Hadoop 是一个开源框架,由ASF — Apache 软件基金会引入。 Hadoop 是复制大数据的最重要框架。 Hadoop 是用Java编写的,但它不是 基于OLAP(在线分析处理) 。这个大数据框架最好的部分是它是可扩展的,可以部署在各种类型的任何类型的数据上,如结构化、非结构化和半结构化类型。 Hadoop 是一种中间件工具,它为我们提供了一个管理大型复杂计算机集群的平台,这些计算机集群是用Java开发的,尽管Java是 Hadoop 的主要编程语言,但其他语言也可以用于 R、 Python或 Ruby。
Hadoop 框架包括:
- Hadoop 分布式文件系统 (HDFS) –它是一个提供强大分布式文件系统的文件系统。 Hadoop 有一个框架,用于作业调度和集群资源管理,其名称为 YARN。
- Hadoop MapReduce –它是 一个用于并行处理大型数据集的系统,它实现了分布式编程的 MapReduce 模型。
Hadoop 借助HDFS扩展了更简单的分布式存储,并通过 MapReduce 提供了分析系统。它具有精心设计的体系结构,可以根据用户的要求将服务器从一台计算机扩展到数百或数千台,具有高度的容错性。 Hadoop 已经证明了其在大数据处理和高效存储管理方面的可靠需求和标准,它提供了无限的可扩展性,并得到了软件行业主要供应商的支持。
众所周知,数据是企业最重要的宝贵财富,如果说数据是最宝贵的资产,一点也不为过。但是为了处理这种庞大的结构化和非结构化我们需要一个有效的工具来有效地进行数据分析,所以我们通过合并R语言和Hadoop大数据分析框架的特性得到这个工具,这种合并结果在它的可扩展性。因此,我们需要将两者结合起来,然后才能从数据中找到更好的见解和结果。很快,我们将介绍有助于整合这两者的各种方法。
R是一种开源编程语言,广泛用于统计和图形分析。 R 支持多种基于统计数学的库(线性和非线性建模、经典统计检验、时间序列分析、数据分类、数据聚类等)和图形技术,可有效处理数据。
R 的一个主要品质是它可以更轻松地生成精心设计的高质量绘图,包括需要的数学符号和公式。如果您正面临强大的数据分析和可视化功能的危机,那么将这种 R 语言与 Hadoop 结合到您的任务中将是您降低复杂性的最后选择。它是一种高度可扩展的面向对象编程语言,具有强大的图形功能。
R 被认为最适合数据分析的一些原因:
- 强大的软件包集合
- 强大的数据可视化技术
- 值得称赞的统计和图形编程功能
- 面向对象的编程语言
- 它具有广泛的智能运算符集合,用于计算数组、特定矩阵等
- 显示器或硬拷贝上的图形表示能力。
R 和 Hadoop 集成背后的主要动机:
毫无疑问,R 是最常用于统计计算、数据图形分析、数据分析和数据可视化的编程语言。另一方面,Hadoop 是一个强大的大数据框架,能够处理大量数据。在所有数据的处理和分析中,Hadoop的分布式文件系统(HDFS)起着至关重要的作用,它在数据处理过程中应用了map-reduce处理方法(由R Hadoop的rmr包提供),这使得数据分析过程更加高效、轻松。
如果两者相互合作会发生什么?显然,数据管理和分析过程的效率将成倍提高。因此,为了在数据分析和可视化过程中具有效率,我们必须将 R 与 Hadoop 结合起来。
加入这两项技术后,R的统计计算能力变得更强,那么我们可以:
- 使用 Hadoop 执行 R 代码。
- 使用 R 访问存储在 Hadoop 中的数据。
几种可以同时集成 R 和 Hadoop 的方法:
最流行和最常选择的方法如下所示,但还有一些其他的 RODBC/RJDBC 可以使用但不流行,如下所示。与 Hadoop 集成的分析工具的总体架构如下所示,其不同的分层结构如下所示。
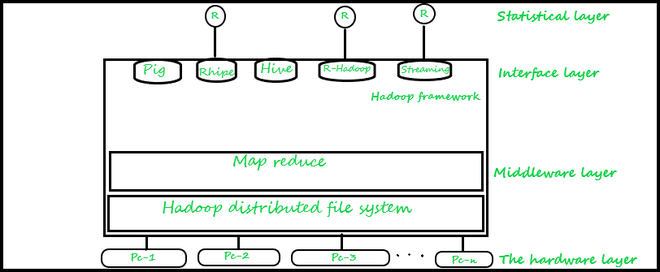
第一层:它是硬件层——它由一组计算机系统组成,
第二层:是 Hadoop的中间件层。该层还通过使用 HDFS 和 MapReduce 作业的功能完美地处理文件的分布。
第三层:为数据分析提供接口的接口层。在这个级别,我们可以使用像 Pig 这样的有效工具,它为我们提供了一个高级平台,用于使用我们称为 Pig-Latin 的语言创建 MapReduce 程序。我们还可以使用Hive ,它是由 Apache 开发并构建在 Hadoop 之上的数据仓库基础架构。 Hive为我们提供了许多用于运行复杂查询的工具,并帮助使用称为 HiveQL 的类似 SQL 的语言来分析数据,它还扩展了对实现 MapReduce 任务的支持。
除了使用Hive和 Pig,我们还可以使用 Rhipe 或 Rhadoop 库来构建接口以提供 Hadoop 和 R 之间的集成,并使用户能够从 Hadoop 文件系统访问数据并允许编写自己的脚本来实现 Map 和 Reduce 作业,或者我们也可以使用 Hadoop-streaming,这是一种用于集成 Hadoop 的技术。
a) R Hadoop: R Hadoop方法包括四个包,分别如下:
- rmr 包 – rmr 包在 R 中提供了 Hadoop MapReduce 功能。因此,R 程序员只需将他们的应用程序的逻辑和想法划分为 map 和 reduce 阶段关联,然后用 rmr 方法提交它。之后,rmr 包通过输入目录、输出目录、reducer、mapper 等多个作业参数调用 Hadoop 流和 MapReduce API,以在 Hadoop 集群(大部分组件)上执行 R MapReduce 作业类似于 Hadoop 流)。
- rhbase 包 –允许 R 开发人员使用 Thrift Server 将 Hadoop HBASE 连接到 R。它还提供诸如(从 R 读取、写入和修改存储在 HBase 中的表)等功能。
使用 RHаdoop 功能的脚本如下图所示。
library(rmr)
map<-function(k,v){...}
reduce<-function(k,vv){...}
mapreduce(
input = "data.txt",
output ="output",
textinputformat = rawtextinputformat,
map = map,
reduce = reduce
)- rhdfs 包 –它在 R 中提供 HDFS 文件管理,因为数据本身存储在 Hadoop 文件系统中。该包的功能如下。 文件操作 -(hdfs.delete、hdfs.rm、hdfs.del、hdfs.chown、hdfs.put、hdfs.get 等),文件读/写 -(hdfs.flush、hdfs.read、hdfs.seek、hdfs。告诉,hdfs.line.reader 等),目录 -hdfs.dircreate,hdfs.mkdir,初始化:hdfs.init,hdfs.defaults。
- plyrmr 包——它提供了诸如数据操作、输出结果汇总、执行集合操作(联合、交集、减法、合并、唯一)等功能。
b) RHIPE : RHIPE 用于R中通过Hadoop对大量数据集进行复杂分析是一种集成的编程环境工具,它是由Divide and Recombine (D&R) 带来的,用于分析海量数据。
RHIPE = R and Hadoop Integrated Programming EnvironmentRHIPE 是一个 R 包,它支持在 Hadoop 中使用 API。因此,我们可以通过这种方式读取、保存使用 RHIPE MapReduce 创建的完整数据。 RHIPE 部署了许多功能,可帮助我们有效地与 HDFS 交互。个人还可以使用 Perl、 Java或Python等各种语言来读取 RHIPE 中的数据集。使用Rhipe的R 脚本的一般结构如下所示。
library(Rhipe)
rhint(TRUE, TRUE);
map<-expression({lapply(map.values, function(mapper)...)})
reduce<-expression(
pre = {...},
reduce = {...},
post = {...}, }
x <- rhmr(
map = map,reduce = reduce,
ifolder = inputPath,
ofolder= outputPath,
inout=c('text','text'),
jobname= 'a job name'))
rhex(z)Rhipe 允许 R 用户使用 R 表达式创建完全在 R 环境中工作的 MapReduce 作业(rmr 包也有助于完成这项工作)。此 MapReduce 功能:允许分析师使用 R 解释语言的全部功能、灵活性和表现力快速指定 Maps 和 Reduces。
c) 用于 Hadoop (ORCH) 的 Oracle R 连接器:
Orch 是提供以下功能的R 包的集合。
- 各种有吸引力的接口来处理Hive表中维护的数据,能够使用基于 Apache Hadoop 的计算基础设施,还提供本地 R 环境和 Oracle 数据库表。
- 我们是一种预测分析技术,用 R 或Java编写为 Hadoop MapReduce 作业,可应用于存储在 HDFS 文件中的数据
在 R 中安装此软件包后,您将能够执行以下各种功能。
- 能够使用支持 Hive 的透明层更轻松地访问和转换 HDFS 数据以供一般用途,
- 我们能够使用 R 语言有效地编写映射器和化简器,
- 将 R 内存之间的数据复制到本地文件系统、HDFS、 Hive和 Oracle 数据库,
- 能够轻松调度 R 程序,以便将程序作为 Hadoop MapReduce 作业执行并将结果返回到任何相应的位置等。
Oracle R Connector for Hadoop 支持使用以下函数前缀从 R 的本地客户端访问 Apache Hadoop:
- Hadoop –标识为 Hadoop MapReduce 提供接口的函数。
- hdfs –标识为 HDFS 提供接口的函数。
- Orch –标识各种功能; orch 是 ORCH 函数的通用前缀。
- Ore –标识为Hive数据存储提供接口的函数。
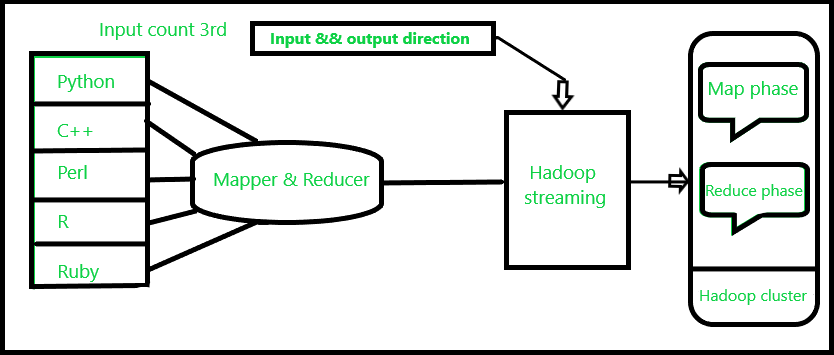
d) Hadoop 流:Hadoop 流是一种 Hadoop 实用程序,用于使用 Mapper 和 Reducer 等可执行脚本运行 Hadoop MapReduce 作业。该脚本作为 CRAN 上 R 包的一部分提供。它的目标是让基于 Hadoop 流的应用程序更容易访问 R。
这与 Linux 中的管道操作是一致的。这样,文本输入文件被打印在流(stdin)上,作为输入提供给Mapper,而Mapper的输出(stdout)作为输入提供给Reducer;最后,Reducer 将输出写入 HDFS 目录。
带有 map 和 reduce 任务的命令行以 R 脚本实现,如下所示。
$ ${HADOOP_HOME}/bin/Hadoop jar
$ {HADOOP_HOME}/contrib/streaming/*.jar\
-inputformat org.apache.hadoop.mapred.TextInputFormat \
-input input_data.txt \
-output output \
-mapper /home/tst/src/map.R \
-reducer /home/tst/src/reduce.R \
-file /home/ts/src/map.R \
-file /home/tst/src/reduce.RHadoop 流的主要好处是允许在 Hadoop 集群上执行Java以及基于非 Java 的编程 MapReduce 作业。 Hadoop 流高效地支持各种语言,如 Perl、 Python、 PHP、R 和 C++,以及其他编程语言。各种各样的 Hadoop 流式 MapReduce 作业的组件。