本文介绍了如何在Python加载和解析 CSV 文件。
首先,什么是 CSV ?
CSV (逗号分隔值)是一种简单的文件格式,用于存储表格数据,例如电子表格或数据库。 CSV 文件以纯文本形式存储表格数据(数字和文本)。文件的每一行都是一条数据记录。每条记录由一个或多个字段组成,以逗号分隔。使用逗号作为字段分隔符是此文件格式名称的来源。
对于在Python处理 CSV 文件,有一个名为csv的内置模块。
读取 CSV 文件
# importing csv module
import csv
# csv file name
filename = "aapl.csv"
# initializing the titles and rows list
fields = []
rows = []
# reading csv file
with open(filename, 'r') as csvfile:
# creating a csv reader object
csvreader = csv.reader(csvfile)
# extracting field names through first row
fields = next(csvreader)
# extracting each data row one by one
for row in csvreader:
rows.append(row)
# get total number of rows
print("Total no. of rows: %d"%(csvreader.line_num))
# printing the field names
print('Field names are:' + ', '.join(field for field in fields))
# printing first 5 rows
print('\nFirst 5 rows are:\n')
for row in rows[:5]:
# parsing each column of a row
for col in row:
print("%10s"%col),
print('\n')
上述程序的输出如下所示:
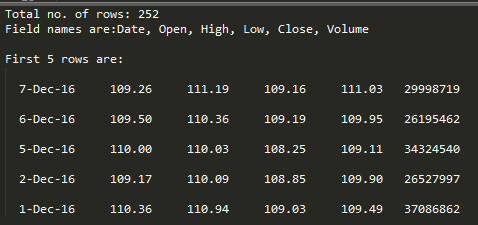
上面的例子使用了一个 CSV 文件 aapl.csv,可以从这里下载。
使用同一目录中的 aapl.csv 文件运行此程序。
让我们试着理解这段代码。
-
with open(filename, 'r') as csvfile: csvreader = csv.reader(csvfile)在这里,我们首先以 READ 模式打开 CSV 文件。文件对象被命名为csvfile 。文件对象被转换为 csv.reader 对象。我们将 csv.reader 对象保存为csvreader 。
-
fields = csvreader.next()csvreader是一个可迭代对象。因此, .next() 方法返回当前行并将迭代器推进到下一行。由于我们的 csv 文件的第一行包含标题(或字段名称),我们将它们保存在一个名为fields的列表中。
-
for row in csvreader: rows.append(row)现在,我们使用 for 循环遍历剩余的行。每行都附加到一个名为rows的列表中。如果您尝试打印每一行,您会发现该行只不过是一个包含所有字段值的列表。
-
print("Total no. of rows: %d"%(csvreader.line_num))csvreader.line_num 只不过是一个计数器,它返回已迭代的行数。
写入 CSV 文件
# importing the csv module
import csv
# field names
fields = ['Name', 'Branch', 'Year', 'CGPA']
# data rows of csv file
rows = [ ['Nikhil', 'COE', '2', '9.0'],
['Sanchit', 'COE', '2', '9.1'],
['Aditya', 'IT', '2', '9.3'],
['Sagar', 'SE', '1', '9.5'],
['Prateek', 'MCE', '3', '7.8'],
['Sahil', 'EP', '2', '9.1']]
# name of csv file
filename = "university_records.csv"
# writing to csv file
with open(filename, 'w') as csvfile:
# creating a csv writer object
csvwriter = csv.writer(csvfile)
# writing the fields
csvwriter.writerow(fields)
# writing the data rows
csvwriter.writerows(rows)
让我们试着分片理解上面的代码。
- 字段和行已经定义。 fields 是一个包含所有字段名称的列表。 rows是一个列表列表。每行都是一个包含该行字段值的列表。
-
with open(filename, 'w') as csvfile: csvwriter = csv.writer(csvfile)在这里,我们首先以 WRITE 模式打开 CSV 文件。文件对象被命名为csvfile 。文件对象被转换为 csv.writer 对象。我们将 csv.writer 对象保存为csvwriter 。
-
csvwriter.writerow(fields)现在我们使用writerow方法来写第一行,它只是字段名称。
-
csvwriter.writerows(rows)我们使用writerows方法一次写入多行。
将字典写入 CSV 文件
# importing the csv module
import csv
# my data rows as dictionary objects
mydict =[{'branch': 'COE', 'cgpa': '9.0', 'name': 'Nikhil', 'year': '2'},
{'branch': 'COE', 'cgpa': '9.1', 'name': 'Sanchit', 'year': '2'},
{'branch': 'IT', 'cgpa': '9.3', 'name': 'Aditya', 'year': '2'},
{'branch': 'SE', 'cgpa': '9.5', 'name': 'Sagar', 'year': '1'},
{'branch': 'MCE', 'cgpa': '7.8', 'name': 'Prateek', 'year': '3'},
{'branch': 'EP', 'cgpa': '9.1', 'name': 'Sahil', 'year': '2'}]
# field names
fields = ['name', 'branch', 'year', 'cgpa']
# name of csv file
filename = "university_records.csv"
# writing to csv file
with open(filename, 'w') as csvfile:
# creating a csv dict writer object
writer = csv.DictWriter(csvfile, fieldnames = fields)
# writing headers (field names)
writer.writeheader()
# writing data rows
writer.writerows(mydict)
在此示例中,我们将字典mydict写入 CSV 文件。
-
with open(filename, 'w') as csvfile: writer = csv.DictWriter(csvfile, fieldnames = fields)在这里,文件对象 ( csvfile ) 被转换为 DictWriter 对象。
在这里,我们将字段名指定为参数。 -
writer.writeheader()writeheader 方法只是使用预先指定的字段名写入 csv 文件的第一行。
-
writer.writerows(mydict)writerows方法只是写入所有行,但在每一行中,它只写入值(而不是键)。
所以,最后,我们的 CSV 文件看起来像这样:
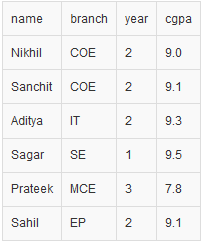
要点:
- 在 csv 模块中,可以给出一个可选的方言参数,用于定义特定于特定CSV 格式的一组参数。默认情况下,csv 模块使用excel方言,这使得它们与 excel 电子表格兼容。您可以使用register_dialect方法定义自己的方言。
下面是一个例子:
csv.register_dialect(
'mydialect',
delimiter = ',',
quotechar = '"',
doublequote = True,
skipinitialspace = True,
lineterminator = '\r\n',
quoting = csv.QUOTE_MINIMAL)现在,在定义 csv.reader 或 csv.writer 对象时,我们可以指定像这样的方言
这:
csvreader = csv.reader(csvfile, dialect='mydialect')- 现在,考虑一个纯文本的 CSV 文件如下所示:

我们注意到分隔符不是逗号而是分号。此外,行由两个换行符而不是一个换行符分隔。在这种情况下,我们可以指定分隔符和行终止符如下:
csvreader = csv.reader(csvfile, delimiter = ';', lineterminator = '\n\n')
因此,这是关于如何在Python程序中加载和解析 CSV 文件的简短而简洁的讨论。本博客由Nikhil Kumar 提供。如果您喜欢 GeeksforGeeks 并愿意做出贡献,您也可以使用 write.geeksforgeeks.org 撰写文章或将您的文章邮寄至 review-team@geeksforgeeks.org。在 GeeksforGeeks 主页上查看您的文章并帮助其他 Geeks。