众所周知,Hadoop是一个开源框架,主要用于存储目的以及在商品硬件集群上维护和分析大量数据或数据集,这意味着它实际上是一种数据管理工具。 Hadoop 还具有横向扩展的存储特性,这意味着我们可以根据未来的需求扩展或缩减节点数量,这确实是一个很酷的功能。
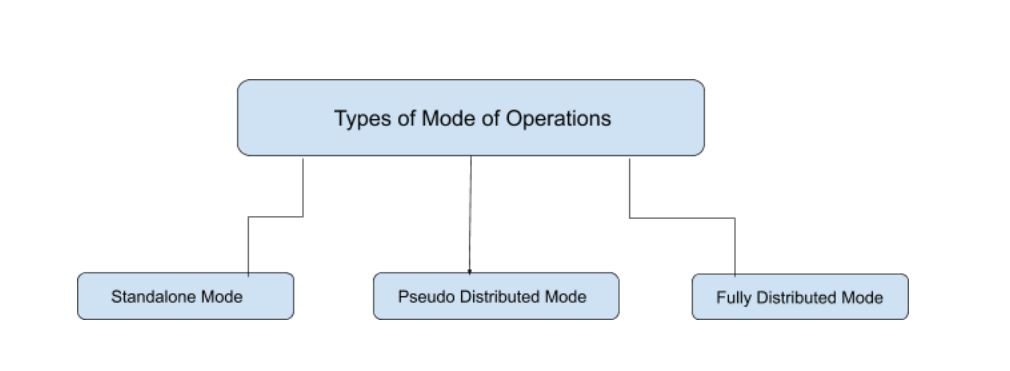
Hadoop 主要适用于 3 种不同的模式:
- 独立模式
- 伪分布式模式
- 全分布式模式
1. 单机模式
在独立模式下,没有任何守护进程会运行,即 Namenode、Datanode、Secondary Name node、Job Tracker 和 Task Tracker。我们在 Hadoop1 中使用 job-tracker 和 task-tracker 进行处理。对于 Hadoop2,我们使用资源管理器和节点管理器。独立模式也意味着我们只在单个系统中安装 Hadoop。默认情况下,Hadoop 以独立模式运行,或者我们也可以将其称为本地模式。我们在此模式下主要使用 Hadoop 进行学习、测试和调试。
在所有这三种模式中,Hadoop 在这种模式下的工作速度非常快。众所周知,HDFS(Hadoop分布式文件系统)是Hadoop的主要组件之一,用于存储权限在这种模式下没有使用。您可以将 HDFS 视为类似于 Windows 可用的文件系统,即 NTFS(新技术文件系统)和 FAT32(将数据存储在 32 位块中的文件分配表)。当您的 Hadoop 在此模式下工作时,无需为 Hadoop 环境配置文件 – hdfs-site.xml 、 mapred-site.xml 、 core-site.xml 。在这种模式下,您的所有进程都将运行在单个 JVM(Java虚拟机)上,并且这种模式只能用于小型开发目的。
2.伪分布式模式(单节点集群)
在Pseudo-distributed Mode中我们也只使用了单个节点,但主要是模拟了集群,这意味着集群内部的所有进程都会相互独立运行。 Namenode、Datanode、Secondary Name node、Resource Manager、Node Manager 等所有守护进程将作为单独的进程在单独的 JVM(Java虚拟机)上运行,或者我们可以说运行在不同的Java进程上,这就是为什么它是称为伪分布。
我们应该记住的一件事是,由于我们仅使用设置的单个节点,因此所有主进程和从进程都由单个系统处理。 Namenode 和Resource Manager 用作Master,Datanode 和Node Manager 用作slave。辅助名称节点也用作主节点。辅助名称节点的目的只是保留名称节点的每小时备份。在这种模式下,
- Hadoop 用于开发和调试目的。
- 我们的 HDFS(Hadoop 分布式文件系统)用于管理输入和输出过程。
- 我们需要更改配置文件mapred-site.xml 、 core-site.xml 、 hdfs-site.xml以设置环境。

3.全分布式模式(多节点集群)
这是最重要的一个,其中使用多个节点,其中很少有运行主守护进程的 Namenode 和资源管理器,其余的运行从守护进程的 DataNode 和节点管理器。在这里,Hadoop 将运行在机器或节点的集群上。这里使用的数据分布在不同的节点上。这实际上是 Hadoop 的生产模式,让我们在物理术语中以更好的方式澄清或理解该模式。
以 tar 文件格式或 zip 文件格式下载 Hadoop 后,将其安装到系统中并在单个系统中运行所有进程,但在完全分布式模式下,我们将此 tar 或 zip 文件解压缩到每个Hadoop 集群中的节点,然后我们将特定节点用于特定进程。在节点之间分配进程后,您将定义哪些节点作为主节点工作,或者其中哪个节点作为从节点工作。