您可能首先喜欢阅读:Google 搜索的工作原理!
现在让我们来看看一些重要的术语:
搜索引擎:在数据库中搜索和识别与用户指定的关键字或字符相对应的项目的程序,特别用于在万维网上查找特定站点。
示例:谷歌搜索引擎、雅虎、必应等。
搜索引擎索引:搜索引擎索引是一个将关键字和网站相关联的数据库,以便搜索引擎可以显示与用户搜索查询相匹配的网站。
例如,如果用户搜索猎豹运行速度,则软件蜘蛛在搜索引擎索引中搜索这些词。
网络爬虫:首先需要了解的是网络爬虫或蜘蛛是什么以及它是如何工作的。搜索引擎蜘蛛(也称为爬虫、机器人、SearchBot 或简称为机器人)是大多数搜索引擎用来查找 Internet 上的新内容的程序。 Google 的网络爬虫称为 GoogleBot。该程序从一个网站开始,并跟踪每个页面上的每个超链接。
所以可以说网络上的所有东西最终都会被发现并被蜘蛛抓取,就像所谓的“蜘蛛”从一个网站爬到另一个网站一样。当网络爬虫访问您的一个页面时,它会将站点的内容加载到数据库中。获取页面后,页面的文本将加载到搜索引擎的索引中,这是一个庞大的单词数据库,以及它们出现在不同网页上的位置。
Robots.txt 文件:网络爬虫在未经批准的情况下在少数网站上爬行。因此,每个网站都包含一个 robots.txt 文件,其中包含蜘蛛(网络爬虫)对网站的哪些部分进行索引以及哪些部分要忽略的说明。
PageRank算法
PageRank 通过计算页面链接的数量和质量来粗略估计网页的重要性。当网络爬虫遍历每个网站时,它会跟踪网站中的所有链接,并检查有多少链接连接到每个网站。然后它使用页面排名算法为每个网页分配百分比,代表网页的重要性。例如,如果有名为 A、B 和 C 的三个网页。假设如果连接到 B 的链接数来自五个百分比较低的网页,而到 C 网页的链接来自百分比较高的 A,因为一个到 C 的链接来自一个重要页面,因此 C 的价值高于 B。
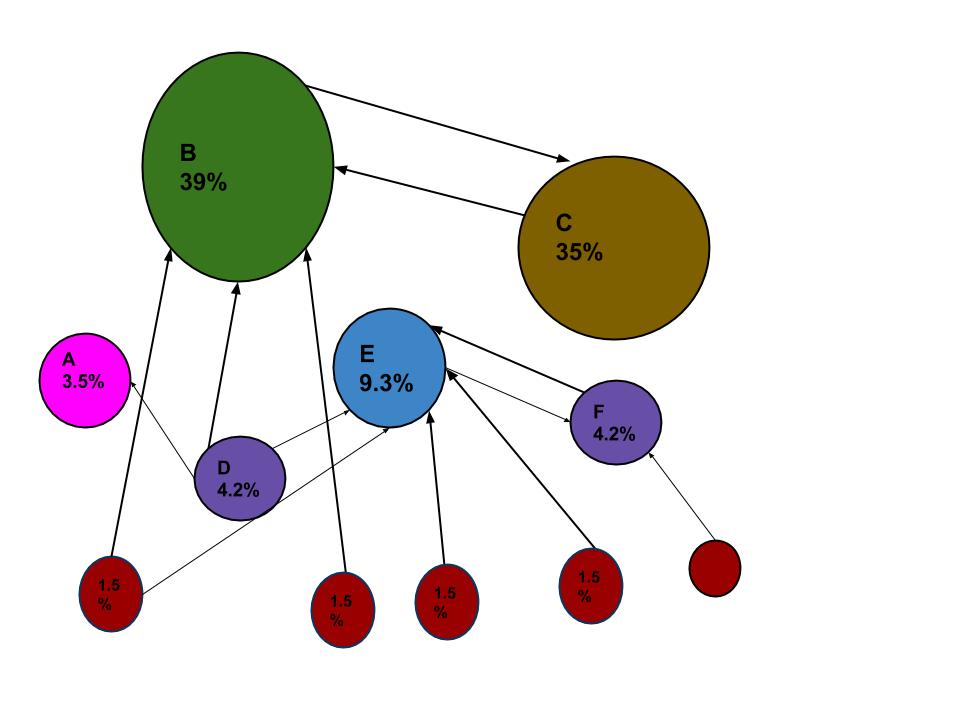
上图改编自维基百科。
URL 图中的 PageRank 是一个概率分布,用于表示一个人随机点击链接到达任何特定页面的可能性。
因此,网络爬行过程基本上涉及三个步骤。首先,搜索机器人首先抓取您网站的页面。然后它继续索引站点的词和内容,最后它访问在您站点中找到的链接(网页地址或 URL)。
“robots.txt”的重要性
蜘蛛在访问您的网站时应该做的第一件事是查找名为“robots.txt”的文件。该文件包含蜘蛛程序对网站的哪些部分进行索引以及忽略哪些部分的说明。控制蜘蛛在您网站上看到的内容的唯一方法是使用 robots.txt 文件。所有的蜘蛛都应该遵循一些规则,主要的搜索引擎大部分都遵循这些规则。幸运的是,像谷歌或必应这样的主要搜索引擎终于在标准上合作。
当您搜索时,蜘蛛搜索索引以查找包含这些搜索词的每个页面。在这种情况下,它会找到成百上千的页面,然后谷歌通过询问超过 200 个这样的问题来决定哪些文件是真正需要的:
- 页面包含该关键字多少次?
- 这些词是否出现在标题、URL 中,直接相邻?
- 该页面是否包含这些词的同义词?
- 此页面是优质网站还是低质量网站?
然后它获取数百个网页,并使用 PageRank 算法对这些网页的重要性进行排名,该算法查看指向它的外部链接的数量以及这些链接的重要性?最后,它将所有这些因素结合在一起,生成每个页面的总分,并在提交搜索后约半秒内将搜索结果发回。
每个页面都包含标题、URL、文本片段,以决定我们正在寻找的特定页面。如果不相关,它还会在页面底部显示相关搜索。
相关文章:
- Facebook 如何为您搜索的内容展示广告
- 搜索引擎优化 (SEO) |基本
- 谷歌如何自我更新
重要链接:
- http://pr.efactory.de/e-pagerank-algorithm.shtml