniques like regression and supervised clustering. |
| 5. | Data Science as a broader term not only focuses on algorithms statistics but also takes care of the data processing. | But it is only focused on algorithm statistics. |
| 6. | It is a broad term for multiple disciplines. | It fits within data science. |
| 7. | Many operations of data science that is, data gathering, data cleaning, data manipulation, etc. | It is three types: Unsupervised learning, Reinforcement learning, Supervised learning. |
| 8. | Example: Netflix uses Data Science technology. | Example: Facebook uses Machine Learning technology. |