从大型数据集中查找前 10 或 20 条记录是许多推荐系统的核心,也是数据分析的重要属性。在这里,我们将讨论以下两种查找 top-N 记录的方法。
方法一:首先找出观看次数最多的前10部电影来理解方法,然后我们将其概括为’n’条记录。
数据格式:
movie_name and no_of_views (tab separated)使用的方法:使用 TreeMap。这里的想法是使用 Mappers 来查找本地前 10 条记录,因为可以有许多 Mappers 在文件的不同数据块上并行运行。然后所有这些本地前 10 条记录将在 Reducer 聚合,在那里我们找到文件的前 10 条全局记录。
示例:假设文件(30 TB)被分成 3 个块,每个块 10 TB,每个块由 Mapper 并行处理,因此我们找到该块的前 10 条记录(本地)。然后这些数据移动到reducer,在那里我们从文件movie.txt 中找到实际的前10 条记录。
Movie.txt 文件:您可以通过单击此处查看整个文件


映射器代码:
import java.io.*;
import java.util.*;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.mapreduce.Mapper;
public class top_10_Movies_Mapper extends Mapper {
private TreeMap tmap;
@Override
public void setup(Context context) throws IOException,
InterruptedException
{
tmap = new TreeMap();
}
@Override
public void map(Object key, Text value,
Context context) throws IOException,
InterruptedException
{
// input data format => movie_name
// no_of_views (tab seperated)
// we split the input data
String[] tokens = value.toString().split("\t");
String movie_name = tokens[0];
long no_of_views = Long.parseLong(tokens[1]);
// insert data into treeMap,
// we want top 10 viewed movies
// so we pass no_of_views as key
tmap.put(no_of_views, movie_name);
// we remove the first key-value
// if it's size increases 10
if (tmap.size() > 10)
{
tmap.remove(tmap.firstKey());
}
}
@Override
public void cleanup(Context context) throws IOException,
InterruptedException
{
for (Map.Entry entry : tmap.entrySet())
{
long count = entry.getKey();
String name = entry.getValue();
context.write(new Text(name), new LongWritable(count));
}
}
}
说明:这里要注意的重点是我们在 cleanup()方法中使用了“ context.write() ”,该方法在 Mapper 的生命周期结束时只运行一次。 Mapper 一次处理一个键值对,并将它们作为中间输出写入本地磁盘。但是我们必须在写入输出之前处理整个块(所有键值对)以找到 top10,因此我们在 cleanup() 中使用 context.write()。
减速机代码:
import java.io.IOException;
import java.util.Map;
import java.util.TreeMap;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class top_10_Movies_Reducer extends Reducer {
private TreeMap tmap2;
@Override
public void setup(Context context) throws IOException,
InterruptedException
{
tmap2 = new TreeMap();
}
@Override
public void reduce(Text key, Iterable values,
Context context) throws IOException, InterruptedException
{
// input data from mapper
// key values
// movie_name [ count ]
String name = key.toString();
long count = 0;
for (LongWritable val : values)
{
count = val.get();
}
// insert data into treeMap,
// we want top 10 viewed movies
// so we pass count as key
tmap2.put(count, name);
// we remove the first key-value
// if it's size increases 10
if (tmap2.size() > 10)
{
tmap2.remove(tmap2.firstKey());
}
}
@Override
public void cleanup(Context context) throws IOException,
InterruptedException
{
for (Map.Entry entry : tmap2.entrySet())
{
long count = entry.getKey();
String name = entry.getValue();
context.write(new LongWritable(count), new Text(name));
}
}
}
说明:与映射器相同的逻辑。 Reducer 一次处理一个键值对,并将它们作为最终输出写入 HDFS。但是我们必须在写入输出之前处理所有键值对以找到 top10,因此我们使用cleanup() 。
驱动程序代码:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class Driver {
public static void main(String[] args) throws Exception
{
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf,
args).getRemainingArgs();
// if less than two paths
// provided will show error
if (otherArgs.length < 2)
{
System.err.println("Error: please provide two paths");
System.exit(2);
}
Job job = Job.getInstance(conf, "top 10");
job.setJarByClass(Driver.class);
job.setMapperClass(top_10_Movies_Mapper.class);
job.setReducerClass(top_10_Movies_Reducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
job.setOutputKeyClass(LongWritable.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
运行jar文件:
- 我们将所有类导出为jar文件。
- 我们将文件movie.txt从本地文件系统移动到 HDFS 中的 /geeksInput。
bin/hdfs dfs -put ../Desktop/movie.txt /geeksInput - 我们现在运行yarn服务来运行jar文件。
bin/yarn jar jar_file_location package_Name.Driver_classname input_path output_path
代码运行:
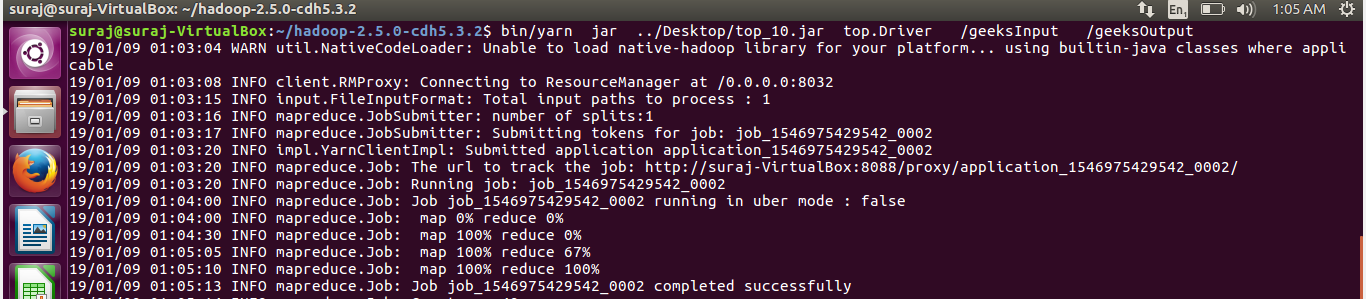
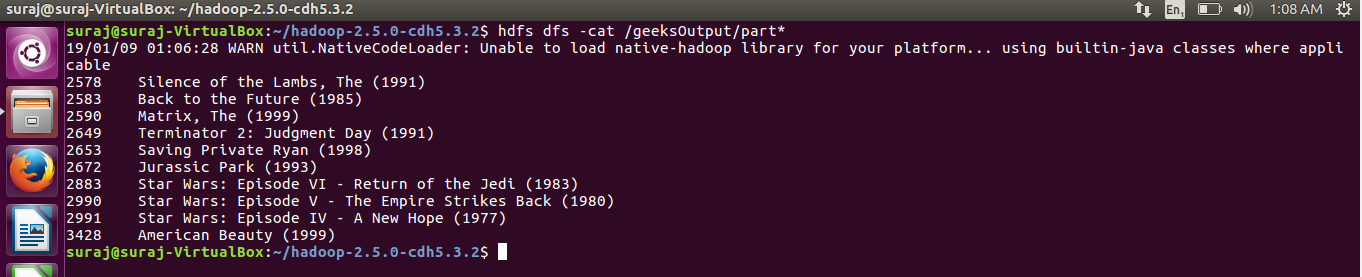
输出:升序
方法二:这个方法是基于Mapper的输出在进入reducer之前根据key排序的属性。这次让我们按降序打印。现在,我们只需将映射器中的键与 -1 相乘,以便在排序后更高的数字出现在顶部(大小明智)。现在我们只打印 10 条记录,去掉键中的 -ve 符号。
示例:在减速器处
Keys After sorting: 23 25 28 ..如果键乘以 -1
Keys After sorting: -28 -25 -23 ..映射器代码:
import java.io.*; import org.apache.hadoop.io.Text; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.mapreduce.Mapper; public class top_10_Movies2_Mapper extends Mapper减速机代码:
import java.io.*; import org.apache.hadoop.io.Text; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.mapreduce.Reducer; public class top_10_Movies2_Reducer extends Reducervalues, Context context) throws IOException, InterruptedException { // key values //-ve of no_of_views [ movie_name ..] long no_of_views = (-1) * key.get(); String movie_name = null; for (Text val : values) { movie_name = val.toString(); } // we just write 10 records as output if (count < 10) { context.write(new LongWritable(no_of_views), new Text(movie_name)); count++; } } } 说明:这里的setup()方法是一开始只运行一次的方法
在 Reducer/Mapper 的生命周期中。因为我们只想打印10个记录,我们定义设置()方法计数变量。驱动程序代码:
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.GenericOptionsParser; public class Driver { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); String[] otherArgs = new GenericOptionsParser(conf , args).getRemainingArgs(); // if less than two paths // provided will show error if (otherArgs.length < 2) { System.err.println("Error: please provide two paths"); System.exit(2); } Job job = Job.getInstance(conf, "top_10 program_2"); job.setJarByClass(Driver.class); job.setMapperClass(top_10_Movies2_Mapper.class); job.setReducerClass(top_10_Movies2_Reducer.class); job.setMapOutputKeyClass(LongWritable.class); job.setMapOutputValueClass(Text.class); job.setOutputKeyClass(LongWritable.class); job.setOutputValueClass(Text.class); FileInputFormat.addInputPath(job, new Path(otherArgs[0])); FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } }运行jar文件:我们现在运行yarn服务来运行jar文件

代码运行:
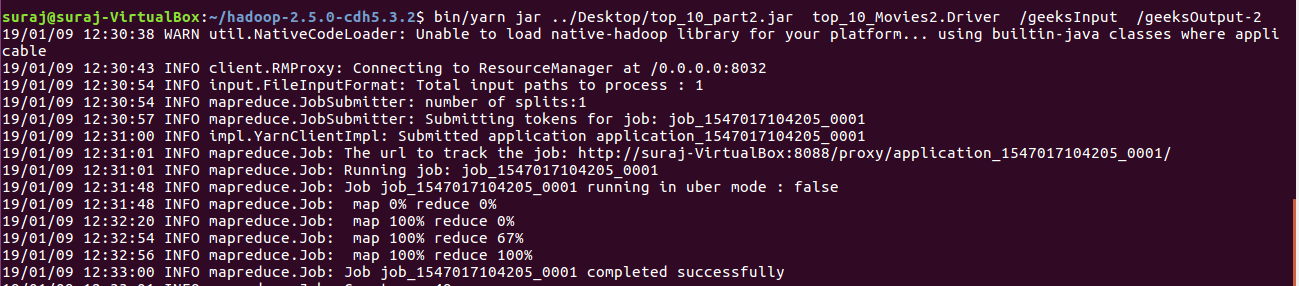
输出:
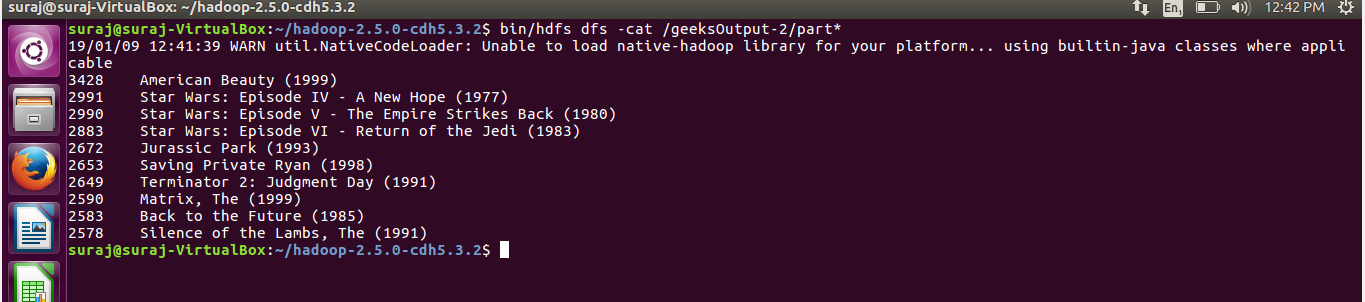
注意:需要注意的一件重要事情是,虽然Method-2易于实现,但与Method-1相比效率并不高,因为我们将所有键值对传递给 reducer,即有大量数据移动可能导致到瓶颈情况。但是在 Method-1 中,我们只将 10 个键值对传递给 reducer。
将其推广到 ‘n’ 条记录:让我们针对一些我们可能在运行时传递其值的 ‘n’ 条记录修改我们的第二个程序。首先要注意几点:
- 我们使用 set() 方法制作自定义参数
configuration_object.set(String name, String value)- 可以使用 get() 方法在任何 Mapper/Reducer 中访问此值
Configuration conf = context.getConfiguration(); // we will store value in String variable String value = conf.get(String name);映射器代码:映射器代码将保持不变,因为我们不使用那里的值。
Reducer 代码:这里我们对 setup() 方法进行了一些更改。
import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.conf.Configuration; public class top_n_Reducer extends Reducervalues, Context context) throws IOException, InterruptedException { long no_of_views = (-1) * key.get(); String movie_name = null; for (Text val : values) { movie_name = val.toString(); } // we just write 10 records as output if (count > 0) { context.write(new LongWritable(no_of_views), new Text(movie_name)); count--; } } 驱动程序代码:
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.GenericOptionsParser; public class genericDriver { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); /* here we set our own custom parameter myValue with * default value 10. We will overwrite this value in CLI * at runtime. * Remember that both parameters are Strings and we * have convert them to numeric values when required. */ conf.set("myValue", "10"); String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); // if less than two paths provided will show error if (otherArgs.length < 2) { System.err.println("Error: please provide two paths"); System.exit(2); } Job job = Job.getInstance(conf, "top_10 program_2"); job.setJarByClass(genericDriver.class); job.setMapperClass(top_n_Mapper.class); job.setReducerClass(top_n_Reducer.class); job.setMapOutputKeyClass(LongWritable.class); job.setMapOutputValueClass(Text.class); job.setOutputKeyClass(LongWritable.class); job.setOutputValueClass(Text.class); FileInputFormat.addInputPath(job, new Path(otherArgs[0])); FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); }现在是最重要的部分,即从 CLI 将值传递给我们的自定义参数myValue。我们使用 -D 命令行选项 => 如下所示:
-D property=value (Use value for given property.)让我们传递 5 作为值来查找前 5 条记录:

输出:

其他链接:GitHub 存储库
- 我们使用 set() 方法制作自定义参数