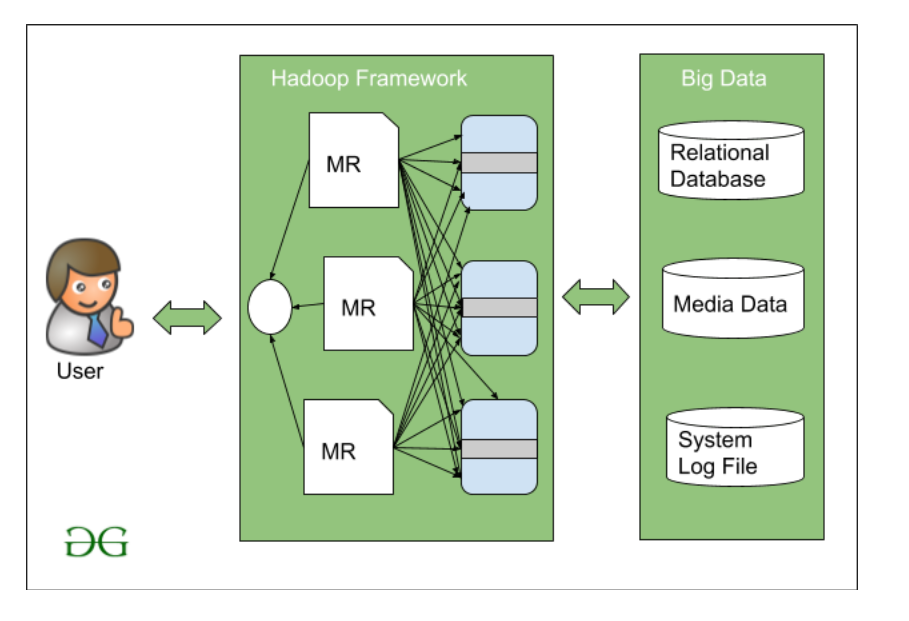
浪费隐藏在数据背后的有用信息对于行业来说可能是一个危险的障碍,忽视这些信息最终会拉回你的行业增长。数据?大数据?你认为它有多大,是的,它的体积真的很大,速度、种类、真实性和价值都很大。那么你认为人类如何找到处理这些大数据的解决方案。让我们一一讨论这些不同的方法。
传统方法
在传统方法中,早期的Big Giant科技公司在IBM、Oracle等市场上可用的各种数据库供应商的帮助下,在单个系统上处理数据,存储和处理数据。当时使用的数据库使用RDBMS(Relational数据库管理系统),用于存储结构化数据。开发人员使用一个简短的应用程序来帮助他们与数据库进行通信,并帮助他们维护、分析、修改和可视化存储的数据。
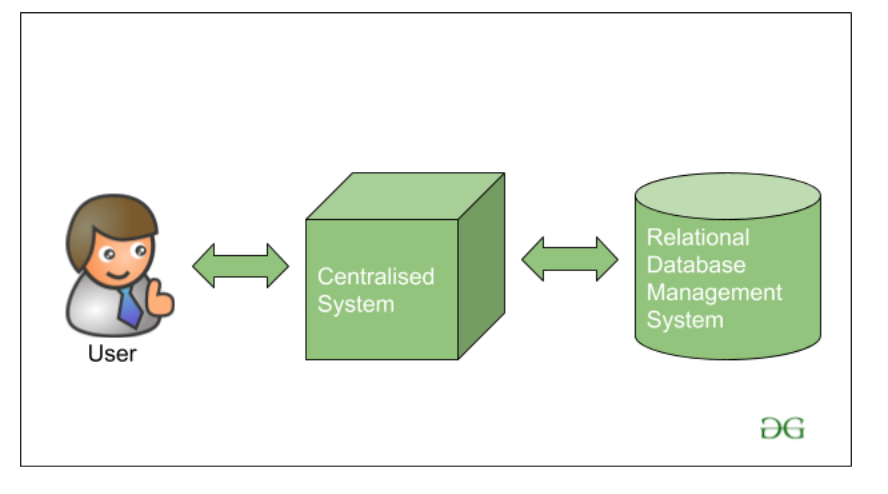
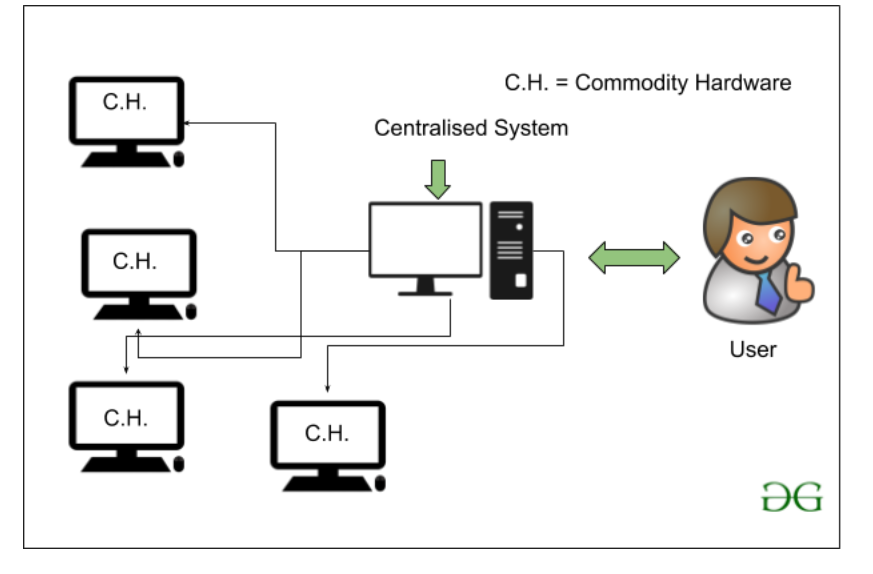
但是使用这种传统方式存在一个问题,问题是当时的数据库服务器实际上是商品硬件,只能存储和维护非常小的数据量。只能在一定限度内处理数据,即关于当时可用处理器的处理速度。此外,由于我们没有使用计算机系统集群,因此服务器效率不高或无法处理数据的速度和多样性。单个数据库服务器专用于处理所有这些数据。
Google 如何找到它的大数据解决方案?
谷歌当时引入了算法名称MapReduce 。 MapReduce 工作在主从架构上,这意味着 Google 引入了一个新术语,而不是专用于单个数据库服务器来处理数据,其中有Master将指导其他从节点处理这些大数据。任务应该被分成不同的块,然后在这些从站之间分配。然后一旦从站处理数据,主站将收集从各个从站节点获得的结果,并制作最终结果数据集。
后来, Doug Cutting和他的同事Mike Cafarella在 2005 年决定制作一个开源软件,可以在这个 MapReduce 算法上工作。这是第一次引入 Hadoop 的图片来处理非常大的数据集。
Hadoop 是一个用Java编写的框架,它处理各种简单商品硬件的集合,使用非常基本的编程模型来处理大型数据集。