概述: Apache Hadoop 是一个开源框架,旨在使与大数据的交互更容易,但是,对于不熟悉这项技术的人来说,会出现一个问题,什么是大数据?大数据是指在传统方法(例如 RDBMS)的帮助下无法以有效方式处理的数据集的术语。 Hadoop 在需要处理敏感且需要高效处理的大型数据集的行业和公司中占有一席之地。 Hadoop 是一个框架,可以处理以集群形式存在的大型数据集。作为一个框架,Hadoop 由多个模块组成,这些模块由大型技术生态系统提供支持。
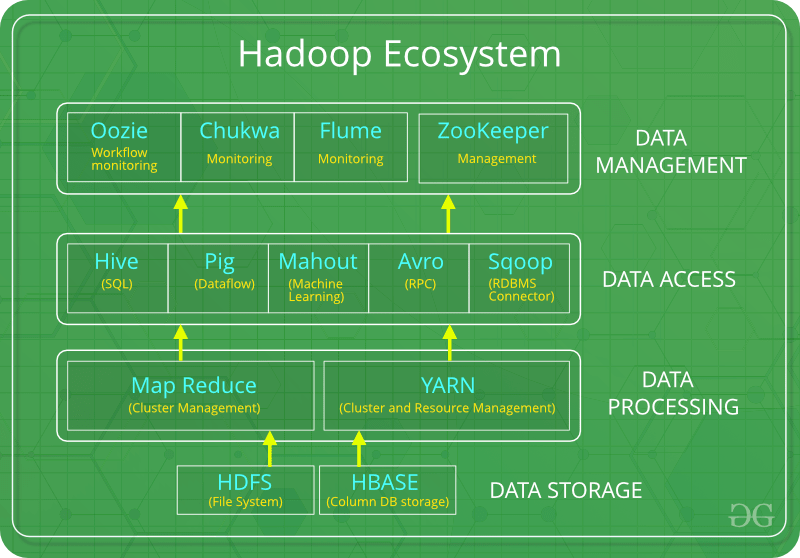
简介: Hadoop 生态系统是一个平台或套件,提供各种服务来解决大数据问题。它包括 Apache 项目和各种商业工具和解决方案。 Hadoop有四个主要元素,即HDFS、MapReduce、YARN 和 Hadoop Common 。大多数工具或解决方案用于补充或支持这些主要元素。所有这些工具协同工作,提供数据的吸收、分析、存储和维护等服务。
以下是共同构成 Hadoop 生态系统的组件:
- HDFS: Hadoop 分布式文件系统
- YARN:又一个资源谈判者
- MapReduce:基于编程的数据处理
- Spark:内存数据处理
- PIG、HIVE:基于查询的数据服务处理
- HBase: NoSQL 数据库
- Mahout、Spark MLLib:机器学习算法库
- Solar、Lucene:搜索和索引
- Zookeeper:管理集群
- Oozie:作业调度
注意:除了上述组件外,还有许多其他组件也是 Hadoop 生态系统的一部分。
所有这些工具包或组件都围绕着一个术语,即数据。这就是 Hadoop 的美妙之处,它围绕数据展开,因此使其合成更容易。
HDFS:
- HDFS 是 Hadoop 生态系统的主要或主要组件,负责跨各个节点存储结构化或非结构化数据的大型数据集,从而以日志文件的形式维护元数据。
- HDFS 由两个核心组件组成,即
- 名称节点
- 数据节点
- Name Node 是包含元数据(关于数据的数据)的主要节点,需要比存储实际数据的数据节点更少的资源。这些数据节点是分布式环境中的商品硬件。毫无疑问,使 Hadoop 具有成本效益。
- HDFS 维护集群和硬件之间的所有协调,因此是系统的核心。
纱:
- 另一个资源协商者,顾名思义,YARN 是帮助管理跨集群资源的人。简而言之,它为 Hadoop 系统执行调度和资源分配。
- 由三个主要组件组成,即
- 资源管理器
- 节点管理器
- 应用经理
- 资源管理器具有为系统中的应用程序分配资源的特权,而节点管理器负责分配资源,例如 CPU、内存、每台机器的带宽,然后确认资源管理器。应用管理器充当资源管理器和节点管理器之间的接口,并根据两者的要求进行协商。
地图缩减:
- 通过使用分布式和并行算法,MapReduce 可以继承处理逻辑并帮助编写将大数据集转换为可管理的应用程序。
- MapReduce 使用了两个函数,即 Map() 和 Reduce(),它们的任务是:
- Map()执行数据的排序和过滤,从而以组的形式组织它们。 Map 生成一个基于键值对的结果,稍后由 Reduce() 方法处理。
- Reduce() ,顾名思义,就是通过聚合映射数据来进行汇总。简单来说,Reduce() 将 Map() 生成的输出作为输入,并将这些元组组合成更小的元组集。
猪:
Pig 基本上是由 Yahoo 开发的,它使用 Pig 拉丁语言,这是一种类似于 SQL 的基于查询的语言。
- 它是一个用于构建数据流、处理和分析海量数据集的平台。
- Pig 负责执行命令,并在后台处理 MapReduce 的所有活动。处理后,pig 将结果存储在 HDFS 中。
- Pig Latin 语言是专门为这个在 Pig Runtime 上运行的框架设计的。就像Java在 JVM 上运行的方式一样。
- Pig 有助于简化编程和优化,因此是 Hadoop 生态系统的一个主要部分。
蜂巢:
- 借助 SQL 方法和接口,HIVE 执行大型数据集的读写。但是,它的查询语言称为 HQL(Hive查询语言)。
- 它具有高度可扩展性,因为它允许实时处理和批处理。此外, Hive支持所有 SQL 数据类型,从而使查询处理更容易。
- 与查询处理框架类似,HIVE 也带有两个组件: JDBC 驱动程序和HIVE 命令行。
- JDBC 与 ODBC 驱动程序一起用于建立数据存储权限和连接,而 HIVE 命令行有助于处理查询。
象牙:
- Mahout,允许对系统或应用程序进行机器学习。机器学习,顾名思义,可以帮助系统根据某些模式、用户/环境交互或算法进行自我开发。
- 它提供了各种库或功能,例如协同过滤、聚类和分类,这些都是机器学习的概念。它允许在自己的库的帮助下根据我们的需要调用算法。
阿帕奇火花:
- 它是一个处理所有流程消耗性任务的平台,如批处理、交互式或迭代实时处理、图形转换和可视化等。
- 因此,它消耗内存资源,因此在优化方面比先前更快。
- Spark 最适合实时数据,而 Hadoop 最适合结构化数据或批处理,因此两者在大多数公司中可互换使用。
Apache HBase:
- 它是一个 NoSQL 数据库,支持各种数据,因此能够处理 Hadoop 数据库的任何内容。它提供了 Google BigTable 的功能,因此能够有效地处理大数据集。
- 有时我们需要在庞大的数据库中搜索或检索出现的小东西,必须在很短的时间内处理请求。在这种时候,HBase 就派上用场了,因为它为我们提供了一种存储有限数据的宽容方式
其他组件:除了所有这些之外,还有一些其他组件可以执行一项艰巨的任务,以使 Hadoop 能够处理大型数据集。它们如下:
- Solr、Lucene:这两个服务在一些Java库的帮助下执行搜索和索引任务,特别是Lucene是基于Java的,它也允许拼写检查机制。但是,Lucene 是由 Solr 驱动的。
- Zookeeper:在资源或 Hadoop 组件之间的协调和同步管理方面存在一个巨大的问题,这经常导致不一致。 Zookeeper 通过执行同步、基于组件间的通信、分组和维护克服了所有问题。
- Oozie: Oozie 只是执行调度程序的任务,从而调度作业并将它们绑定在一起作为一个单元。有两种作业。即 Oozie 工作流和 Oozie 协调员作业。 Oozie 工作流是需要按顺序执行的作业,而 Oozie Coordinator 作业是在给它一些数据或外部刺激时触发的作业。