Julia 中的循环向量化
向量化用于在不使用循环的情况下加速代码。使用这样的函数可以帮助有效地最小化代码的运行时间。在高级语言中向量化这个词有两种含义,它们指的是不同的东西。
当我们谈论Python/Numpy/Matlab/等中的矢量化代码时,我们通常指的是代码如下:
x = [1, 2, 3]
y = x + 1
比:
x = [1, 2, 3]
for i in 1:3
y[i] = x[i] + 1
end
第一个代码块中的向量化类型在Python和Matlab等语言中非常有用,因为通常这些语言中的每个操作都趋于缓慢。每次迭代都涉及调用+运算符、进行数组查找、类型转换等,并且重复此迭代给定次数会使整体计算变慢。因此,向量化代码更快,并且只需为整个向量x查找一次+操作而不是为每个元素x[i]查找一次。
我们在Julia中没有遇到这样的问题,其中
y .= x .+ 1
和
for i in 1:3
y[i] = x[i] + 1
end
两者都编译成几乎相同的代码并且性能相当。因此,在Julia中不需要Python和Matlab中需要的那种矢量化。
In fact, each vectorized operation ends up generating a new temporary array and executing a separate loop, which leads to a lot of overhead when multiple vectorized operations are combined.
So in some cases, we may observe vectorized code to run slower.
另一种向量化涉及通过使用SIMD(单指令,多数据)指令来提高性能,并指的是CPU 对数据块进行操作的能力。
单指令多数据(SIMD)
以下代码显示了一个简单的 sum函数(返回数组arr中所有元素的总和):
function mysum(arr::Vector)
total = zero(eltype(arr))
for x in arr
total += x
end
return total
end
此操作通常可以可视化为在每次迭代中将总数与数组元素的串行相加。
# generate random data
arr = rand(10 ^ 5);
using BenchmarkTools
@benchmark mysum(arr)
输出 : 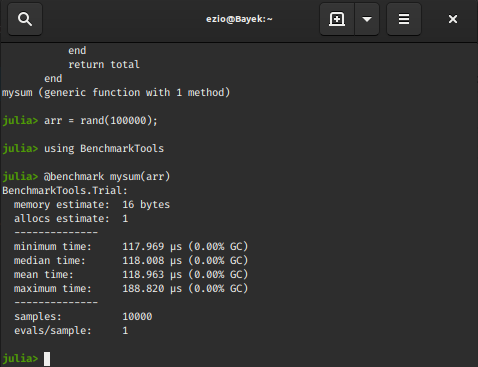
使用 SIMD 宏:
function mysum1(arr::Vector)
total = zero(eltype(arr))
@simd for x in arr
total += x
end
return total
end
# benchmark the mysum1 function
@benchmark mysum1(arr)
输出: 
我们可以清楚地看到使用 SIMD 宏后的性能提升。
那么究竟发生了什么?
通过利用SIMD 指令集(大多数英特尔® CPU 的内置功能),加法操作分两步执行:
During the first step, intermediate values are accumulated n at a time (n depends on the CPU hardware).
In a so called reduction step, the final n elements are summed together.
现在问题出现了,我们如何将 SIMD 向量化和语言的向量化功能结合起来,从语言的编译器和 CPU 中获得更高的性能?在 Julia 中,我们使用LoopVectorization.jl包来回答它。
循环向量化
LoopVectorization.jl是 Julia 包,它提供了结合SIMD 矢量化和循环重新排序以提高性能的宏和函数。
@avx 宏
它注释一个for 循环,或一组嵌套的 for 循环,其边界在迭代中是恒定的,以优化计算。
让我们考虑经典的点积问题。要了解有关点积及其在Python中的矢量化实现的更多信息,请查看本文。
在下面的示例中,我们将使用不同类型的矢量化对相同的代码进行基准测试。
例子:
# Without using any macro
function dotProd(x, y)
prod = zero(eltype(x))
for i in eachindex(x, y)
prod += x[i] * y[i]
end
prod
end
# using the simd macro
function dotProd_simd(x, y)
prod = zero(eltype(x))
@simd for i in eachindex(x, y)
prod += x[i] * y[i]
end
prod
end
# using the avx macro
using LoopVectorization
function dotProd_avx(x, y)
prod = zero(eltype(x))
@avx for i in eachindex(x, y)
prod += x[i] * y[i]
end
prod
end
输出 : 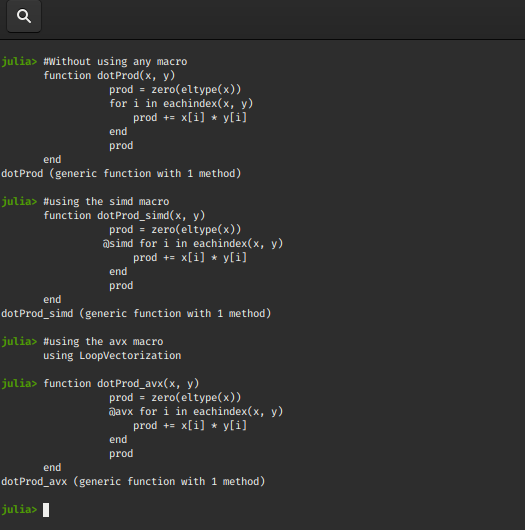
比较三个函数:
using BenchmarkTools
# generating random data
x = rand(10 ^ 5);
y = rand(10 ^ 5);
# benchmark the function without any macro
@benchmark dotProd(x, y)
# benchmark the function with simd macro
@benchmark dotProd_simd(x, y)
# benchmark the function with avx macro
@benchmark dotProd_avx(x, y)
输出 : 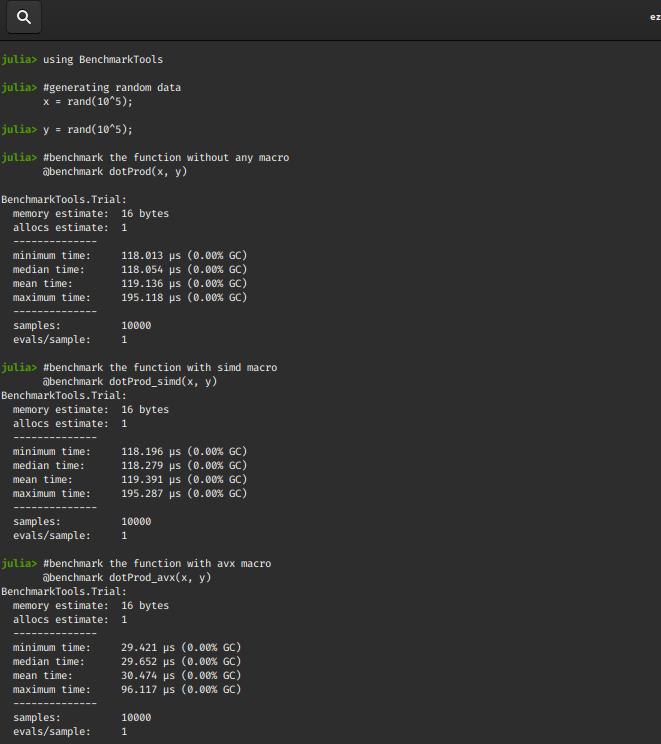
我们观察到@avx 宏的性能最好!对于较大尺寸的 x 和 y,时间间隔通常会增加。
矢量化便利功能
地图
这只是一个 SIMD 矢量化映射函数。
句法 :
vmap!(f, destination_variable, x::AbstractArray)
vmap!(f, destination_varaible, x::AbstractArray, yb::AbstractArray, …)
It applies f to each element of x (or paired elements of x, y, …) and storing the result in destination-variable.
If the ! symbol is removed a new array is returned instead of the destination_variable.
vmap(f, x::AbstractArray)
vmap(f, x::AbstractArray, yb::AbstractArray, …)
例子:
# the function f
f(x, y) = 1 / (1 + exp(x-y))
# generate random data
x = rand(10^5);
y = rand(10^5);
# destination variable of the same dims as x
z = similar(x);
输出 : 
# benchmark the map function
@benchmark map!(f, $z, $x, $y)
# benchmark the vmap function
@benchmark vmap!(f, $z, $x, $y)
输出 : 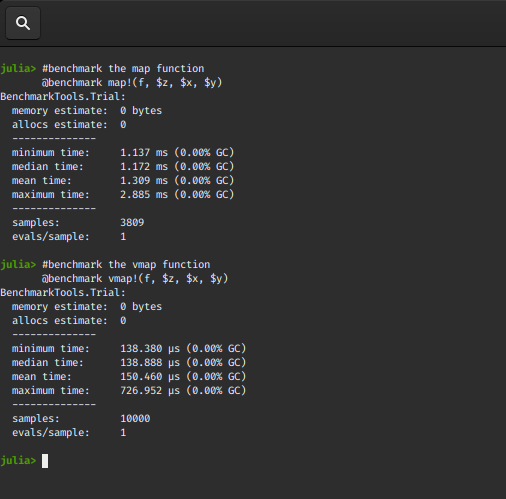
我们再次观察到矢量化映射函数的执行速度相当快。
让我们看一下vmap函数的一些调整版本。
vmapnt
它是vmap的变体,可以提高在vmap过程中不需要destination_variable的性能。
句法 :
vmapnt(f, x::AbstractArray)
vmapnt(f, x::AbstractArray, y::AbstractArray, ...)
vmapnt!(f, destination_variable, x::AbstractArray, y::AbstractArray, ...)
这是使用非时间存储操作的矢量化地图实现。
这意味着如果参数很长(如前面的例子),写操作
到destination_variable不会去CPU 的缓存。如果我们不会立即从这些值中读取,这可以提高性能,因为写入不会污染缓存。
vmapntt
它是vmapnt的线程变体。
句法 :
vmapntt(f, x::AbstractArray)
vmapntt(f, x::AbstractArray, y::AbstractArray, ...)
vmapntt!
它类似于vmapnt! ,但使用Threads.@threads进行并行执行。
句法 :
vmapntt!(f, destination_variable, x::AbstractArray, y::AbstractArray, ...)
过滤器
它是一个SIMD 向量化过滤器,返回一个数组,其中包含f返回true的x元素。
句法 :
vfilter(f, x::AbstractArray)
过滤器!
这是一个SIMD 矢量化过滤器! ,删除x中f为false的元素。
句法 :
vfilter(f, x::AbstractArray)
例子:
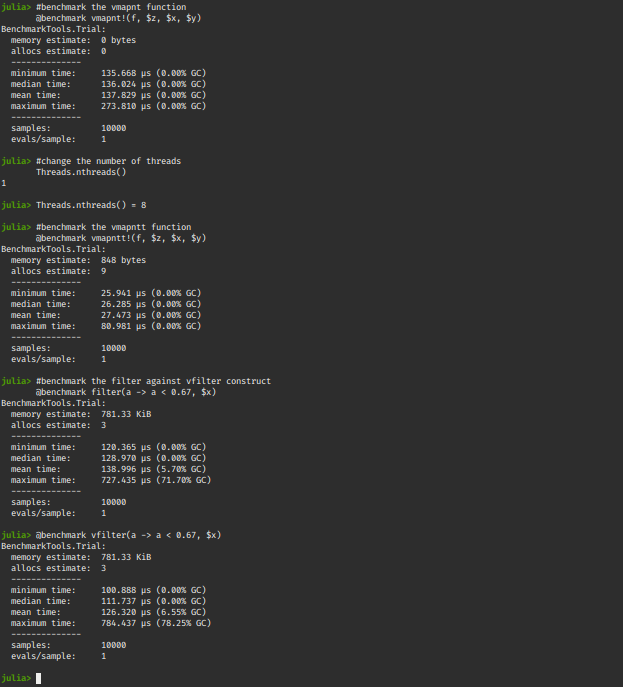
# benchmark the vmapnt function
@benchmark vmapnt!(f, $z, $x, $y)
# change the number of threads
Threads.nthreads()
Threads.nthreads() = 8
Threads.nthreads()
# benchmark the vmapntt function
@benchmark vmapntt!(f, $z, $x, $y)
# benchmark the filter against vfilter construct
@benchmark filter(a -> a < 0.67, $x)
@benchmark vfilter(a -> a < 0.67, $x)
输出: