- Hadoop-HDFS操作
- Hadoop-HDFS操作(1)
- 从 hadoop (hdfs) 中删除文件 - Shell-Bash (1)
- Hadoop – HDFS(Hadoop 分布式文件系统)(1)
- Hadoop – HDFS(Hadoop 分布式文件系统)
- 从 hadoop (hdfs) 中删除文件 - Shell-Bash 代码示例
- HDFS(1)
- HDFS
- Hadoop-大数据概述
- Hadoop-大数据概述(1)
- Hadoop分布式文件系统(HDFS)简介
- Hadoop分布式文件系统(HDFS)简介(1)
- 用于 Hadoop HDFS 的 Snakebite Python包(1)
- 用于 Hadoop HDFS 的 Snakebite Python包
- HDFS 命令
- HDFS 命令(1)
- 如何在 hdfs 中递归执行 hdfs 字符串搜索 (1)
- hadoop 流 (1)
- Hadoop-流(1)
- Hadoop-流
- HDFS的功能(1)
- HDFS的功能
- 如何在 hdfs 中递归执行 hdfs 字符串搜索 - Shell-Bash (1)
- 如何在 hdfs 中递归执行 hdfs 字符串搜索 - 无论代码示例
- 如何在 hdfs 中递归执行 hdfs 字符串搜索 - Shell-Bash 代码示例
- Hadoop 中的 SQOOP 概述(1)
- Hadoop 中的 SQOOP 概述
- hdfs 删除目录 (1)
- Hadoop 1 和 Hadoop 2 之间的区别(1)
📅 最后修改于: 2020-12-01 06:40:36 🧑 作者: Mango
Hadoop文件系统是使用分布式文件系统设计开发的。它在商品硬件上运行。与其他分布式系统不同,HDFS具有高度的容错能力,并使用低成本硬件进行设计。
HDFS可以存储大量数据,并提供更轻松的访问。为了存储如此庞大的数据,文件需要存储在多台计算机上。这些文件以冗余方式存储,以在发生故障时从可能的数据丢失中挽救系统。 HDFS还使应用程序可用于并行处理。
HDFS的功能
- 适用于分布式存储和处理。
- Hadoop提供了与HDFS交互的命令界面。
- namenode和datanode的内置服务器可帮助用户轻松检查集群的状态。
- 流式访问文件系统数据。
- HDFS提供文件权限和身份验证。
HDFS架构
下面给出的是Hadoop文件系统的体系结构。
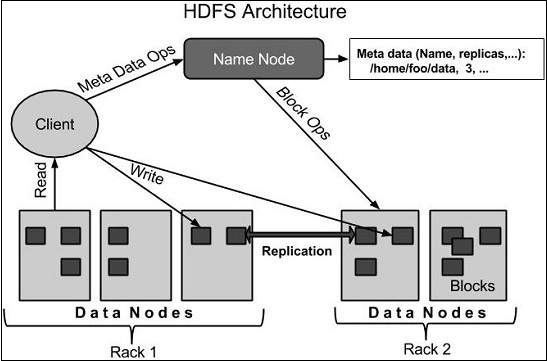
HDFS遵循主从架构,并且具有以下元素。
名称节点
名称节点是包含GNU / Linux操作系统和名称节点软件的商品硬件。它是可以在商用硬件上运行的软件。具有namenode的系统充当主服务器,它执行以下任务-
-
管理文件系统名称空间。
-
调节客户端对文件的访问。
-
它还执行文件系统操作,例如重命名,关闭和打开文件和目录。
数据节点
数据节点是具有GNU / Linux操作系统和数据节点软件的商品硬件。对于群集中的每个节点(商品硬件/系统),将有一个数据节点。这些节点管理其系统的数据存储。
-
数据节点根据客户端请求在文件系统上执行读写操作。
-
它们还根据namenode的指令执行诸如块创建,删除和复制之类的操作。
块
通常,用户数据存储在HDFS文件中。文件系统中的文件将分为一个或多个段和/或存储在各个数据节点中。这些文件段称为块。换句话说,HDFS可以读取或写入的最小数据量称为块。默认块大小为64MB,但可以根据更改HDFS配置的需要来增加。
HDFS的目标
故障检测和恢复-由于HDFS包含大量商用硬件,因此组件故障频繁发生。因此,HDFS应该具有快速自动检测和恢复故障的机制。
庞大的数据集-HDFS每个集群应具有数百个节点,以管理具有庞大数据集的应用程序。
数据上的硬件-当计算在数据附近进行时,可以有效地完成所请求的任务。特别是在涉及大量数据集的地方,它减少了网络流量并提高了吞吐量。