先决条件: Hadoop 和 HDFS
Snakebite是一个非常流行的Python包,它允许用户使用某种程序和Python应用程序访问 HDFS。 Snakebite Python包由 Spotify 开发。 Snakebite 还提供了一个Python客户端库。 protobuf消息被蛇咬客户端库用于直接与存储所有元数据的 NameNode 通信。所有文件权限、日志、创建数据块的位置都属于元数据。 CLI,即命令行界面,也可以在这个基于客户端库的snakebite Python包中使用。
让我们讨论如何为 HDFS 安装和配置蛇咬包。
要求:
- 蛇咬需要Python 2 和 python-protobuf 2.4.1 或更高版本。
使用pip可以轻松安装蛇咬库。
# Make sure you have pip for python version 2 otherwise you will face error while importing module
pip install snakebite
我们已经有蛇咬伤,所以要求得到满足。

客户端库
客户端库是使用Python构建的,它使用 Hadoop RPC 协议和 protobuf 消息与处理集群所有元数据的 NameNode 进行通信。有了这个客户端库的帮助下,Python应用程序与HDFS即Hadoop分布式文件系统直接通信而不与使用HDFS的DFS的任何连接 系统调用。
让我们编写一个简单的Python程序来理解snakebite Python包的工作原理。
任务:使用Snakebite客户端库列出HDFS根目录下的所有内容。
步骤 1:在系统中所需的位置创建一个名为list_down_root_dir.py的Python文件。
cd Documents/ # Changing directory to Documents(You can choose as per your requirement)
touch list_down_root_dir.py # touch command is used to create file in linux enviournment.

Step2:在list_down_root_dir.py Python文件中写入以下代码。
Python
# importing the package
from snakebite.client import Client
# the below line create client connection to the HDFS NameNode
client = Client('localhost', 9000)
# the loop iterate in root directory to list all the content
for x in client.ls(['/']):
print x
Client() 方法说明:
Client() 方法可以接受下面列出的所有参数:
- host(字符串): NameNode的IP地址。
- port(int): Namenode的RPC端口。
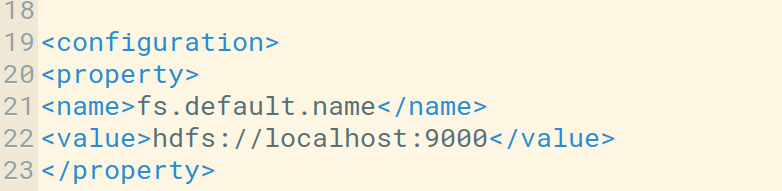
我们可以在core-site.xml文件中检查主机和默认端口。我们也可以根据我们的使用情况对其进行配置。
- hadoop_version (int): Hadoop协议版本(默认为:9)
- use_trash (boolean):删除文件时使用垃圾桶。
- Effective_use (字符串): HDFS 操作的有效用户(默认用户是当前用户)。
步骤 3:使用以下命令启动 Hadoop Daemon 。
start-dfs.sh // start your namenode datanode and secondary namenode
start-yarn.sh // start resourcemanager and nodemanager

Step4:运行list_down_root_dir.py文件,观察结果。
python list_down_root_dir.py

在上图中,您可以看到我的 HDFS 根目录中的所有可用内容。