在我们开始学习 Hadoop 集群之前,我们首先需要了解集群的实际含义。集群是一些东西的集合,一个简单的计算机集群是一组通过LAN(局域网)相互连接的各种计算机,集群中的节点共享数据,处理相同的任务,这个节点是好的足以作为一个单元工作意味着所有这些都可以一起工作。
同样, Hadoop 集群也是各种商品硬件(价格低廉且可用的设备)的集合。这些硬件组件作为一个单元一起工作。在Hadoop集群中,有很多节点(可以是计算机和服务器)包含Master和Slaves,Name节点和Resource Manager作为Master和数据节点,Node Manager作为Slave。 Master节点的目的是在单个Hadoop集群中引导从节点。我们设计 Hadoop 集群来存储、分析、理解和查找隐藏在包含一些关键信息的数据或数据集背后的事实。 Hadoop 集群存储不同类型的数据并对其进行处理。
- Structured-Data:像Mysql一样结构良好的数据。
- 半结构化数据:具有结构但没有数据类型的数据,如 XML、Json(Javascript 对象表示法)。
- 非结构化数据:没有音频、视频等任何结构的数据。
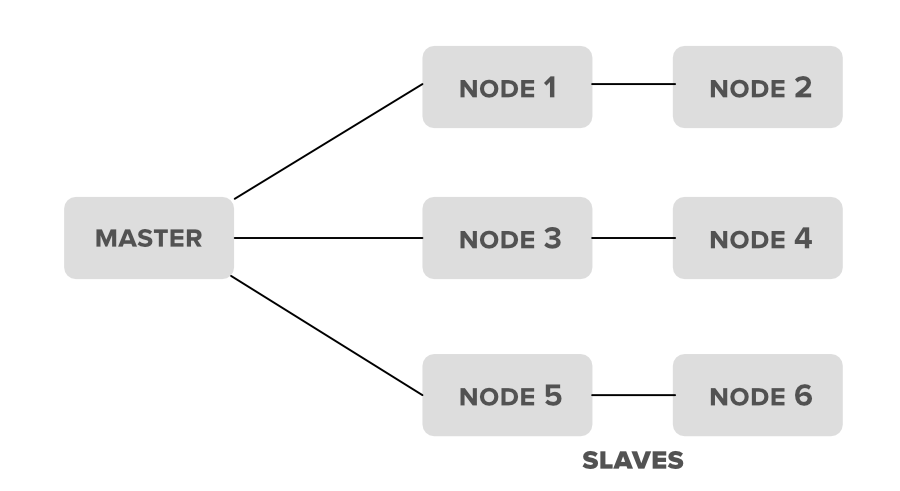
Hadoop集群架构:
Hadoop 集群属性
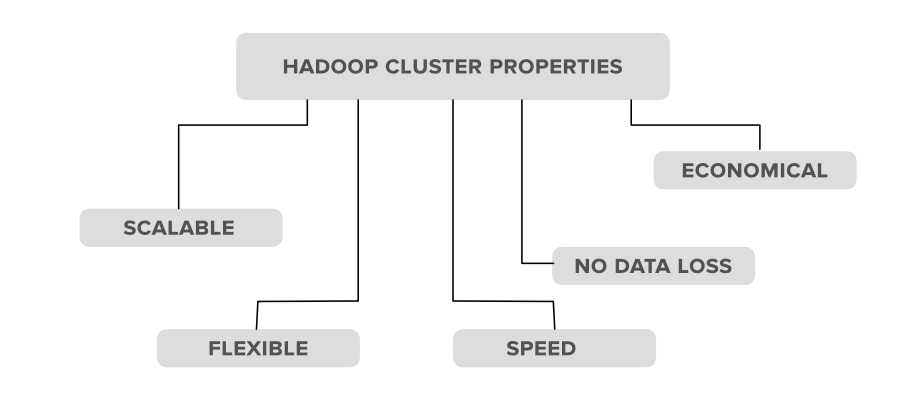
1. 可扩展性: Hadoop 集群非常有能力扩展和缩减节点的数量,即服务器或商品硬件。让我们用一个例子来看看这个可扩展属性的实际含义。假设一个组织想要在接下来的 2 个月内分析或维护大约 5PB 的数据,所以他在他的 Hadoop 集群中使用了 10 个节点(服务器)来维护所有这些数据。但现在的情况是,在这个月之间,组织收到了 2PB 的额外数据,在这种情况下,组织必须设置或升级其 Hadoop 集群系统中的服务器数量,从 10 台升级到 12 台(让我们考虑一下)来维护它。在 Hadoop 集群中扩展或缩减服务器数量的过程称为可扩展性。
2. 灵活性:这是Hadoop集群拥有的重要属性之一。根据这一特性,Hadoop 集群非常灵活,意味着它们可以处理任何类型的数据,而不管其类型和结构如何。借助此属性,Hadoop 可以处理来自在线 Web 平台的任何类型的数据。
3.速度: Hadoop集群以非常快的速度工作非常高效,因为数据分布在集群之间,也因为它的数据映射能力,即适用于主从现象的MapReduce架构。
4. 无数据丢失: Hadoop 集群中的任何节点都不会丢失数据,因为 Hadoop 集群具有在其他节点复制数据的能力。因此,在任何节点发生故障的情况下,不会丢失任何数据,因为它会跟踪该数据的备份。
5. 经济性: Hadoop集群具有很高的成本效益,因为它们在集群中拥有分布式存储技术,即数据分布在一个集群中的所有节点之间。所以在增加存储的情况下,我们只需要再增加一个硬件存储,这不是最昂贵的。
Hadoop 集群的类型
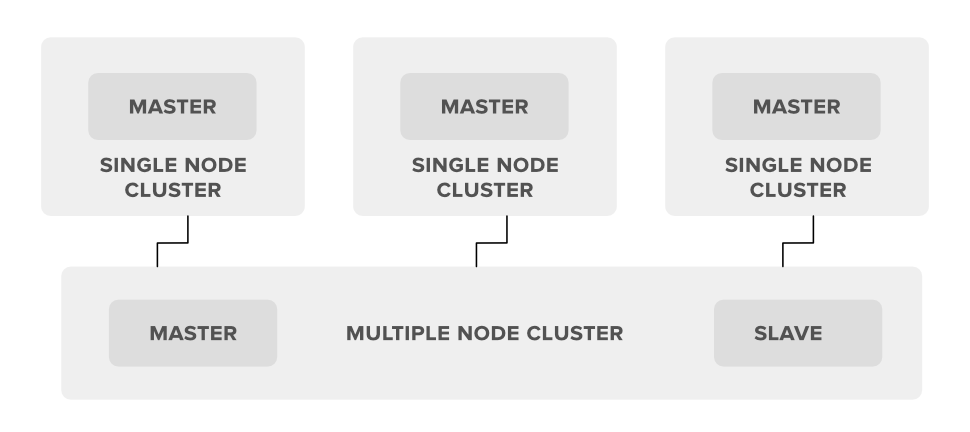
1.单节点Hadoop集群
2.多节点Hadoop集群

1. 单节点 Hadoop 集群:在单节点 Hadoop 集群中,顾名思义,集群是唯一的单个节点,这意味着我们所有的 Hadoop 守护进程,即名称节点、数据节点、辅助名称节点、资源管理器、节点管理器都将运行在同一系统或同一台机器上。这也意味着我们所有的进程都将仅由单个 JVM(Java虚拟机)进程实例处理。
2.多节点Hadoop集群:在多节点Hadoop集群中顾名思义就是包含多个节点。在这种集群中设置我们所有的 Hadoop 守护进程,将存储在同一集群设置中的不同节点中。通常,在多节点 Hadoop 集群设置中,我们尝试将更高的处理节点用于主节点,即名称节点和资源管理器,而我们将更便宜的系统用于从守护程序的 ieNode 管理器和数据节点。