Kafka 自动化使用Python和真实世界示例
Apache Kafka 是一个发布-订阅消息队列,用于实时数据流。 Apache Kafka 允许您在各种微服务之间发送和接收消息。为基于 Kafka 的微服务项目开发可扩展且可靠的自动化框架有时可能具有挑战性。
在本文中,我们将了解如何使用Python为微服务架构设计 Kafka 自动化框架。
先决条件:
- 微服务架构基础知识。
- 熟悉 Kafka 基本概念(例如 Kafka 主题、代理、分区、偏移量、生产者、消费者等)。
- 良好的Python基础知识(pip install
,编写Python方法)。
解决方案 :
我们将通过 Kafka 自动化的真实世界场景来了解技术挑战并尝试设计我们的自动化解决方案。让我们假设我们正在开发一个如下图所示的数据管道项目。我们想为此开发一个自动化框架。
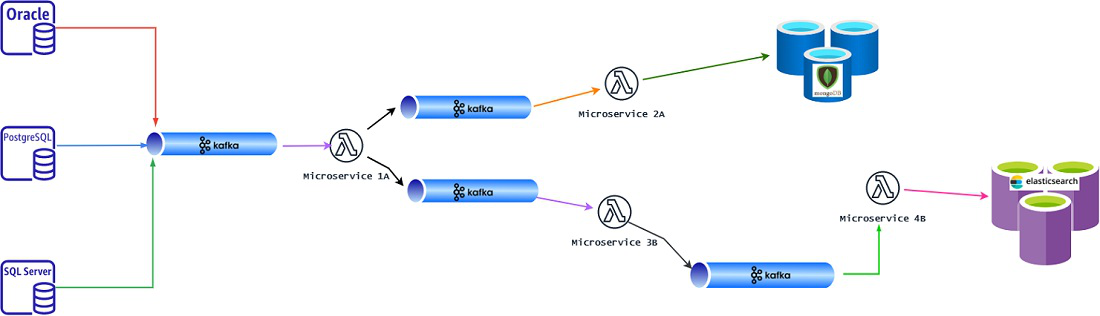
各种事件(数据)来自多个数据库到我们的 Kafka 主题。 “微服务 1A”使用所有此类传入消息并进行一些处理并在不同的 Kafka 主题中生成输出。
“微服务 1A”的输出根据不同的需求分为 2 个不同的 Kafka Topic。现在,“微服务 2A”消费“微服务 1A”的其中一个 Output Topic,然后对数据进行一些复杂的逻辑处理,并将最终的数据发送到 MongoDB 集群。
或者,“微服务 3B”从微服务 1A 的另一个输出主题中消费”,然后,进行更多处理并将输出数据发布到下一个 Kafka 主题中。
“微服务 4B” 使用这些数据,经过更多处理后,将最终数据发送到 ElasticSearch 集群。
我们正在尝试设计一个自动化框架来验证这 4 个微服务的所有输入和输出。 (这些微服务可以用任何技术栈编写,如Java+SpringBoot 或 C# DotNet 或Python+Django。)
我们将使用Python设计我们的自动化框架。
现在,让我们根据对上述系统设计的理解来总结几个要点。
- 我们需要为我们的自动化框架选择一个合适的 Kafka 库。
- 我们需要开发 Kafka 自动化的基本构建块,即具有适当 Kafka 配置的 Kafka Consumer。
- 我们需要谨慎使用适当的 Kafka Offset 提交机制来正确测试数据。
- 如果在自动化执行期间发生 Kafka Partition Rebalance,我们需要小心处理。
- 我们需要为未来的可扩展性需求设计我们的测试用例。 (即 1 个 Kafka Topic 可能包含 6 个分区,它们在这 6 个分区中并行发送不同类型的数据。我们可以为这 6 个分区中的每一个执行 6 个并行自动化 TC)
适用于Python的流行 Kafka 库:
在使用Python开发 Kafka 自动化时,我们在 Internet 上有 3 个流行的库选择。
- 派卡夫卡
- 卡夫卡蟒蛇
- 融合的卡夫卡
这些库中的每一个都有自己的优点和缺点,因此我们将根据我们的项目要求进行选择。
与 Internet 上的大多数 Kafka Python教程不同,我们不会在 localhost 上工作。相反,我们将尝试使用 SSL 身份验证连接到远程 Kafka 集群。
对于内部微服务(不暴露给面向 Internet 的最终用户)我们将把 SSL 视为一种流行的 Kafka 集群身份验证机制。大多数公司使用 Confluent Kafka 集群或 Amazon MSK 集群(Managed Streaming Kafka 基于 Apache Kafka)。
为了连接到 Kafka 集群,我们从基础设施支持团队获得了 1 个 JKS 文件和一个用于此 JKS 文件的密码。所以我们的工作是将这个 JKS 文件转换成适当的格式(正如Python Kafka 库所期望的那样)。
选择哪个卡夫卡图书馆?
如果我们使用的是 Amazon MSK 集群,那么我们可以使用 PyKafka 或 Kafka-python(两者都是开源的,并且在 Apache Kafka 自动化中最受欢迎)来构建我们的自动化框架。如果我们使用 Confluent Kafka 集群,那么我们必须使用 Confluent Kafka Library,因为我们将获得对 Confluent 特定功能(如 ksqlDB、REST 代理和 Schema Registry)的库支持。我们将使用 Confluent Kafka 库进行Python自动化,因为我们可以使用该库为 Apache Kafka 集群和 Confluent Kafka 集群提供自动化服务。我们需要已经安装了Python 3.x 和 Pip。我们可以执行以下命令在我们的系统中安装库。
pip install confluent-kafka我们需要将 JKS 文件(JKS 与Python不兼容)转换为 PKCS12 格式,以便与 Confluent Kafka 库一起使用。
如何将 JKS 转换为 PKCS12?
系统中应安装 JRE 8 或更高版本。
我们需要在
所以打开CMD提示符,进入JRE_install_path>/bin
第1步: 执行以下命令获取别名:
keytool -list -v -keystore (当被问及我们需要提供我们从基础设施团队收到的 JKS 文件的密码时)
第 2 步:执行以下命令以及我们从第 1 步输出中获得的别名。
keytool -v -importkeystore -srckeystore -srcalias -destkeystore certkey.p12 -deststoretype PKCS12 这将再次询问源密钥库密码,我们必须输入与步骤 1 相同的密码。
执行此命令后,我们将在当前目录中获得 PKCS12 文件(即 certkey.p12 ),我们需要将此文件复制到我们的自动化框架目录中。我们很高兴开始使用Python构建我们的自动化框架。
注意:如果我们计划使用 PyKafka 或 Kafka-python 库而不是 Confluent Kafka,那么我们需要使用一些额外的命令从这个 PKCS12 文件生成 PEM 文件。
使用 SSL 身份验证编写Python Kafka Consumer:
我们将使用上面提到的在 JKS 到 PKCS 转换步骤期间生成的相同 PKCS12 文件。
from confluent_kafka import Consumer
import time
print("Starting Kafka Consumer")
mysecret = "yourjksPassword"
#you can call remote API to get JKS password instead of hardcoding like above
conf = {
'bootstrap.servers' : 'm1.msk.us-east.aws.com:9094, m2.msk.us-east.aws.com:9094, m3.msk.us-east.aws.com:9094',
'group.id' : 'KfConsumer1',
'security.protocol' : 'SSL',
'auto.offset.reset' : 'earliest',
'enable.auto.commit' : True,
'max.poll.records' : 5,
'heartbeat.interval.ms' : 25000,
'max.poll.interval.ms' : 90000,
'session.timeout.ms' : 180000,
'ssl.keystore.password' : mysecret,
'ssl.keystore.location' : './certkey.p12'
}
print("connecting to Kafka topic")
consumer = Consumer(conf)
consumer.subscribe(['kf.topic.name'])
while True:
msg = consumer.poll(1.0)
if msg is None:
continue
if msg.error():
print("Consumer error happened: {}".format(msg.error()))
continue
print("Connected to Topic: {} and Partition : {}".format(msg.topic(), msg.partition() ))
print("Received Message : {} with Offset : {}".format(msg.value().decode('utf-8'), msg.offset() ))
time.sleep(2.5)
#consumer.close()上述代码的示例输出:
Starting Kafka Consumer
connecting to Kafka topic
Connected to Topic: kf.topic.name and Partition : kf.topic.name-0
Received Message : abc101 with Offset : 0
Connected to Topic: kf.topic.name and Partition : kf.topic.name-1
Received Message : xyz201 with Offset : 0
Connected to Topic: kf.topic.name and Partition : kf.topic.name-0
Received Message : abc102 with Offset : 1
Connected to Topic: kf.topic.name and Partition : kf.topic.name-1
Received Message : xyz202 with Offset : 1进一步的步骤:
我们知道如何通过 SSL 身份验证使用来自 Kafka 主题的消息。
展望未来,我们可以添加自己的逻辑来验证 Kafka 主题中的传入消息。
我们可以使用其他更好的偏移管理选项
示例:'enable.auto.commit':假
并添加自定义代码以根据某些条件手动提交消息。
我们可以在多个 Console Window 中同时运行这个程序来观察 Automatic Kafka Rebalance 机制。
示例:如果我们的 Kafka 主题共有 3 个分区,并且我们在 3 个控制台(即 3 个实例)中执行相同的代码
然后,我们可能会看到每个实例被分配了总共 3 个分区中的 1 个分区。
这个特定的配置 'group.id' : 'KfConsumer1' 帮助我们观察上面示例中的 Kafka 分区重新平衡(即所有 3 个实例都具有相同的group.id提到)
结论 :
我们已经获得了 Kafka 自动化的基本构建块,即带有适当 Kafka 配置的 Kafka Python Consumer。因此,我们可以根据我们的项目需求扩展此代码,并继续修改和开发我们的 Kafka 自动化框架。