Apache Spark是一种闪电般快速的统一分析引擎,用于对 BigData 和 Hadoop 等大型数据集进行集群计算,旨在跨多个节点并行运行程序。它是多个堆栈库的组合,例如 SQL 和 Dataframes、GraphX、MLlib 和 Spark Streaming。
Spark 以 4 种不同的模式运行:
- 独立模式:这里所有进程都在同一个 JVM 进程中运行。
- 独立集群模式:在这种模式下,它使用 Spark 内置的 Job-Scheduling 框架。
- Apache Mesos:在这种模式下,工作节点运行在各种机器上,但驱动程序只运行在主节点上。
- Hadoop YARN:在这种模式下,驱动程序在应用程序的主节点内运行,并由集群上的 YARN 处理。
在本文中,我们将探索在独立模式下安装 Apache Spark。 Apache Spark 是用 Scala 编程语言开发的,运行在 JVM 上。 Java安装是 spark 中必不可少的事情之一。所以让我们从Java安装开始。
安装Java:
第 1 步:下载Java JDK。

第 2 步:打开下载的Java SE Development Kit 并按照安装说明进行操作。


第 3 步:通过在 Windows 搜索栏中键入环境变量来打开笔记本电脑上的环境变量。
设置 JAVA_HOME 变量:
要设置 JAVA_HOME 变量,请按照以下步骤操作:
- 单击用户变量将 JAVA_HOME 添加到路径,值为值:C:\Program Files\ Java\jdk1.8.0_261。
- 单击系统变量将 C:\Program Files\ Java\jdk1.8.0_261\bin 添加到 PATH 变量。
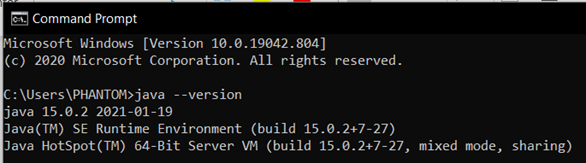
- 打开命令提示符并键入“Java –version”,它将显示如下所示并验证Java安装。
安装 Scala:
要在本地机器上安装 Scala,请按照以下步骤操作:
第 1 步:下载 Scala。
第 2 步:单击 .exe 文件并按照说明按照您的需要自定义设置。

第 3 步:接受协议并单击下一步按钮。

设置环境变量:
- 在用户变量中将 SCALA_HOME 添加到值为 C:\Program Files (x86)\scala 的 PATH。
- 在系统变量中将 C:\Program Files (x86)\scala\bin 添加到 PATH 变量。
验证 Scala 安装:
在命令提示符下,使用以下命令验证 Scala 安装:
scala
安装星火:
下载一个预建版本的 Spark 并将其解压到 C 盘,例如 C:\Spark。然后单击安装文件并按照说明设置 Spark。

设置环境变量:
- 在用户变量中将 SPARK_HOME 添加到 PATH,值为 C:\spark\spark-2.4.6-bin-hadoop2.7。
- 在系统变量中将 %SPARK_HOME%\bin 添加到 PATH 变量中。
下载 Windows 实用程序:
如果您希望对 Hadoop 数据进行操作,请按照以下步骤下载适用于 Hadoop 的实用程序:
步骤 1:下载 winutils.exe 文件。

第二步:将文件复制到C:\spark\spark-1.6.1-bin-hadoop2.6\bin。
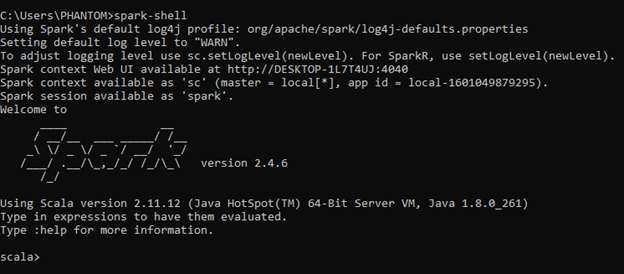
第三步:现在在cmd上执行“spark-shell”来验证spark安装,如下图: