假设你在 Geekbook 上创建一个帐户,你想输入一个很酷的用户名,你输入它并收到一条消息,“用户名已经被占用”。您在用户名中添加了您的出生日期,但仍然没有运气。现在你也添加了你的大学卷号,仍然得到“用户名已经被占用”。这真的很令人沮丧,不是吗?
但是你有没有想过 Geekbook 通过搜索数百万个注册的用户名来检查用户名的可用性有多快。有很多方法可以完成这项工作——
- 线性搜索:坏主意!
- 二分查找:按字母顺序存储所有用户名并将输入的用户名与列表中的中间名进行比较,如果匹配,则取用户名,否则判断输入的用户名是在中间名之前还是之后,如果在后,则忽略所有用户名在中间(含)之前。现在搜索中间一个并重复这个过程,直到你得到匹配或搜索结束而没有匹配。这种技术更好而且很有前途,但它仍然需要多个步骤。
但是,一定有更好的东西!!
布隆过滤器是一种可以完成这项工作的数据结构。
为了理解布隆过滤器,你必须知道什么是散列。散列函数接受输入并输出固定长度的唯一标识符,用于识别输入。
什么是布隆过滤器?
布隆过滤器是一种节省空间的概率数据结构,用于测试元素是否是集合的成员。例如,检查用户名的可用性是集合成员资格问题,其中集合是所有注册用户名的列表。我们为效率付出的代价是它本质上是概率性的,这意味着可能会有一些误报结果。误报意味着,它可能会告诉给定的用户名已经被占用,但实际上并没有。
布隆过滤器的有趣特性
- 与标准哈希表不同,固定大小的布隆过滤器可以表示具有任意数量元素的集合。
- 添加元素永远不会失败。但是,随着元素的添加,误报率稳步上升,直到过滤器中的所有位都设置为 1,此时所有查询都会产生积极的结果。
- 布隆过滤器永远不会产生假阴性结果,即告诉您用户名实际上存在时不存在。
- 从过滤器中删除元素是不可能的,因为如果我们通过清除 k 个哈希函数生成的索引处的位来删除单个元素,可能会导致删除其他几个元素。示例 – 如果我们通过清除 1、4 和 7 处的位来删除“极客”(在下面给出的示例中),我们最终可能也会删除“书呆子”,因为索引 4 处的位变为 0 并且布隆过滤器声称“书呆子”不是当下。
布隆过滤器的工作
一个空的布隆过滤器是一个由m位组成的位数组,都设置为零,就像这样——

我们需要k个散列函数来计算给定输入的散列。当我们想在过滤器中添加一个项目时,k 个索引 h1(x), h2(x), … hk(x) 处的位被设置,其中索引是使用哈希函数计算的。
示例 – 假设我们想在过滤器中输入“geeks”,我们使用 3 个哈希函数和一个长度为 10 的位数组,最初都设置为 0。首先,我们将按如下方式计算哈希值:
h1(“geeks”) % 10 = 1
h2(“geeks”) % 10 = 4
h3(“geeks”) % 10 = 7注意:这些输出是随机的,仅供解释。
现在我们将索引 1、4 和 7 处的位设置为 1
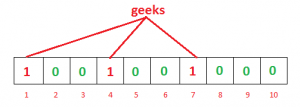
我们再次输入“nerd”,同样我们将计算哈希值
h1(“nerd”) % 10 = 3
h2(“nerd”) % 10 = 5
h3(“nerd”) % 10 = 4将索引 3、5 和 4 处的位设置为 1
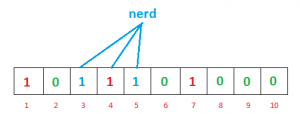
现在,如果我们想检查过滤器中是否存在“极客”。我们将执行相同的过程,但这次以相反的顺序进行。我们使用 h1、h2 和 h3 计算各自的哈希值,并检查位数组中的所有这些索引是否都设置为 1。如果设置了所有位,那么我们可以说“极客”可能存在。如果这些索引中的任何位为 0,那么“极客”肯定不存在。
布隆过滤器中的误报
问题是我们为什么说“可能存在” ,为什么会有这种不确定性。让我们通过一个例子来理解这一点。假设我们要检查“cat”是否存在。我们将使用 h1、h2 和 h3 计算哈希
h1(“cat”) % 10 = 1
h2(“cat”) % 10 = 3
h3(“cat”) % 10 = 7如果我们检查位数组,这些索引处的位被设置为 1,但我们知道“cat”从未添加到过滤器中。索引 1 和 7 的位在我们添加“geeks”时被设置,位 3 被设置我们添加了“nerd”。
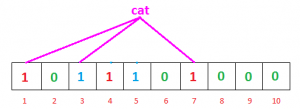
因此,由于计算索引处的位已经由某个其他项设置,布隆过滤器错误地声称存在“猫”并生成误报结果。根据应用程序的不同,它可能有很大的缺点,也可能相对还好。
我们可以通过控制布隆过滤器的大小来控制得到误报的概率。更多的空间意味着更少的误报。如果我们想要降低误报结果的概率,我们必须使用更多数量的哈希函数和更大的位数组。除了项目和检查成员资格之外,这会增加延迟。
布隆过滤器支持的操作
- insert(x) :在布隆过滤器中插入一个元素。
- lookup(x) :检查一个元素是否已经以正误概率出现在布隆过滤器中。
注意:我们无法删除布隆过滤器中的元素。
误报概率:设m为位数组的大小,k 为散列函数的数量, n为预期插入过滤器的元素数,则误报概率p可计算为:
位数组的大小:如果已知元素的预期数量n并且所需的误报概率为p,则位数组m的大小可以计算为:
散列函数的最佳数量:散列函数的数量k必须是一个正整数。如果m是位数组的大小, n是要插入的元素数,则 k 可以计算为:
空间效率
如果我们想在集合中存储大型项目列表以用于集合成员资格,我们可以将其存储在哈希映射、尝试或简单数组或链表中。所有这些方法都需要存储项目本身,这不是非常有效的内存。例如,如果我们想在 hashmap 中存储“geeks”,我们必须将实际字符串“geeks”存储为键值对 {some_key : ”geeks”}。
布隆过滤器根本不存储数据项。正如我们所见,他们使用允许哈希冲突的位数组。如果没有哈希冲突,它就不会紧凑。
哈希函数的选择
布隆过滤器中使用的哈希函数应该是独立且均匀分布的。他们应该尽可能快。足够独立的快速简单的非加密哈希包括 murmur、FNV 系列哈希函数和Jenkins哈希。
生成哈希是布隆过滤器中的主要操作。加密散列函数提供稳定性和保证,但计算成本高。随着哈希函数 k 数量的增加,布隆过滤器变慢。尽管非加密哈希函数不提供保证,但提供了重大的性能改进。
Python3 中布隆过滤器类的基本实现。将其另存为bloomfilter.py
Python
# Python 3 program to build Bloom Filter
# Install mmh3 and bitarray 3rd party module first
# pip install mmh3
# pip install bitarray
import math
import mmh3
from bitarray import bitarray
class BloomFilter(object):
'''
Class for Bloom filter, using murmur3 hash function
'''
def __init__(self, items_count, fp_prob):
'''
items_count : int
Number of items expected to be stored in bloom filter
fp_prob : float
False Positive probability in decimal
'''
# False possible probability in decimal
self.fp_prob = fp_prob
# Size of bit array to use
self.size = self.get_size(items_count, fp_prob)
# number of hash functions to use
self.hash_count = self.get_hash_count(self.size, items_count)
# Bit array of given size
self.bit_array = bitarray(self.size)
# initialize all bits as 0
self.bit_array.setall(0)
def add(self, item):
'''
Add an item in the filter
'''
digests = []
for i in range(self.hash_count):
# create digest for given item.
# i work as seed to mmh3.hash() function
# With different seed, digest created is different
digest = mmh3.hash(item, i) % self.size
digests.append(digest)
# set the bit True in bit_array
self.bit_array[digest] = True
def check(self, item):
'''
Check for existence of an item in filter
'''
for i in range(self.hash_count):
digest = mmh3.hash(item, i) % self.size
if self.bit_array[digest] == False:
# if any of bit is False then,its not present
# in filter
# else there is probability that it exist
return False
return True
@classmethod
def get_size(self, n, p):
'''
Return the size of bit array(m) to used using
following formula
m = -(n * lg(p)) / (lg(2)^2)
n : int
number of items expected to be stored in filter
p : float
False Positive probability in decimal
'''
m = -(n * math.log(p))/(math.log(2)**2)
return int(m)
@classmethod
def get_hash_count(self, m, n):
'''
Return the hash function(k) to be used using
following formula
k = (m/n) * lg(2)
m : int
size of bit array
n : int
number of items expected to be stored in filter
'''
k = (m/n) * math.log(2)
return int(k)Python
from bloomfilter import BloomFilter
from random import shuffle
n = 20 #no of items to add
p = 0.05 #false positive probability
bloomf = BloomFilter(n,p)
print("Size of bit array:{}".format(bloomf.size))
print("False positive Probability:{}".format(bloomf.fp_prob))
print("Number of hash functions:{}".format(bloomf.hash_count))
# words to be added
word_present = ['abound','abounds','abundance','abundant','accessable',
'bloom','blossom','bolster','bonny','bonus','bonuses',
'coherent','cohesive','colorful','comely','comfort',
'gems','generosity','generous','generously','genial']
# word not added
word_absent = ['bluff','cheater','hate','war','humanity',
'racism','hurt','nuke','gloomy','facebook',
'geeksforgeeks','twitter']
for item in word_present:
bloomf.add(item)
shuffle(word_present)
shuffle(word_absent)
test_words = word_present[:10] + word_absent
shuffle(test_words)
for word in test_words:
if bloomf.check(word):
if word in word_absent:
print("'{}' is a false positive!".format(word))
else:
print("'{}' is probably present!".format(word))
else:
print("'{}' is definitely not present!".format(word))C++
#include
#define ll long long
using namespace std;
// hash 1
int h1(string s, int arrSize)
{
ll int hash = 0;
for (int i = 0; i < s.size(); i++)
{
hash = (hash + ((int)s[i]));
hash = hash % arrSize;
}
return hash;
}
// hash 2
int h2(string s, int arrSize)
{
ll int hash = 1;
for (int i = 0; i < s.size(); i++)
{
hash = hash + pow(19, i) * s[i];
hash = hash % arrSize;
}
return hash % arrSize;
}
// hash 3
int h3(string s, int arrSize)
{
ll int hash = 7;
for (int i = 0; i < s.size(); i++)
{
hash = (hash * 31 + s[i]) % arrSize;
}
return hash % arrSize;
}
// hash 4
int h4(string s, int arrSize)
{
ll int hash = 3;
int p = 7;
for (int i = 0; i < s.size(); i++) {
hash += hash * 7 + s[0] * pow(p, i);
hash = hash % arrSize;
}
return hash;
}
// loookup operation
bool lookup(bool* bitarray, int arrSize, string s)
{
int a = h1(s, arrSize);
int b = h2(s, arrSize);
int c = h3(s, arrSize);
int d = h4(s, arrSize);
if (bitarray[a] && bitarray[b] && bitarray
&& bitarray[d])
return true;
else
return false;
}
// insert operation
void insert(bool* bitarray, int arrSize, string s)
{
// check if the element in already present or not
if (lookup(bitarray, arrSize, s))
cout << s << " is Probably already present" << endl;
else
{
int a = h1(s, arrSize);
int b = h2(s, arrSize);
int c = h3(s, arrSize);
int d = h4(s, arrSize);
bitarray[a] = true;
bitarray[b] = true;
bitarray = true;
bitarray[d] = true;
cout << s << " inserted" << endl;
}
}
// Driver Code
int main()
{
bool bitarray[100] = { false };
int arrSize = 100;
string sarray[33]
= { "abound", "abounds", "abundance",
"abundant", "accessable", "bloom",
"blossom", "bolster", "bonny",
"bonus", "bonuses", "coherent",
"cohesive", "colorful", "comely",
"comfort", "gems", "generosity",
"generous", "generously", "genial",
"bluff", "cheater", "hate",
"war", "humanity", "racism",
"hurt", "nuke", "gloomy",
"facebook", "geeksforgeeks", "twitter" };
for (int i = 0; i < 33; i++) {
insert(bitarray, arrSize, sarray[i]);
}
return 0;
} 让我们测试布隆过滤器。将此文件另存为bloom_test.py
Python
from bloomfilter import BloomFilter
from random import shuffle
n = 20 #no of items to add
p = 0.05 #false positive probability
bloomf = BloomFilter(n,p)
print("Size of bit array:{}".format(bloomf.size))
print("False positive Probability:{}".format(bloomf.fp_prob))
print("Number of hash functions:{}".format(bloomf.hash_count))
# words to be added
word_present = ['abound','abounds','abundance','abundant','accessable',
'bloom','blossom','bolster','bonny','bonus','bonuses',
'coherent','cohesive','colorful','comely','comfort',
'gems','generosity','generous','generously','genial']
# word not added
word_absent = ['bluff','cheater','hate','war','humanity',
'racism','hurt','nuke','gloomy','facebook',
'geeksforgeeks','twitter']
for item in word_present:
bloomf.add(item)
shuffle(word_present)
shuffle(word_absent)
test_words = word_present[:10] + word_absent
shuffle(test_words)
for word in test_words:
if bloomf.check(word):
if word in word_absent:
print("'{}' is a false positive!".format(word))
else:
print("'{}' is probably present!".format(word))
else:
print("'{}' is definitely not present!".format(word))
输出
Size of bit array:124
False positive Probability:0.05
Number of hash functions:4
'war' is definitely not present!
'gloomy' is definitely not present!
'humanity' is definitely not present!
'abundant' is probably present!
'bloom' is probably present!
'coherent' is probably present!
'cohesive' is probably present!
'bluff' is definitely not present!
'bolster' is probably present!
'hate' is definitely not present!
'racism' is definitely not present!
'bonus' is probably present!
'abounds' is probably present!
'genial' is probably present!
'geeksforgeeks' is definitely not present!
'nuke' is definitely not present!
'hurt' is definitely not present!
'twitter' is a false positive!
'cheater' is definitely not present!
'generosity' is probably present!
'facebook' is definitely not present!
'abundance' is probably present!C++ 实现
这是具有 4 个样本哈希函数 (k = 4) 且位数组大小为 100 的样本布隆过滤器的实现。
C++
#include
#define ll long long
using namespace std;
// hash 1
int h1(string s, int arrSize)
{
ll int hash = 0;
for (int i = 0; i < s.size(); i++)
{
hash = (hash + ((int)s[i]));
hash = hash % arrSize;
}
return hash;
}
// hash 2
int h2(string s, int arrSize)
{
ll int hash = 1;
for (int i = 0; i < s.size(); i++)
{
hash = hash + pow(19, i) * s[i];
hash = hash % arrSize;
}
return hash % arrSize;
}
// hash 3
int h3(string s, int arrSize)
{
ll int hash = 7;
for (int i = 0; i < s.size(); i++)
{
hash = (hash * 31 + s[i]) % arrSize;
}
return hash % arrSize;
}
// hash 4
int h4(string s, int arrSize)
{
ll int hash = 3;
int p = 7;
for (int i = 0; i < s.size(); i++) {
hash += hash * 7 + s[0] * pow(p, i);
hash = hash % arrSize;
}
return hash;
}
// loookup operation
bool lookup(bool* bitarray, int arrSize, string s)
{
int a = h1(s, arrSize);
int b = h2(s, arrSize);
int c = h3(s, arrSize);
int d = h4(s, arrSize);
if (bitarray[a] && bitarray[b] && bitarray
&& bitarray[d])
return true;
else
return false;
}
// insert operation
void insert(bool* bitarray, int arrSize, string s)
{
// check if the element in already present or not
if (lookup(bitarray, arrSize, s))
cout << s << " is Probably already present" << endl;
else
{
int a = h1(s, arrSize);
int b = h2(s, arrSize);
int c = h3(s, arrSize);
int d = h4(s, arrSize);
bitarray[a] = true;
bitarray[b] = true;
bitarray = true;
bitarray[d] = true;
cout << s << " inserted" << endl;
}
}
// Driver Code
int main()
{
bool bitarray[100] = { false };
int arrSize = 100;
string sarray[33]
= { "abound", "abounds", "abundance",
"abundant", "accessable", "bloom",
"blossom", "bolster", "bonny",
"bonus", "bonuses", "coherent",
"cohesive", "colorful", "comely",
"comfort", "gems", "generosity",
"generous", "generously", "genial",
"bluff", "cheater", "hate",
"war", "humanity", "racism",
"hurt", "nuke", "gloomy",
"facebook", "geeksforgeeks", "twitter" };
for (int i = 0; i < 33; i++) {
insert(bitarray, arrSize, sarray[i]);
}
return 0;
}
abound inserted
abounds inserted
abundance inserted
abundant inserted
accessable inserted
bloom inserted
blossom inserted
bolster inserted
bonny inserted
bonus inserted
bonuses inserted
coherent inserted
cohesive inserted
colorful inserted
comely inserted
comfort inserted
gems inserted
generosity inserted
generous inserted
generously inserted
genial inserted
bluff is Probably already present
cheater inserted
hate inserted
war is Probably already present
humanity inserted
racism inserted
hurt inserted
nuke is Probably already present
gloomy is Probably already present
facebook inserted
geeksforgeeks inserted
twitter inserted布隆过滤器的应用
- Medium 使用布隆过滤器通过过滤用户看到的帖子向用户推荐帖子。
- Quora 在 Feed 后端实现了一个共享的布隆过滤器,以过滤掉人们以前看过的故事。
- 曾经使用 Bloom 过滤器来识别恶意 URL 的 Google Chrome 网络浏览器
- Google BigTable、Apache HBase 和 Apache Cassandra 以及 Postgresql 使用 Bloom 过滤器来减少对不存在的行或列的磁盘查找
参考
- https://en.wikipedia.org/wiki/Bloom_filter
- https://blog.medium.com/what-are-bloom-filters-1ec2a50c68ff
- https://www.quora.com/What-are-the-best-applications-of-Bloom-filters