HDFS 是一种分布式文件系统,可通过商用机器网络存储数据。 HDFS 适用于流数据访问模式,这意味着它支持多写和多读功能。 HDFS 上的读操作非常重要,也非常有必要让我们在 HDFS 上工作时了解在 HDFS(Hadoop 分布式文件系统)上实际读取是如何完成的。让我们了解 HDFS 数据读取的工作原理。
在 HDFS 上阅读似乎很简单,但事实并非如此。每当客户端向 HDFS 发送请求以从 HDFS 读取某些内容时,不会直接授予客户端访问数据或 DataNode 的权限,因为客户端没有关于数据的信息,即存储 DataNode 数据的位置或者在 DataNode 上制作数据副本的地方。如果不知道有关 DataNode 的信息,客户端将永远无法访问或读取来自 HDFS 的数据。
因此,这就是客户端首先向 NameNode 发送请求的原因,因为 NameNode 包含我们在 HDFS 上执行读取操作所需的所有元数据或信息。一旦 NameNode 收到请求,它就会响应并向客户端发送所有信息,例如 DataNode 的数量、制作副本的位置、数据块的数量及其位置等。现在客户端可以使用 NameNode 提供的所有这些信息读取数据。客户端并行读取数据,因为相同数据的副本在集群上可用。读取整个数据后,它将所有块组合为原始文件。
让我们用一张合适的图来理解在 HDFS 上读取的数据
在学习 HDFS 读操作之前我们必须知道的组件。
NameNode: Namenode 的主要目的是管理所有的 MetaData。正如我们所知,数据以块的形式存储在 Hadoop 集群中。因此,MetaData 中提到了该文件块存储在哪个 DataNode 或哪个位置。 Hadoop 集群中发生的事务日志,何时或谁读取或写入数据,所有这些信息都将存储在 MetaData 中。
DataNode: DataNode 是一个运行在从系统上的程序,它服务于来自客户端的读/写请求,用于以块的形式存储数据。
HDFS Client: HDFS Client 是 HDFS 和用户之间的中间组件。它与 Datanode 或 Namenode 通信并获取用户请求的基本输出。
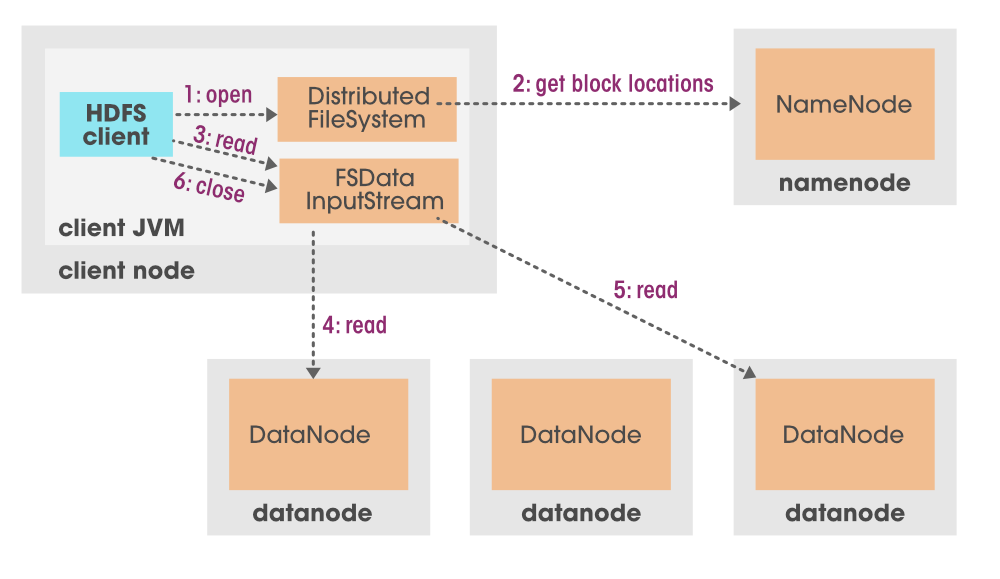
在上图中我们可以看到,首先,我们将请求发送到我们的 HDFS 客户端,这是一组程序。现在,这个 HDFS 客户端联系 NameNode,因为它拥有有关我们要读取的文件的所有信息或元数据。 NamoNode 做出响应,然后将所有元数据发送回 HDFS 客户端。一旦 HDFS 客户端知道它必须从哪个位置挑选数据块,它就会要求 FS 数据输入流指出数据节点上的那些数据块。 FS 数据输入流然后进行一些处理并使这些数据可供客户端使用。
让我们看看从HDFS读取数据的方式。
使用 HDFS 命令:
借助以下命令,我们可以直接从 HDFS 读取数据(注意:确保所有 Hadoop 守护进程都在运行)。
启动 Hadoop 守护进程的命令
start-dfs.sh
start-yarn.sh从 HDFS 读取数据的语法:
hdfs dfs -get
# destination path is where we want to store the readed file on local machine
命令
在我们的例子中,我们在 HDFS 根目录中有一个名为 dikshant.txt 的文件,其中包含一些数据。下面的命令,我们可以用来列出 HDFS 根目录上的数据。
hdfs dfs -ls /
下面的命令将从 HDFS 的根目录读取数据并将其存储在我本地机器上的 /home/dikshant/Desktop 位置。
hdfs dfs -get /dikshant.txt /home/dikshant/Desktop
在下图中,我们可以观察到数据已成功读取并存储在/home/dikshant/Desktop目录中,现在我们可以通过打开此文件来查看其内容。
