- 排名 (1)
- sql中的排名函数(1)
- MySQL |排名功能(1)
- MySQL |排名功能
- sql代码示例中的排名函数
- 排名 - 任何代码示例
- 排名 - 无论代码示例
- pandas 列排名 - Python (1)
- QlikView-排名函数(1)
- QlikView-排名函数
- pandas 列排名 - Python 代码示例
- MySQL函数
- MySQL函数(1)
- 如何在C#中查找数组的排名(1)
- 如何在C#中查找数组的排名
- 矩阵排名程序(1)
- 矩阵排名程序
- Python - 元素的索引排名
- Python - 元素的索引排名(1)
- 计算N名学生的排名方法,以使相同的排名成为可能(1)
- 计算N名学生的排名方法,以使相同的排名成为可能
- 多标签排名指标 - 排名损失 |机器学习(1)
- 多标签排名指标 - 排名损失 |机器学习
- python 数据框添加排名列 - Python (1)
- 箭头函数黑客排名 - 任何代码示例
- Pyspark 中的排名 - 无论代码示例
- Android中排名前5的图像加载库(1)
- Android中排名前5的图像加载库
- python 数据框添加排名列 - Python 代码示例
📅 最后修改于: 2020-11-19 00:59:51 🧑 作者: Mango
MySQL排名函数
MySQL使用一种排名功能,该函数使我们能够对数据库中分区的每一行进行排名。排名函数还是MySQL窗口函数的一部分。 MySQL中的排名函数可以与以下子句一起使用:
- 他们总是使用OVER()
- 他们基于ORDER BY为每行分配一个等级
- 他们按顺序为每行分配一个等级。
- 他们总是为行分配一个等级,每个新分区都以一个等级开始。
注意:请注意,自8.0版起,MySQL提供了对排名和窗口函数的支持。
MySQL支持以下三种类型的排名函数:
- 密集等级
- 秩
- 排名百分比
现在,我们将详细讨论每个排名函数:
MySQL的密集_排名()
它是一项函数,可为分区或结果集中的每一行分配等级,而不会出现任何间隔。行的级别始终按连续顺序分配(从上一行开始增加一个)。有时,您会在值之间得到一个平局,然后density_rank会为其分配相同的等级,其下一个等级将是其下一个连续数字。
以下是density_rank()的语法:
SELECT column_name
DENSE_RANK() OVER (
PARTITION BY expression
ORDER BY expression [ASC|DESC])
AS 'my_rank' FROM table_name;
在以上语法中,PARTITION BY子句对结果集按FROM子句进行分区,然后在每个分区上应用density_rank函数。接下来,ORDER BY子句将应用于每个分区以指定行的顺序。
例子1
让我们了解MySQL density_rank()函数的工作方式。因此,首先,创建一个包含以下数据的表:
表:员工

该语句使用density_rank()函数为每一行分配等级值。
SELECT emp_id, emp_name, city, emp_age,
DENSE_RANK() OVER (ORDER BY emp_age) dens_rank
FROM employees;
执行以上语句后,我们将获得以下输出:
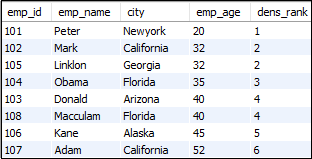
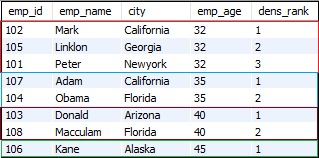
例子2
让我们看另一个将结果集划分为多个分区的示例。以下语句使用density_rank()函数在每一行上分配值,并使用emp_age将结果集划分为分区:
SELECT emp_id, emp_name, city, emp_age,
DENSE_RANK() OVER (PARTITION BY emp_age ORDER BY city) dens_rank
FROM employees;
成功执行以上查询后,我们将获得以下输出:
MySQL等级()
它是一项函数,可为分区或结果集中带有间隙的每一行分配等级。行的等级始终不按连续顺序分配(即,与前一行相比增加1)。有时,您会在值之间产生联系,然后rank()函数将为其分配相同的排名,而下一个排名值将是其上一个排名加上多个重复数字。
以下是rank()的语法:
SELECT column_name
RANK() OVER (
PARTITION BY expression
ORDER BY expression [ASC|DESC])
AS 'my_rank' FROM table_name;
在上面的语法中,PARTITION BY子句对结果集按FROM子句进行分区,然后rank()函数应用于每个分区,并在分区边界与其他分区交叉时重新初始化。接下来,ORDER BY子句应用于每个分区,以基于一个或多个列名称对行进行排序。
让我们看一下我们先前创建的表,并通过不同的示例了解MySQL中rank()函数的工作方式。
表:员工
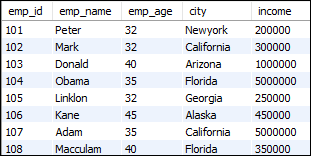
例子1
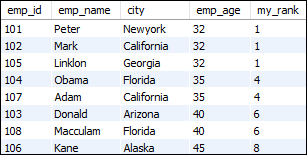
该语句使用rank()函数为每一行分配等级值。
SELECT emp_id, emp_name, city, emp_age,
RANK() OVER (ORDER BY emp_age) my_rank
FROM employees;
上面的查询将给出以下输出:
例子2
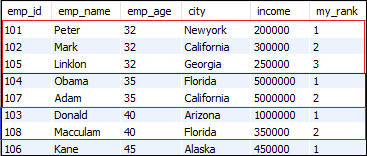
让我们看另一个将结果集划分为多个分区的示例。以下语句使用rank()函数在每一行上分配值,并使用emp_age将结果集划分为分区,并根据emp_id对它们进行排序:
SELECT *,
RANK() OVER (PARTITION BY emp_age ORDER BY emp_id) my_rank
FROM employees;
执行上面的语句,我们将得到以下输出:
MySQL percent_rank()
它是一项函数,用于计算分区或结果集中的行的百分位等级(相对等级)。此函数返回一个介于0到1之间的数字。
以下是percent_rank()的语法:
SELECT column_name
PERCENT_RANK() OVER (
PARTITION BY expression
ORDER BY expression [ASC|DESC])
AS 'my_rank' FROM table_name;
对于指定的行,此函数使用以下公式计算等级:
(rank-1) / ( total_rows-1)
这里,
rank:是由rank()函数返回的每一行的排名。
total_rows:表示分区中存在的总行数。
注意:这是确保使用此函数,必须必须使用ORDER BY子句。否则,所有行均被视为重复行,并分配相同的等级,即1。
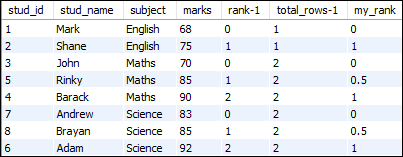
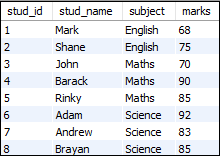
让我们创建一个包含以下数据的“学生”表,并查看MySQL中percent_rank()函数的工作情况。
表:学生
例子1
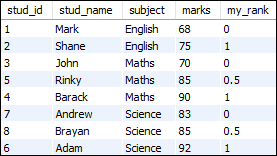
该语句使用percent_rank()函数来为按标记列的每个行顺序计算等级值。
SELECT stud_id, stud_name, subject, marks,
PERCENT_RANK() OVER (PARTITION BY subject ORDER BY marks) my_rank
FROM students;
上面的查询将给出以下输出:
若要查看上述公式的工作原理,请考虑以下查询:
SELECT stud_id, stud_name, subject, marks, rank()
OVER ( partition by subject order by marks )-1
AS 'rank-1', count(*) over (partition by subject)-1
AS 'total_rows-1',
PERCENT_RANK() OVER (PARTITION BY subject ORDER BY marks) my_rank
FROM students;
它将给出以下输出: