使用Python进行数据分析和可视化
Python是一种用于进行数据分析的出色语言,主要是因为以数据为中心的Python包的奇妙生态系统。 Pandas就是其中之一,它使导入和分析数据变得更加容易。在本文中,我使用 Pandas 分析了来自流行的“statweb.stanford.edu”网站的联合国公共数据集的 Country Data.csv 文件中的数据。
在分析印度国家数据时,我介绍了 Pandas 的关键概念如下。在阅读本文之前,请大致了解 matplotlib 和 csv 的基础知识。
安装
安装 pandas 最简单的方法是使用 pip:
pip install pandas或者,从这里下载
在 Pandas 中创建数据框
数据框的创建是通过使用pd.Series方法将多个系列传递给 DataFrame 类来完成的。在这里,它传入两个 Series 对象,s1 作为第一行,s2 作为第二行。
例子:
# assigning two series to s1 and s2
s1 = pd.Series([1,2])
s2 = pd.Series(["Ashish", "Sid"])
# framing series objects into data
df = pd.DataFrame([s1,s2])
# show the data frame
df
# data framing in another way
# taking index and column values
dframe = pd.DataFrame([[1,2],["Ashish", "Sid"]],
index=["r1", "r2"],
columns=["c1", "c2"])
dframe
# framing in another way
# dict-like container
dframe = pd.DataFrame({
"c1": [1, "Ashish"],
"c2": [2, "Sid"]})
dframe
输出:
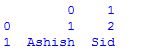


使用 Pandas 导入数据
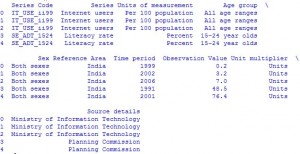
第一步是读取数据。数据存储为逗号分隔值或 csv 文件,其中每一行由新行分隔,每一列由逗号 (,) 分隔。为了能够在Python中处理数据,需要将 csv 文件读入 Pandas DataFrame。 DataFrame 是一种表示和处理表格数据的方法。表格数据有行和列,就像这个 csv 文件一样(点击下载)。
例子:
# Import the pandas library, renamed as pd
import pandas as pd
# Read IND_data.csv into a DataFrame, assigned to df
df = pd.read_csv("IND_data.csv")
# Prints the first 5 rows of a DataFrame as default
df.head()
# Prints no. of rows and columns of a DataFrame
df.shape
输出:
29,10
使用 Pandas 索引 DataFrame
可以使用pandas.DataFrame.iloc方法进行索引。 iloc 方法允许按位置检索尽可能多的行和列。
例子:
# prints first 5 rows and every column which replicates df.head()
df.iloc[0:5,:]
# prints entire rows and columns
df.iloc[:,:]
# prints from 5th rows and first 5 columns
df.iloc[5:,:5]
在 Pandas 中使用标签进行索引
可以使用pandas.DataFrame.loc方法对标签进行索引,该方法允许使用标签而不是位置进行索引。
例子:
# prints first five rows including 5th index and every columns of df
df.loc[0:5,:]
# prints from 5th rows onwards and entire columns
df = df.loc[5:,:]
上面的内容实际上看起来与 df.iloc[0:5,:] 没有太大区别。这是因为虽然行标签可以采用任何值,但我们的行标签与位置完全匹配。但是在处理数据时,列标签可以让事情变得更容易。例子:
# Prints the first 5 rows of Time period
# value
df.loc[:5,"Time period"]
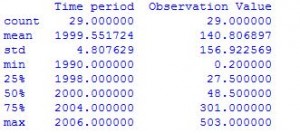
使用 Pandas 进行 DataFrame 数学运算
数据帧的计算可以使用 pandas 工具的统计函数来完成。
例子:
# computes various summary statistics, excluding NaN values
df.describe()
# for computing correlations
df.corr()
# computes numerical data ranks
df.rank()
![]()

熊猫绘图
这些示例中的绘图是使用引用 matplotlib API 的标准约定制作的,该 API 提供了 pandas 的基础知识,可以轻松创建美观的绘图。
例子:
# import the required module
import matplotlib.pyplot as plt
# plot a histogram
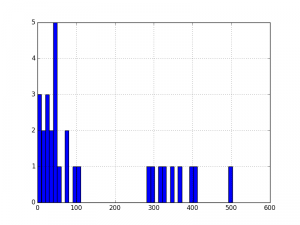
df['Observation Value'].hist(bins=10)
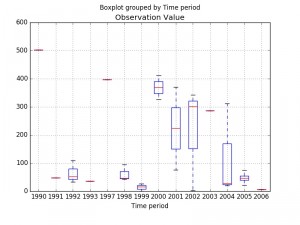
# shows presence of a lot of outliers/extreme values
df.boxplot(column='Observation Value', by = 'Time period')
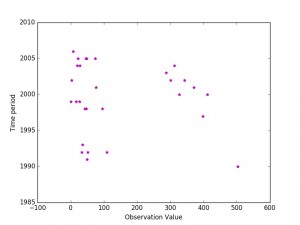
# plotting points as a scatter plot
x = df["Observation Value"]
y = df["Time period"]
plt.scatter(x, y, label= "stars", color= "m",
marker= "*", s=30)
# x-axis label
plt.xlabel('Observation Value')
# frequency label
plt.ylabel('Time period')
# function to show the plot
plt.show()
使用Python进行数据分析和可视化 |设置 2
参考:
- http://pandas.pydata.org/pandas-docs/stable/tutorials.html
- https://www.datacamp.com