📌 相关文章
- Apache Flink-库(1)
- 什么是 Apache Flink?
- 什么是 Apache Flink?(1)
- Apache Flink-运行Flink程序
- Apache Flink-运行Flink程序(1)
- Apache Flink-创建Flink应用程序
- Apache Flink教程
- Apache Flink教程(1)
- Apache Flink-设置/安装
- Apache Flink-设置安装(1)
- 讨论Apache Flink
- 讨论Apache Flink(1)
- Apache Flink-表API和SQL
- Apache Flink-表API和SQL(1)
- Apache Flink-体系结构
- Apache Flink-体系结构(1)
- Apache Flink-Flink vs Spark与Hadoop
- Apache Flink-Flink vs Spark与Hadoop(1)
- Apache Flink-有用的资源
- Apache Flink-有用的资源(1)
- Apache Flink-用例
- Apache Flink-用例(1)
- Apache Flink-大数据平台(1)
- Apache Flink-大数据平台
- Apache Flink-机器学习
- Apache Flink-机器学习(1)
- Apache Flink-结论
- Apache Flink-结论(1)
- Apache Flink-API概念
📜 Apache Flink-简介
📅 最后修改于: 2020-10-30 10:07:51 🧑 作者: Mango
Apache Flink是可以处理流数据的实时处理框架。它是一个开源流处理框架,用于高性能,可伸缩和准确的实时应用程序。它具有真正的流模型,并且不会将输入数据作为批处理或微批处理。
Apache Flink由Data Artisans公司创建,现在由Apache Flink社区根据Apache许可进行开发。到目前为止,这个社区有479位贡献者和15500多个提交。
Apache Flink上的生态系统
下图显示了Apache Flink生态系统的不同层-
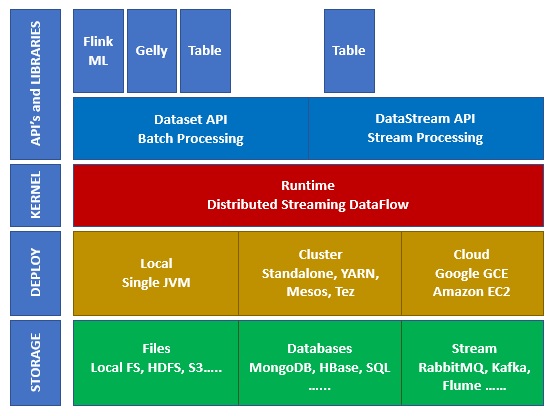
存储
Apache Flink具有多个可以读取/写入数据的选项。以下是基本存储列表-
- HDFS(Hadoop分布式文件系统)
- 本地文件系统
- S3
- RDBMS(MySQL,Oracle,MS SQL等)
- MongoDB
- HBase的
- 阿帕奇·卡夫卡
- 阿帕奇水槽
部署
您可以在本地模式,集群模式或云上部署Apache Fink。群集模式可以是独立模式,YARN,MESOS。
在云上,Flink可以部署在AWS或GCP上。
核心
这是运行时层,提供了分布式处理,容错能力,可靠性,本地迭代处理能力等。
API和库
这是Apache Flink的顶层,也是最重要的层。它具有负责批处理的Dataset API和负责流处理的Datastream API。还有其他库,例如Flink ML(用于机器学习),Gelly(用于图形处理),SQL表格。该层为Apache Flink提供了多种功能。