- Apache Flink-库(1)
- Apache Flink-库
- 什么是 Apache Flink?
- 什么是 Apache Flink?(1)
- Apache Flink-运行Flink程序(1)
- Apache Flink-运行Flink程序
- Apache Flink-创建Flink应用程序
- Apache Flink教程
- Apache Flink教程(1)
- Apache Flink-简介
- Apache Flink-设置/安装
- Apache Flink-设置安装(1)
- 讨论Apache Flink
- 讨论Apache Flink(1)
- Apache Flink-表API和SQL(1)
- Apache Flink-表API和SQL
- Apache Flink-Flink vs Spark与Hadoop(1)
- Apache Flink-Flink vs Spark与Hadoop
- Apache Flink-有用的资源(1)
- Apache Flink-有用的资源
- Apache Flink-用例
- Apache Flink-用例(1)
- Apache Flink-大数据平台(1)
- Apache Flink-大数据平台
- Apache Flink-机器学习
- Apache Flink-机器学习(1)
- Apache Flink-结论
- Apache Flink-结论(1)
- Apache Flink-API概念(1)
📅 最后修改于: 2020-10-30 10:08:12 🧑 作者: Mango
Apache Flink在Kappa体系结构上工作。 Kappa体系结构具有单个处理器-流,该流将所有输入视为流,而流引擎则实时处理数据。 kappa体系结构中的批处理数据是流的一种特殊情况。
下图显示了Apache Flink体系结构。
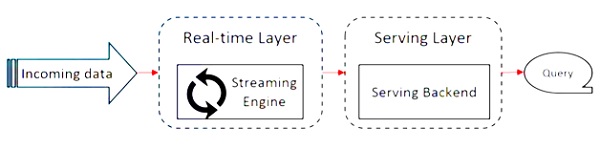
Kappa体系结构的关键思想是通过单个流处理引擎处理批处理数据和实时数据。
大多数大数据框架都在Lambda体系结构上工作,该体系结构具有用于批处理和流数据的单独处理器。在Lambda架构中,您具有用于批处理和流视图的单独的代码库。为了查询和获取结果,需要合并代码库。不维护单独的代码库/视图并合并它们是很痛苦的,但是Kappa体系结构解决了这个问题,因为它只有一个视图-实时,因此不需要合并代码库。
这并不意味着Kappa架构会取代Lambda架构,它完全取决于用例和决定哪种架构更可取的应用程序。
下图显示了Apache Flink作业执行架构。
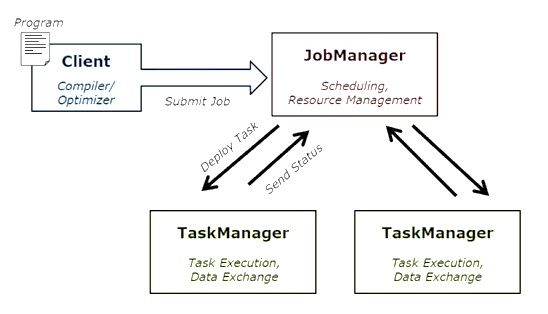
程序
这是一段代码,您可以在Flink群集上运行。
客户
它负责获取代码(程序)并构造作业数据流图,然后将其传递给JobManager。它还检索作业结果。
工作经理
从客户端收到作业数据流图后,它负责创建执行图。它将作业分配给集群中的TaskManager,并监督作业的执行。
任务管理器
它负责执行JobManager分配的所有任务。所有TaskManager均以指定的并行度在各自的插槽中运行任务。负责将任务状态发送到JobManager。
Apache Flink的功能
Apache Flink的功能如下-
-
它具有一个流处理器,可以运行批处理程序和流程序。
-
它可以闪电般的速度处理数据。
-
Java,Scala和Python可用的API。
-
提供用于所有常见操作的API,这对于程序员来说非常容易使用。
-
以低延迟(纳秒)和高吞吐量处理数据。
-
它的容错能力。如果节点,应用程序或硬件出现故障,则不会影响群集。
-
可以轻松地与Apache Hadoop,Apache MapReduce,Apache Spark,HBase和其他大数据工具集成。
-
可以自定义内存管理以进行更好的计算。
-
它具有高度的可扩展性,可以在一个集群中扩展到数千个节点。
-
在Apache Flink中,窗口化非常灵活。
-
提供图处理,机器学习,复杂事件处理库。