众所周知,Hadoop 是一个用Java编写的框架,它利用大量商用硬件来维护和存储大数据。 Hadoop 使用 Google 推出的 MapReduce 编程算法。今天,许多大品牌公司在他们的组织中使用 Hadoop 来处理大数据,例如。 Facebook、Yahoo、Netflix、eBay 等。 Hadoop 架构主要由 4 个组件组成。
- 地图简化
- HDFS(Hadoop分布式文件系统)
- YARN(又一个资源框架)
- Common Utilities 或 Hadoop Common
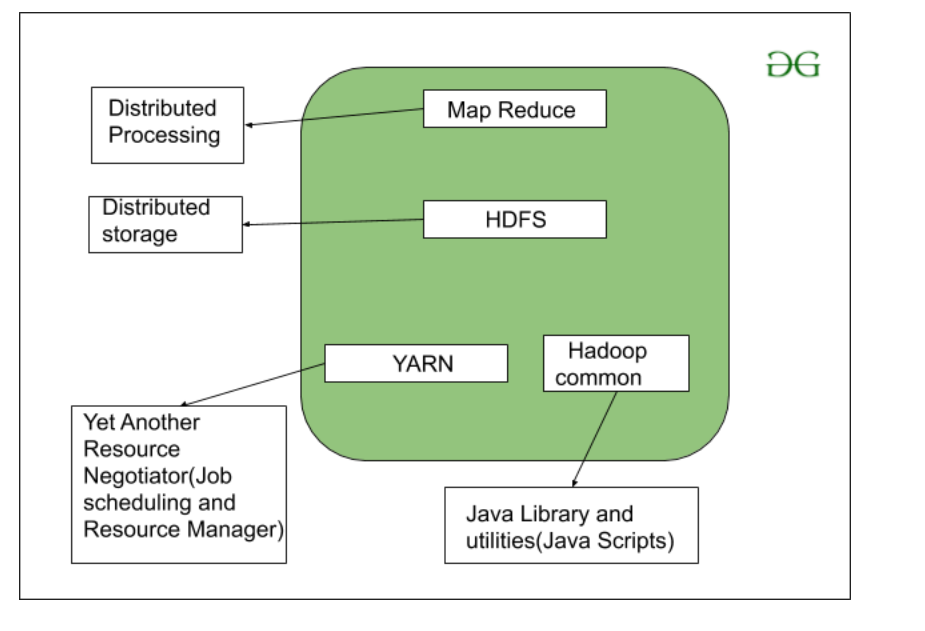
下面我们来详细了解一下这个组件中每一个的作用。
1. MapReduce
MapReduce 只不过是一种基于 YARN 框架的算法或数据结构。 MapReduce 的主要特点是在 Hadoop 集群中并行执行分布式处理,这使得 Hadoop 工作如此之快。当您处理大数据时,串行处理没有任何用处。 MapReduce 主要有 2 个分阶段划分的任务:
- 地图任务
- 减少任务
在第一阶段,使用Map ,在下一阶段使用Reduce 。
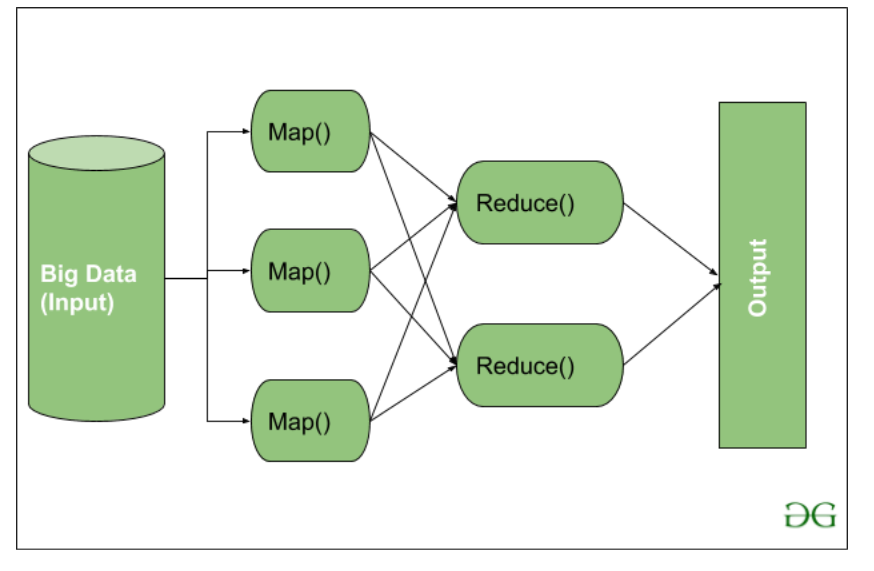
在这里,我们可以看到Input被提供给 Map()函数,然后它的输出被用作 Reduce函数的输入,之后,我们收到我们的最终输出。让我们了解这个 Map() 和 Reduce() 是做什么的。
正如我们所看到的,现在我们正在使用大数据,为 Map() 提供了一个 Input。输入是一组数据。此处的 Map()函数将这些数据块分解为仅是键值对的元组。这些键值对现在作为输入发送到 Reduce()。然后,Reduce()函数根据其 Key 值和元组的形式集组合这个损坏的元组或键值对,并执行一些操作,如排序、求和类型作业等,然后将其发送到最终的输出节点。最后,得到输出。
根据该行业的业务需求,数据处理始终在 Reducer 中完成。这就是一个 Map() 然后 Reduce 是如何使用的。
让我们详细了解Map Taks和Reduce Task 。
地图任务:
- RecordReader recoredreader的目的是打破记录。它负责在 Map()函数提供键值对。键实际上是它的位置信息,而值是与其关联的数据。
- Map:Map只不过是一个用户定义的函数,其工作是处理从记录读取器获取的元组。 Map()函数要么不生成任何键值对,要么生成这些元组的多对。
- 组合器:组合器用于对 Map 工作流中的数据进行分组。它类似于本地减速器。 Map 中生成的中间键值在此组合器的帮助下进行组合。使用组合器不是必需的,因为它是可选的。
- Partitionar: Partitional 负责获取 Mapper Phases 中生成的键值对。 partitioner 生成对应于每个 reducer 的分片。每个键的哈希码也由该分区获取。然后partitioner用reducers的数量( key.hashcode()%(number of reducers))执行它的(Hashcode)模数。
减少任务
- Shuffle and Sort: Reducer的Task从这一步开始,Mapper生成中间key-value并传递给Reducer任务的过程称为Shuffling 。使用 Shuffling 过程,系统可以使用其键值对数据进行排序。
一旦一些 Mapping 任务完成,Shuffling 就开始了,这就是为什么它是一个更快的过程,并且不等待 Mapper 执行的任务完成。
- Reduce:Reduce的主要函数或任务是收集从 Map 生成的 Tuple,然后根据其 key 元素对这些 key-value 执行一些排序和聚合排序过程。
- 输出格式:所有操作完成后,键值对在记录写入器的帮助下写入文件,每条记录换行,键和值以空格分隔。
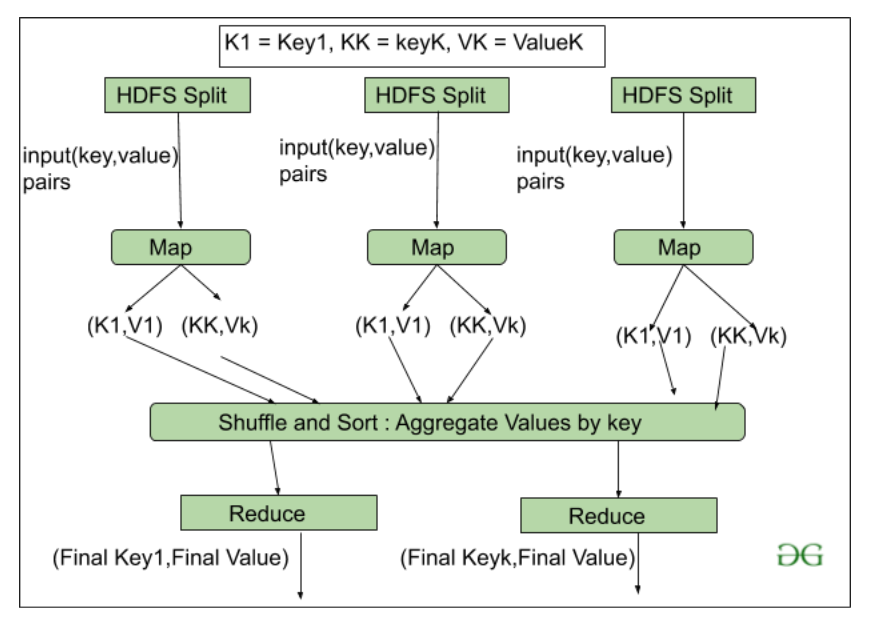
2. HDFS
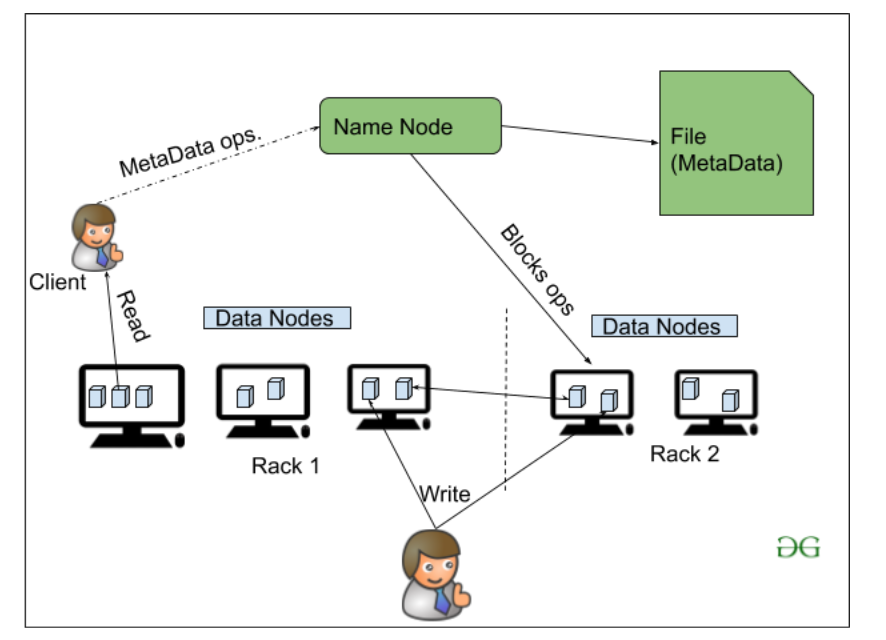
HDFS(Hadoop分布式文件系统)用于存储权限是一个Hadoop集群。它主要设计用于在商品硬件设备(廉价设备)上工作,在分布式文件系统设计上工作。 HDFS 的设计方式是它更相信将数据存储在大块块中,而不是存储小数据块。
Hadoop 中的 HDFS 为存储层和该 Hadoop 集群中的其他设备提供容错和高可用性。 HDFS 中的数据存储节点。
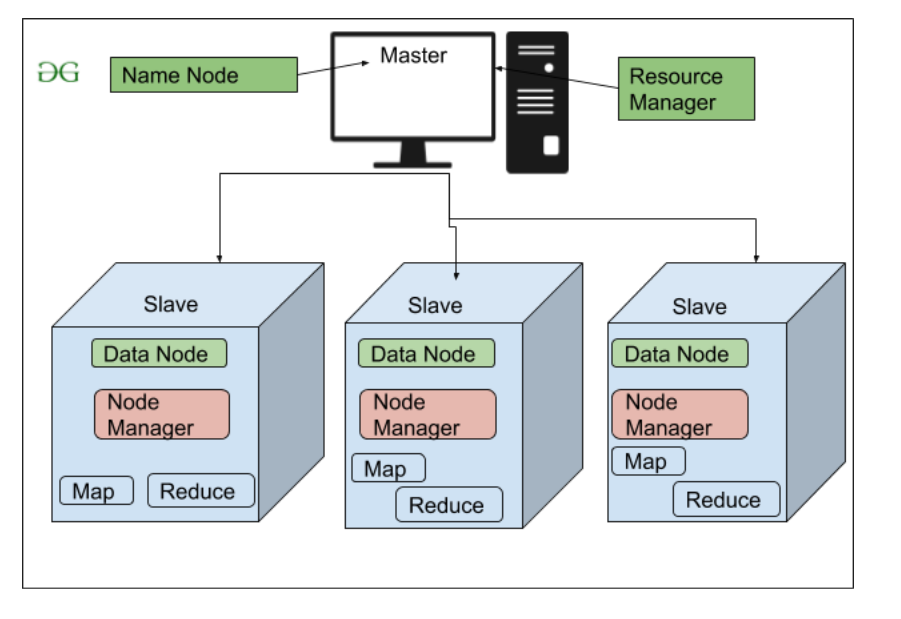
- 名称节点(主)
- 数据节点(从)
NameNode: NameNode 在 Hadoop 集群中作为 Master 来引导 Datanode(Slaves)。 Namenode主要用于存储Metadata,即关于数据的数据。元数据可以是跟踪用户在 Hadoop 集群中的活动的事务日志。
Meta Data也可以是Namenode存储的文件名、大小、Datanode的位置信息(Block number, Block ids),以找到最近的DataNode,实现更快的通信。 Namenode 通过删除、创建、复制等操作来指示 DataNode。
DataNode: DataNodes 作为 Slave DataNodes 主要用于在 Hadoop 集群中存储数据,DataNodes 的数量可以从 1 到 500 甚至更多。 DataNode 的数量越多,Hadoop 集群就能存储更多的数据。所以建议DataNode应该有High的存储容量来存储大量的文件块。
Hadoop的高层架构
HDFS 中的文件块:HDFS 中的数据始终以块的形式存储。所以单个数据块被分成多个大小为 128MB 的块,这是默认的,您也可以手动更改它。
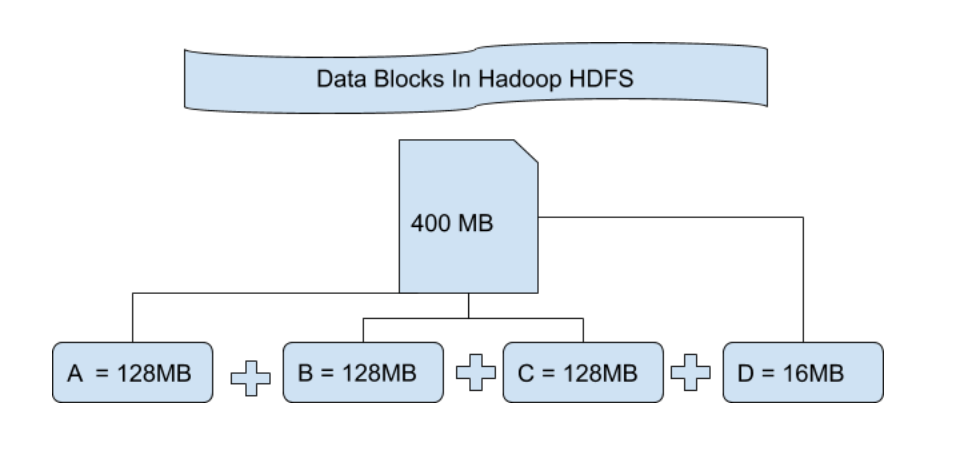
让我们通过一个例子来理解这个以块为单位分解文件的概念。假设你上传了一个 400MB 的文件到你的 HDFS,那么这个文件被分成了 128MB+128MB+128MB+16MB = 400MB 大小的块。意味着创建了 4 个块,每个块都为 128MB,除了最后一个。 Hadoop 不知道或不关心这些块中存储了哪些数据,因此它将最终文件块视为部分记录,因为它对此一无所知。在 Linux 文件系统中,一个文件块的大小约为 4KB,远小于 Hadoop 文件系统中文件块的默认大小。众所周知,Hadoop 主要用于存储 PB 级的大数据,这也是 Hadoop 文件系统不同于其他文件系统的原因,因为它可以扩展,现在 Hadoop 中考虑了 128MB 到 256MB 的文件块。
复制 HDFS复制确保数据的可用性。复制是制作某物的副本,您复制该特定事物的次数可以表示为它的复制因子。正如我们在文件块中看到的那样,HDFS 以各种块的形式存储数据,同时 Hadoop 也被配置为制作这些文件块的副本。
默认情况下,Hadoop 的复制因子设置为 3,可以配置这意味着您可以根据您的要求手动更改它,就像在上面的示例中我们制作了 4 个文件块,这意味着制作了每个文件块的 3 个副本或副本意味着总共 4×3 = 12 个块用于备份目的。
这是因为为了运行 Hadoop,我们使用了随时可能崩溃的商品硬件(廉价的系统硬件)。我们没有将超级计算机用于我们的 Hadoop 设置。这就是为什么我们在 HDFS 中需要这样一个功能,它可以为备份目的制作该文件块的副本,这被称为容错。
现在我们还需要注意一件事,在制作了如此多的文件块副本后,我们浪费了太多的存储空间,但对于大品牌组织而言,数据比存储空间重要得多,因此没有人关心这些额外的存储空间。您可以在hdfs-site.xml文件中配置复制因子。
机架感知机架只是我们 Hadoop 集群中节点的物理集合(可能是 30 到 40 个)。一个大型的 Hadoop 集群由如此多的 Racks 组成。在此机架信息的帮助下,Namenode 选择最近的 Datanode 以实现最大性能,同时执行减少网络流量的读/写信息。
HDFS架构
3. YARN(又一个资源谈判者)
YARN 是 MapReduce 工作的框架。 YARN 执行 2 个操作,即作业调度和资源管理。 Job schedular 的目的是将一个大任务划分为小任务,以便每个任务可以分配给 Hadoop 集群中的各个从站,并且可以最大化处理。作业调度器还跟踪哪个作业重要、哪个作业具有更高的优先级、作业之间的依赖关系以及作业时间等所有其他信息。 资源管理器的用途是管理可用于运行的所有资源一个 Hadoop 集群。
YARN的特点
- 多租户
- 可扩展性
- 集群利用率
- 兼容性
4. Hadoop common 或 Common Utilities
Hadoop 通用或通用实用程序只不过是我们的Java库和Java文件,或者我们可以说是 Hadoop 集群中存在的所有其他组件所需的Java脚本。 HDFS、YARN 和 MapReduce 使用这些实用程序来运行集群。 Hadoop Common 验证 Hadoop 集群中的硬件故障是常见的,因此需要通过 Hadoop 框架在软件中自动解决。