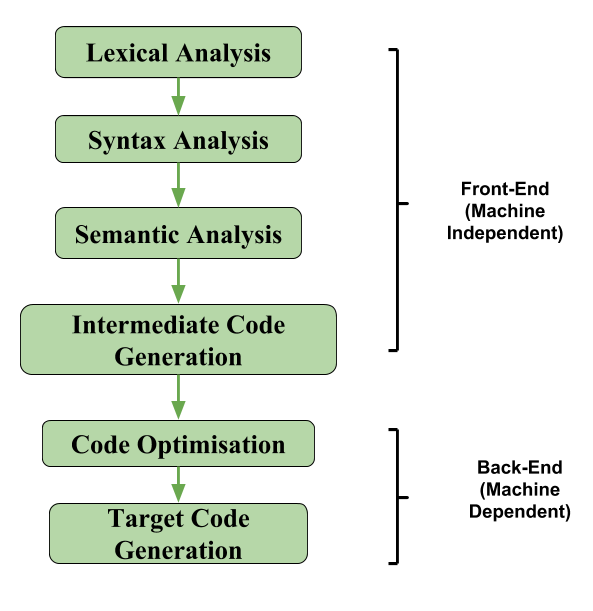
在编译器的分析综合模型中,编译器的前端将源程序翻译成独立的中间代码,编译器的后端使用这个中间代码生成目标代码(机器可以理解) )。
使用与机器无关的中间代码的好处是:
- 由于机器独立的中间代码,可移植性将得到增强。 例如,假设,如果编译器将源语言翻译成目标机器语言而没有生成中间代码的选项,那么对于每台新机器,一个完整的本地编译器是必需的。因为,显然,编译器本身根据机器规格进行了一些修改。
- 有利于重新定位
- 通过优化中间代码,更容易应用源代码修改来提高源代码的性能。
如果我们直接从源代码生成机器代码,那么对于 n 个目标机器,我们将有 n 个优化器和 n 个代码生成器,但如果我们将有一个独立于机器的中间代码,
我们将只有一个优化器。中间代码可以是特定于语言的(例如,用于Java 的字节码)或语言。独立(三地址代码)。
以下是常用的中间代码表示:
- 后缀符号 –
书写 a 和 b 之和的普通(中缀)方式是在中间使用运算符:a + b
相同表达式的后缀表示法将运算符放在右端作为 ab +。通常,如果 e1 和 e2 是任何后缀表达式,并且 + 是任何二元运算符,则将 + 应用于 e1 和 e2 表示的值的结果是 e1e2 + 的后缀表示法。后缀表示法中不需要括号,因为运算符的位置和数量(参数数量)只允许一种方式来解码后缀表达式。在后缀符号中,运算符跟在操作数之后。示例 –表达式 (a – b) * (c + d) + (a – b) 的后缀表示为:ab – cd + *ab -+。
阅读更多:中缀到后缀 - 三地址代码 –
涉及不超过三个引用(两个用于操作数,一个用于结果)的语句称为三地址语句。三个地址语句的序列称为三地址代码。三地址语句的形式为 x = y op z ,这里 x, y, z 将具有地址(内存位置)。有时一个语句可能包含少于三个引用,但它仍然被称为三地址语句。示例 –表达式 a + b * c + d 的三个地址代码:
T 1 = b * c
T 2 = a + T 1
T 3 = T 2 + dT 1 、T 2 、T 3 是临时变量。
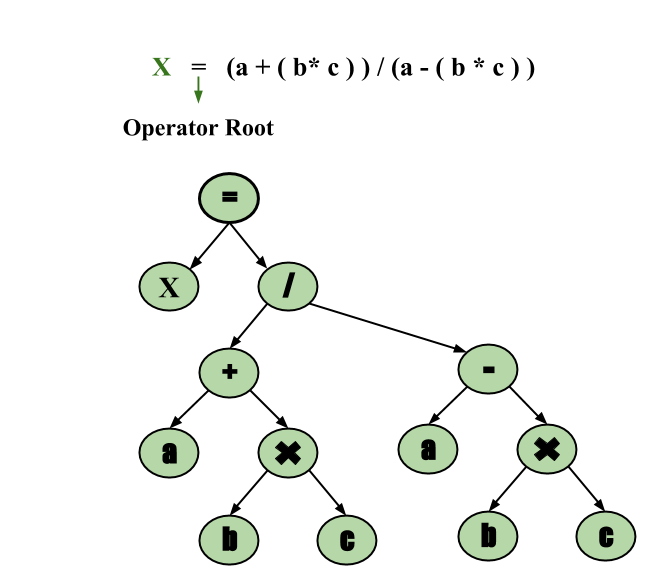
- 语法树 –
语法树只不过是分析树的精简形式。解析树的运算符和关键字节点被移动到它们的父节点,并且单个产生式链被语法树中的单个链接替换,内部节点是运算符,子节点是操作数。为了形成语法树,将括号放在表达式中,这样很容易识别哪个操作数应该先出现。例子 –
x = (a + b * c) / (a – b * c)