字符串操作是分析和处理字符串以通过操作或更改字符串存在的数据来实现所需结果的过程。 Julia 提供了各种字符串操作,我们可以将其应用于字符串来实现这一点。我们将进一步详细讨论此类操作。
首先,我们创建一个字符串来操作:
Julia
# Create a string
s = "Everybody has an interesting geek in them"Julia
# find the index of occurance of the letter 'd' in the string
i = findfirst(isequal('d'), s)Julia
# find the start and end indices of occurance of the word 'geek'
r = findfirst("geek", s)Julia
# find the indices of characters with first letter 'i' and last letter 'g'
r = findfirst(r"i[\w]*g", s)Julia
# replace the word geek with champian in the string
r = replace(s, "geek" => "champian")Julia
# replace the character with first letter i and last letter g with the word adventurous
r = replace(s, r"i[\w]*g" => "adventurous")Julia
# create three strings
s1 = "Geeks"
s2 = "For"
s3 = "Geeks"
# concatenate strings
string(s1, s2, s3)Julia
# concatenate strings with characters in between
string(s1, ", ", s2, "- ", s3)Julia
# concatenate three strings with *
s1*", "*s2*", "*s3Julia
# display all characters in all of the three strings
collect.([s1, s2, s3])
# display length of the three strings
length.([s1, s2, s3])Julia
# display element matching character
# with first letter g and last letter k
# with Regekmatch type
r = match(r"g[\w]*k", s)
# display the matched character
show(r.match); println()Julia
# display characters with length
# equal to or greater than 4
r = eachmatch(r"[\w]{4, }", s)
for i in r println("\"$(i.match)\" ")
endJulia
# display characters with length equal to or greater than 4
r = collect(m.match for m = eachmatch(r"[\w]{3, }", s))Julia
# strip white spaces in the string
r = strip("Geek ")
# strip white spaces and the letter G in the string
r = strip("Geek ", ['G', ' '])Julia
# split string on ', ' character
r = split("Geeks, for, Geeks", ', ')Julia
# split string on ', ' character
r = split("Geeks, for, Geeks", ", ")Julia
# eliminating whitespaces while splitting the string
r = split("Geeks, for, Geeks", [', ', ' '],
limit = 0, keepempty = false)Julia
# joining characters or strings with ', ' in between
r = join(collect(1:7), ", ")
搜索字符串中的元素
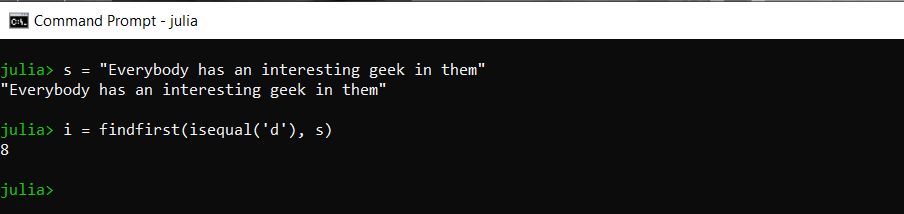
要搜索字符串的一个或多个元素,我们可以使用findfirst()函数,该函数返回我们放置的字符的第一个索引,如下所示:
朱莉娅
# find the index of occurance of the letter 'd' in the string
i = findfirst(isequal('d'), s)
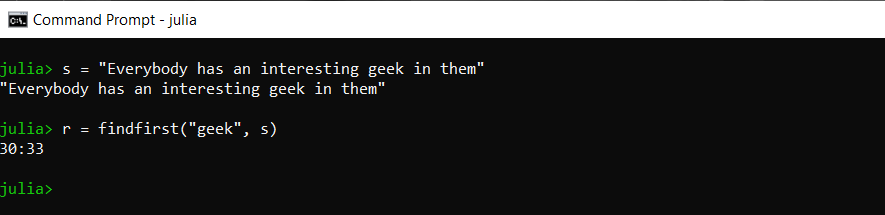
我们可以在字符串放置一个完整的单词,该单词返回该单词的开始和结束索引:
朱莉娅
# find the start and end indices of occurance of the word 'geek'
r = findfirst("geek", s)
我们还可以通过指定单词的首尾字母来搜索单词:
朱莉娅
# find the indices of characters with first letter 'i' and last letter 'g'
r = findfirst(r"i[\w]*g", s)

替换字符串的元素
用其他元素替换字符串中的元素或字符可以使用replace()函数,通过以相同的方式指定要替换的字符。
朱莉娅
# replace the word geek with champian in the string
r = replace(s, "geek" => "champian")

朱莉娅
# replace the character with first letter i and last letter g with the word adventurous
r = replace(s, r"i[\w]*g" => "adventurous")

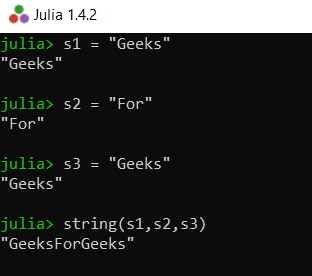
字符串的串联
串联是将事物串联在一起的操作。它是最有用的字符串操作之一,Julia 提供了一种非常简单的方法来实现它。
朱莉娅
# create three strings
s1 = "Geeks"
s2 = "For"
s3 = "Geeks"
# concatenate strings
string(s1, s2, s3)
我们也可以在字符串之间放置任何字符:
朱莉娅
# concatenate strings with characters in between
string(s1, ", ", s2, "- ", s3)

使用“ *”运算符 对于直接字符串连接:
朱莉娅
# concatenate three strings with *
s1*", "*s2*", "*s3

获取字符串的大小
collect()和length()函数可用于分别获取多个字符串的所有字符和长度:
朱莉娅
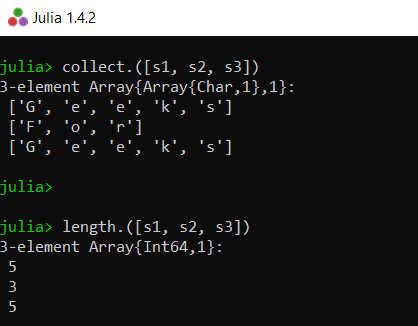
# display all characters in all of the three strings
collect.([s1, s2, s3])
# display length of the three strings
length.([s1, s2, s3])
执行匹配操作
Julia 允许我们使用match()函数从左到右扫描字符串以查找第一个匹配项(指定的起始索引可选),它返回 RegexMatch 类型:
朱莉娅
# display element matching character
# with first letter g and last letter k
# with Regekmatch type
r = match(r"g[\w]*k", s)
# display the matched character
show(r.match); println()

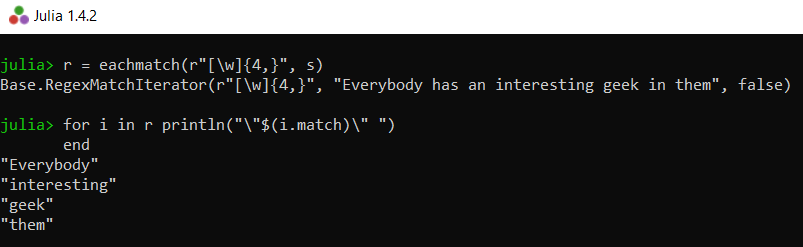
我们可以使用eachmatch()函数在字符串上运行迭代。以下示例显示了具有指定长度的匹配元素的实现。
朱莉娅
# display characters with length
# equal to or greater than 4
r = eachmatch(r"[\w]{4, }", s)
for i in r println("\"$(i.match)\" ")
end
朱莉娅
# display characters with length equal to or greater than 4
r = collect(m.match for m = eachmatch(r"[\w]{3, }", s))

剥离、拆分和连接操作
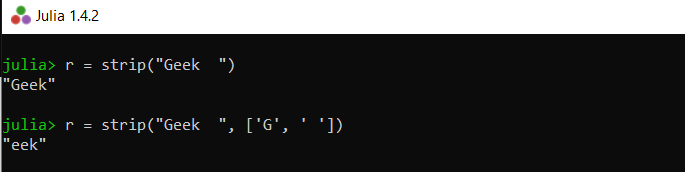
strip()函数用于消除字符串的某些字符。如果在函数没有提到我们想要消除的字符, strip()函数消除字符串中的空格。我们可以通过将它们作为第二个参数,其中在下面的例子中所表示的条带()函数提我们想要的字符串中消除字符:
朱莉娅
# strip white spaces in the string
r = strip("Geek ")
# strip white spaces and the letter G in the string
r = strip("Geek ", ['G', ' '])
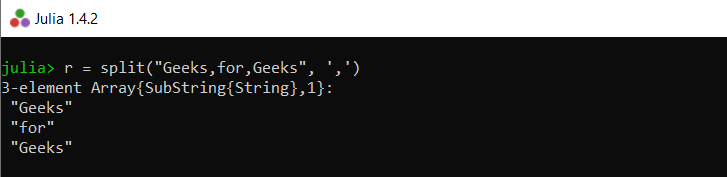
split()函数可用于在特定字符上拆分字符串:
朱莉娅
# split string on ', ' character
r = split("Geeks, for, Geeks", ', ')
朱莉娅
# split string on ', ' character
r = split("Geeks, for, Geeks", ", ")

我们还可以在删除以下示例中表示的字符的同时进行拆分:
朱莉娅
# eliminating whitespaces while splitting the string
r = split("Geeks, for, Geeks", [', ', ' '],
limit = 0, keepempty = false)
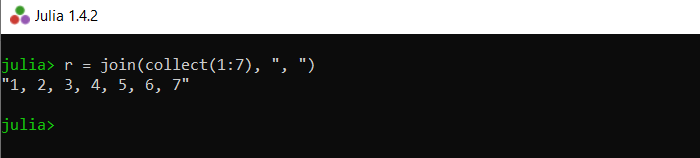
join()函数与 split 相反,我们可以用它来连接字符串,中间有一个特定的字符。
朱莉娅
# joining characters or strings with ', ' in between
r = join(collect(1:7), ", ")