大数据是一个巨大的数据集,可以拥有大量数据、速度和各种数据。例如,数十亿用户同时在 Google 上搜索,这将是一个非常大的数据集。在此,我们将讨论使用大数据(Hadoop、hive、pig)在新闻聚合器上的概念证明(POC)。并将基于 MapReduce Operations 执行操作。为了执行操作,我们将使用 HiveQL(Hive查询语言),它是一种类似 SQL 的查询语言,可以使用Hive处理结构化数据。 Hive用于使查询和分析变得容易。它是一个基于 Hadoop 的数据仓库工具。
您将看到如何使用大数据在新闻聚合器上执行 POC 的实现方法。在这里,我们将进行 POC,将能够使用 Hadoop、hive 和 pig 等大数据技术找到所有查询。和查询,如分为不同类别的新闻数量,统计表中不同标题的总出现次数,出版商名称,对已发布新闻的查询,查找标题名称的查询,以及查找字母数字 id 的查询包含关于同一故事的新闻等的集群,让我们一一讨论。
新闻聚合器的概念证明:
- 此 POC 基于新闻聚合器数据。
- 公共数据集可在网站链接下方找到。
https://archive.ics.uci.edu/ml/datasets/News+Aggregator 行业社交媒体:
数据
具有如下属性的公开数据集。
- ID –整数数字 ID。
- TITLE – 字符串类型的新闻标题。
- URL –字符串类型的 URL。
- PUBLISHER – 类型字符串的发布者名称。
- CATEGORY – 类型字符串的新闻类别。
- STORY –包含有关同一故事的新闻的集群的字母数字 ID。
- HOSTNAME –字符串类型的 URL 主机名。
- TIME – 新闻发布的大致时间。
问题陈述:
- 查找分为不同类别的新闻
- 计算表格中不同标题的总出现次数。
- 查找出版商名称和业务类别的标题。
- 查找大约发布时间的新闻。
- 从《洛杉矶时报》发布的表格中找出 5 个标题名称。
- 查找包含相同故事新闻的集群的字母数字 ID。
外壳脚本:
这个shell脚本的目的是创建一个表并执行hive命令来存储结果。
创建表:使用以下查询创建表,如下所示。
hive>create table new
(
id bigint,
title String,
url String,
publishername String,
category String,
story String,
hostname String,
time bigint
);
> row format delimited
> fields terminated by '\t'
> lines terminated by '\n'
> stored as textfile;加载表:使用以下查询加载表,如下所示。
hive>load data local inpath ‘/home/training/Desktop/news.txt’
>overwrite into table news;输出:使用以下查询显示输出。
hive>select * from news;Hive命令
1.找到一些分成不同类别的新闻。
hive >SELECT category, COUNT(*) from news GROUP BY category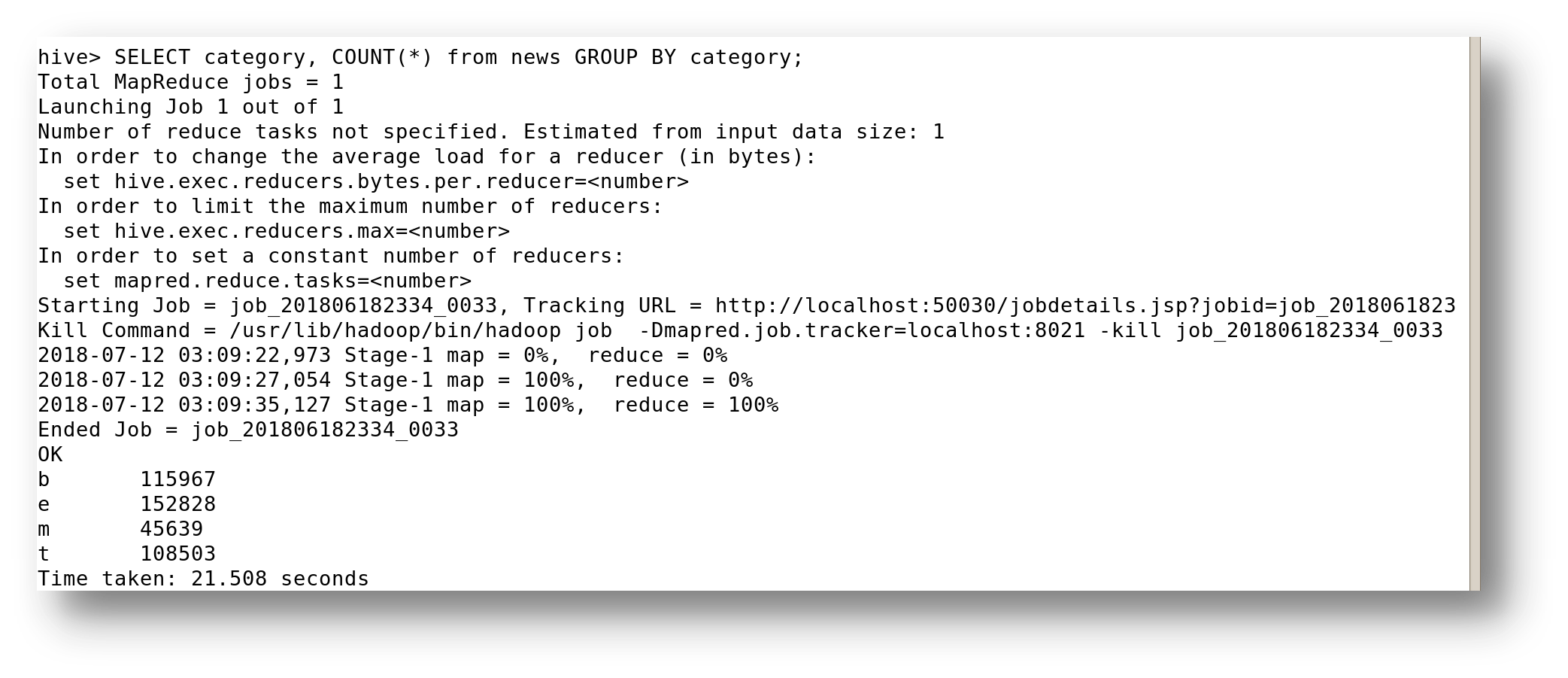
2 .计算表格中不同标题的总出现次数。
hive > select count (DISTINCT title) from news
3.查找出版商名称和业务类别的标题。
hive >select title , publishername from news where category==’b’;

4.找到大概发布时间的新闻。
hive >SELECT * from news SORT BY time DESC limit 1;
5 .从《洛杉矶时报》发布的表格中找出 5 个标题名称。
hive> SELECT title FROM news where publishername='Los Angeles Times' LIMIT 5; 
6.找到包含相同故事新闻的集群的字母数字 id。
hive>SELECT story, COUNT(*) from news GROUP BY story;
