给定一棵树,以及所有节点的权重(以字符串的形式),任务是计算权重不包含任何重复字符的节点。
例子:
Input:
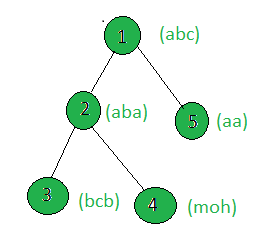
Output: 2
Only the strings of the node 1 and 4 contains unique strings.
方法:在树上执行 dfs,对于每个节点,检查它的字符串包含重复的字符,如果没有,则增加计数。
下面是上述方法的实现:
C++
// C++ implementation of the approach
#include
using namespace std;
int cnt = 0;
vector graph[100];
vector weight(100);
// Function that returns true if the
// string contains unique characters
bool uniqueChars(string x)
{
map mp;
int n = x.size();
for (int i = 0; i < n; i++)
mp[x[i]]++;
if (mp.size() == x.size())
return true;
else
return false;
}
// Function to perform dfs
void dfs(int node, int parent)
{
// If weighted string of the current
// node contains unique characters
if (uniqueChars(weight[node]))
cnt += 1;
for (int to : graph[node]) {
if (to == parent)
continue;
dfs(to, node);
}
}
// Driver code
int main()
{
// Weights of the nodes
weight[1] = "abc";
weight[2] = "aba";
weight[3] = "bcb";
weight[4] = "moh";
weight[5] = "aa";
// Edges of the tree
graph[1].push_back(2);
graph[2].push_back(3);
graph[2].push_back(4);
graph[1].push_back(5);
dfs(1, 1);
cout << cnt;
return 0;
} Java
// Java implementation of the approach
import java.util.*;
class GFG
{
static int cnt = 0;
static Vector[] graph = new Vector[100];
static String[] weight = new String[100];
// Function that returns true if the
// String contains unique characters
static boolean uniqueChars(char[] arr)
{
HashMap mp =
new HashMap();
int n = arr.length;
for (int i = 0; i < n; i++)
if (mp.containsKey(arr[i]))
{
mp.put(arr[i], mp.get(arr[i]) + 1);
}
else
{
mp.put(arr[i], 1);
}
if (mp.size() == arr.length)
return true;
else
return false;
}
// Function to perform dfs
static void dfs(int node, int parent)
{
// If weighted String of the current
// node contains unique characters
if (uniqueChars(weight[node].toCharArray()))
cnt += 1;
for (int to : graph[node])
{
if (to == parent)
continue;
dfs(to, node);
}
}
// Driver code
public static void main(String[] args)
{
for (int i = 0; i < 100; i++)
graph[i] = new Vector();
// Weights of the nodes
weight[1] = "abc";
weight[2] = "aba";
weight[3] = "bcb";
weight[4] = "moh";
weight[5] = "aa";
// Edges of the tree
graph[1].add(2);
graph[2].add(3);
graph[2].add(4);
graph[1].add(5);
dfs(1, 1);
System.out.print(cnt);
}
}
// This code is contributed by Rajput-Ji Python3
# Python3 implementation of the approach
cnt = 0
graph = [[] for i in range(100)]
weight = [0] * 100
# Function that returns true if the
# string contains unique characters
def uniqueChars(x):
mp = {}
n = len(x)
for i in range(n):
if x[i] not in mp:
mp[x[i]] = 0
mp[x[i]] += 1
if (len(mp) == len(x)):
return True
else:
return False
# Function to perform dfs
def dfs(node, parent):
global cnt, x
# If weight of the current node
# node contains unique characters
if (uniqueChars(weight[node])):
cnt += 1
for to in graph[node]:
if (to == parent):
continue
dfs(to, node)
# Driver code
x = 5
# Weights of the node
weight[1] = "abc"
weight[2] = "aba"
weight[3] = "bcb"
weight[4] = "moh"
weight[5] = "aa"
# Edges of the tree
graph[1].append(2)
graph[2].append(3)
graph[2].append(4)
graph[1].append(5)
dfs(1, 1)
print(cnt)
# This code is contributed by SHUBHAMSINGH10C#
// C# implementation of the approach
using System;
using System.Collections.Generic;
class GFG
{
static int cnt = 0;
static List[] graph = new List[100];
static String[] weight = new String[100];
// Function that returns true if the
// String contains unique characters
static bool uniqueChars(char[] arr)
{
Dictionary mp =
new Dictionary();
int n = arr.Length;
for (int i = 0; i < n; i++)
if (mp.ContainsKey(arr[i]))
{
mp[arr[i]] = mp[arr[i]] + 1;
}
else
{
mp.Add(arr[i], 1);
}
if (mp.Count == arr.Length)
return true;
else
return false;
}
// Function to perform dfs
static void dfs(int node, int parent)
{
// If weighted String of the current
// node contains unique characters
if (uniqueChars(weight[node].ToCharArray()))
cnt += 1;
foreach (int to in graph[node])
{
if (to == parent)
continue;
dfs(to, node);
}
}
// Driver code
public static void Main(String[] args)
{
for (int i = 0; i < 100; i++)
graph[i] = new List();
// Weights of the nodes
weight[1] = "abc";
weight[2] = "aba";
weight[3] = "bcb";
weight[4] = "moh";
weight[5] = "aa";
// Edges of the tree
graph[1].Add(2);
graph[2].Add(3);
graph[2].Add(4);
graph[1].Add(5);
dfs(1, 1);
Console.Write(cnt);
}
}
// This code is contributed by PrinciRaj1992 Javascript
输出:
2复杂度分析:
- 时间复杂度: O(N*Len) 其中 Len 是给定树中节点的加权字符串的最大长度。
在 dfs 中,树的每个节点都被处理一次,因此如果树中总共有 N 个节点,则由于 dfs 的复杂性是 O(N)。此外,每个节点的处理都涉及遍历该节点的加权字符串,因此增加了 O(Len) 的复杂度,其中 Len 是加权字符串的长度。因此,时间复杂度为 O(N*Len)。 - 辅助空间: O(1)。
不需要任何额外的空间,因此空间复杂度是恒定的。
如果您希望与专家一起参加现场课程,请参阅DSA 现场工作专业课程和学生竞争性编程现场课程。