Hadoop 是一种流行的用Java编写的大数据框架。但是没有必要使用Java来处理 Hadoop。也可以使用其他一些编程语言,如Python、 C++ 。我们可以使用管道 API 或 Hadoop 管道为 Hadoop 编写 C++ 代码。 Hadoop 管道在套接字的帮助下启用任务跟踪器。
Python也可用于为 Hadoop 编写代码。 Snakebite 是用于与 HDFS 建立通信的流行库之一。使用 Snakebite 包提供的Python客户端库,我们可以轻松编写适用于 HDFS 的Python代码。它使用protobuf消息直接与 NameNode 通信。 Python客户端库直接与 HDFS 配合使用,无需对hdfs dfs进行系统调用。
先决条件:应安装 Snakebite 库。
如果没有,请确保 Hadoop 正在运行,然后使用以下命令启动所有守护程序。
start-dfs.sh // start your namenode datanode and secondary namenode
start-yarn.sh // start resourcemanager and nodemanager
任务:使用mkdir()方法使用蛇咬包在 HDFS 中创建目录。
步骤 1:在您的本地目录中在所需位置创建一个名为create_directory.py的文件。
cd Documents/ # Changing directory to Documents(You can choose as per your requirement)
touch create_directory.py # touch command is used to create file in linux enviournment.

第 2 步:在create_directory.py Python文件中编写以下代码。
Python
# importing the package
from snakebite.client import Client
# the below line create client connection to the HDFS NameNode
client = Client('localhost', 9000)
# create directories mentioned in mkdir() methods first argument i.e. in List format
for p in client.mkdir(['/demo/demo1', '/demo2'], create_parent=True):
print pmkdir()获取我们要创建的目录路径的列表。 create_parent=True确保如果未创建父目录,则应首先创建它。在我们的例子中,将首先创建 demo 目录,然后在其中创建 demo1。

第三步:运行create_directory.py文件,观察结果。
python create_directory.py // this will create directory's as mentioned in mkdir() argument.

在上图中‘result’ :True表示我们已成功创建目录。
第 4 步:我们可以手动或使用以下命令检查目录是否已创建。
hdfs dfs -ls / // list all the directory's in root folder
hdfs dfs -ls /demo // list all the directory's present in demo folder
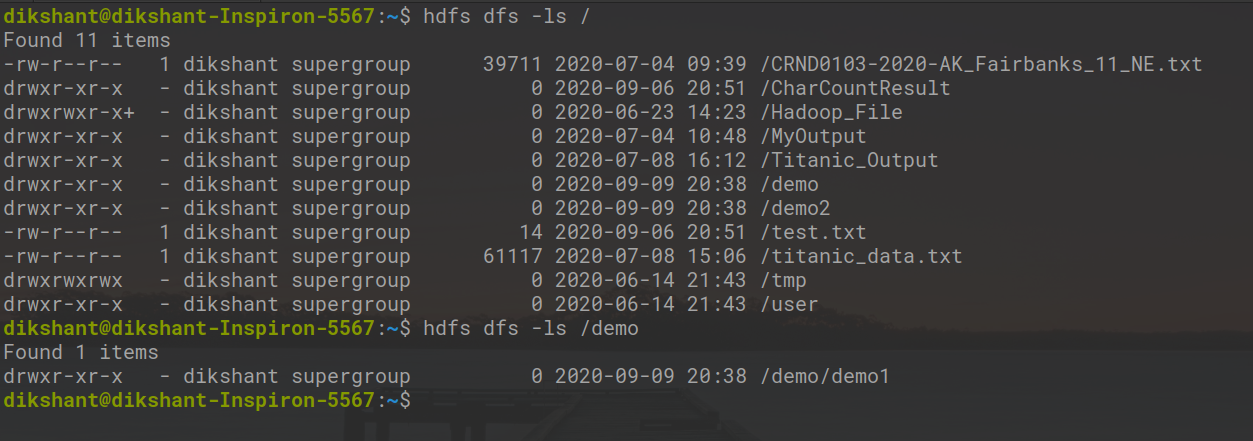
在上图中,我们可以观察到我们已经成功创建了所有目录。