使用Python Seaborn 进行数据可视化
数据可视化是以图形格式呈现数据。它对于数据分析非常重要,主要是因为以数据为中心的Python包的奇妙生态系统。它有助于理解数据,然而,它是复杂的,通过以简单易懂的格式总结和呈现大量数据,有助于清晰有效地传达信息,从而了解数据的重要性。

Pandas 和 Seaborn就是其中之一,它们使导入和分析数据变得更加容易。在本文中,我们将使用 Pandas 和 Seaborn 来分析数据。
熊猫
Pandas提供用于清理和处理数据的工具。它是最流行的用于数据分析的Python库。在 Pandas 中,数据表称为数据框。
所以,让我们从创建 Pandas 数据框开始:
示例 1:
Python3
# Python code demonstrate creating
import pandas as pd
# initialise data of lists.
data = {'Name':[ 'Mohe' , 'Karnal' , 'Yrik' , 'jack' ],
'Age':[ 30 , 21 , 29 , 28 ]}
# Create DataFrame
df = pd.DataFrame( data )
# Print the output.
dfPython3
# import module
import pandas
# load the csv
data = pandas.read_csv("nba.csv")
# show first 5 column
data.head()Python3
# Importing libraries
import numpy as np
import seaborn as sns
# Selecting style as white,
# dark, whitegrid, darkgrid
# or ticks
sns.set( style = "white" )
# Generate a random univariate
# dataset
rs = np.random.RandomState( 10 )
d = rs.normal( size = 50 )
# Plot a simple histogram and kde
# with binsize determined automatically
sns.distplot(d, kde = True, color = "g")Python3
# import module
import seaborn as sns
import pandas
# loading csv
data = pandas.read_csv("nba.csv")
# ploting lineplot
sns.lineplot( data['Age'], data['Weight'])Python3
# import module
import seaborn as sns
import pandas
# read the csv data
data = pandas.read_csv("nba.csv")
# plot
sns.lineplot(data['Age'],data['Weight'], hue =data["Position"])Python3
# import module
import seaborn
import pandas
# load csv
data = pandas.read_csv("nba.csv")
# plotting
seaborn.scatterplot(data['Age'],data['Weight'])Python3
import seaborn
import pandas
data = pandas.read_csv("nba.csv")
seaborn.scatterplot( data['Age'], data['Weight'], hue =data["Position"])Python3
# import module
import seaborn as sns
import pandas
# read csv and ploting
data = pandas.read_csv( "nba.csv" )
sns.boxplot( data['Age'] )Python3
# import module
import seaborn as sns
import pandas
# read csv and ploting
data = pandas.read_csv( "nba.csv" )
sns.boxplot( data['Age'], data['Weight'])Python3
# import module
import seaborn as sns
import pandas
# read csv and plot
data = pandas.read_csv("nba.csv")
sns.violinplot(data['Age'])Python3
# import module
import seaborn
seaborn.set(style = 'whitegrid')
# read csv and plot
data = pandas.read_csv("nba.csv")
seaborn.violinplot(x ="Age", y ="Weight",data = data)Python3
# import module
import seaborn
seaborn.set(style = 'whitegrid')
# read csv and plot
data = pandas.read_csv( "nba.csv" )
seaborn.swarmplot(x = data["Age"])Python3
# import module
import seaborn
seaborn.set(style = 'whitegrid')
# read csv and plot
data = pandas.read_csv("nba.csv")
seaborn.swarmplot(x ="Age", y ="Weight",data = data)Python3
# import module
import seaborn
seaborn.set(style = 'whitegrid')
# read csv and plot
data = pandas.read_csv("nba.csv")
seaborn.barplot(x =data["Age"])Python3
# import module
import seaborn
seaborn.set(style = 'whitegrid')
# read csv and plot
data = pandas.read_csv("nba.csv")
seaborn.barplot(x ="Age", y ="Weight", data = data)Python3
# import module
import seaborn
seaborn.set(style = 'whitegrid')
# read csv and plot
data = pandas.read_csv("nba.csv")
seaborn.pointplot(x = "Age", y = "Weight", data = data)Python3
# import module
import seaborn
seaborn.set(style = 'whitegrid')
# read csv and plot
data = pandas.read_csv("nba.csv")
seaborn.countplot(data["Age"])Python3
# importing the required libraries
from sklearn import datasets
import pandas as pd
import seaborn as sns
# Setting up the Data Frame
iris = datasets.load_iris()
iris_df = pd.DataFrame(iris.data, columns=['Sepal_Length',
'Sepal_Width', 'Patal_Length', 'Petal_Width'])
iris_df['Target'] = iris.target
iris_df['Target'].replace([0], 'Iris_Setosa', inplace=True)
iris_df['Target'].replace([1], 'Iris_Vercicolor', inplace=True)
iris_df['Target'].replace([2], 'Iris_Virginica', inplace=True)
# Plotting the KDE Plot
sns.kdeplot(iris_df.loc[(iris_df['Target'] =='Iris_Virginica'),
'Sepal_Length'], color = 'b', shade = True, Label ='Iris_Virginica')Python3
# import module
import seaborn as sns
import pandas
# read top 5 column
data = pandas.read_csv("nba.csv").head()
sns.kdeplot( data['Age'], data['Number'])Python3
# import module
import seaborn as sns
import pandas
# read csv and ploting
data = pandas.read_csv( "nba.csv" )
sns.boxplot( data['Age'], data['Height'])Python3
# import module
import seaborn as sns
import pandas
# read top 5 column
data = pandas.read_csv("nba.csv").head()
sns.kdeplot( data['Age'], data['Weight'])Python3
# import module
import seaborn as sns
import pandas
# read top 5 column
data = pandas.read_csv("nba.csv").head()
sns.distplot( data['Age'])输出:
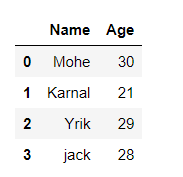
示例2:从系统加载CSV数据并通过pandas显示。
蟒蛇3
# import module
import pandas
# load the csv
data = pandas.read_csv("nba.csv")
# show first 5 column
data.head()
输出:
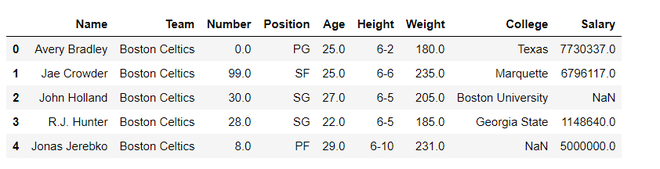
海伯恩
Seaborn 是一个了不起的可视化库,用于在Python中绘制统计图形。它建立在 matplotlib 库的顶部,并且也紧密集成到 Pandas 的数据结构中。
安装
对于Python环境:
pip install seaborn对于 conda 环境:
conda install seaborn让我们使用 seaborn 创建一些基本图:
蟒蛇3
# Importing libraries
import numpy as np
import seaborn as sns
# Selecting style as white,
# dark, whitegrid, darkgrid
# or ticks
sns.set( style = "white" )
# Generate a random univariate
# dataset
rs = np.random.RandomState( 10 )
d = rs.normal( size = 50 )
# Plot a simple histogram and kde
# with binsize determined automatically
sns.distplot(d, kde = True, color = "g")
输出:
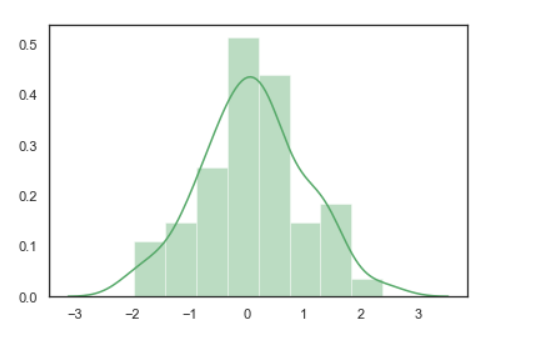
Seaborn:统计数据可视化
Seaborn 有助于可视化统计关系,为了了解数据集中的变量如何相互关联以及这种关系如何依赖于其他变量,我们进行了统计分析。此统计分析有助于可视化趋势并识别数据集中的各种模式。
这些是有助于形象化的情节:
- 线图
- 散点图
- 箱形图
- 点图
- 计数图
- 小提琴情节
- 群图
- 条形图
- KDE 图
线图:
Lineplot 是绘制 x 和 y 之间关系的最流行的图,具有多个语义分组的可能性。
Syntax : sns.lineplot(x=None, y=None)
Parameters:
x, y: Input data variables; must be numeric. Can pass data directly or reference columns in data.
让我们用线图和熊猫来可视化数据:
示例 1:
蟒蛇3
# import module
import seaborn as sns
import pandas
# loading csv
data = pandas.read_csv("nba.csv")
# ploting lineplot
sns.lineplot( data['Age'], data['Weight'])
输出:
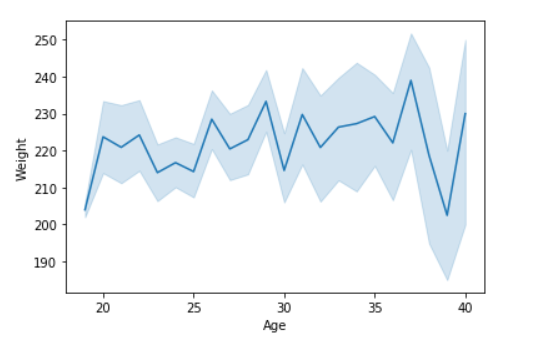
示例 2:使用色调参数绘制图形。
蟒蛇3
# import module
import seaborn as sns
import pandas
# read the csv data
data = pandas.read_csv("nba.csv")
# plot
sns.lineplot(data['Age'],data['Weight'], hue =data["Position"])
输出:
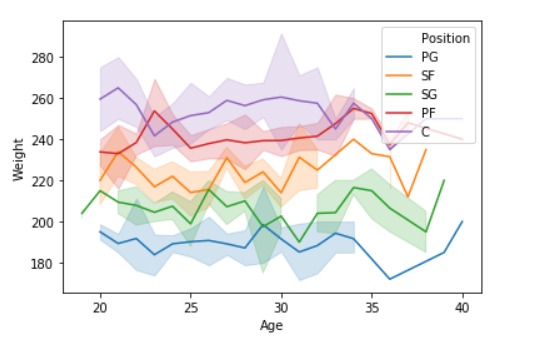
散点图:
散点图可以与多个语义分组一起使用,这有助于在连续/分类数据的图形中很好地理解。它可以绘制二维图形。
Syntax: seaborn.scatterplot(x=None, y=None)
Parameters:
x, y: Input data variables that should be numeric.
Returns: This method returns the Axes object with the plot drawn onto it.
让我们用散点图和熊猫来可视化数据:
示例 1:
蟒蛇3
# import module
import seaborn
import pandas
# load csv
data = pandas.read_csv("nba.csv")
# plotting
seaborn.scatterplot(data['Age'],data['Weight'])
输出:
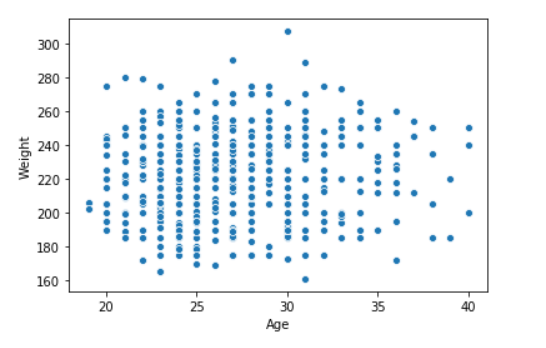
示例 2:使用色调参数绘制图形。
蟒蛇3
import seaborn
import pandas
data = pandas.read_csv("nba.csv")
seaborn.scatterplot( data['Age'], data['Weight'], hue =data["Position"])
输出:
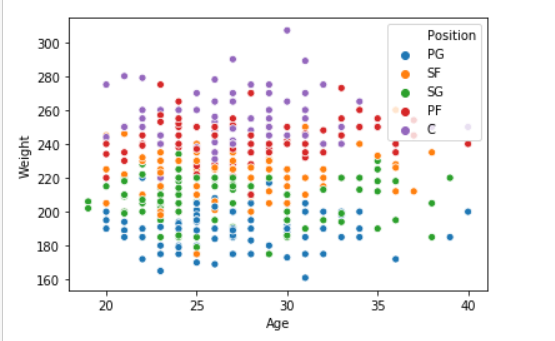
箱形图:
箱线图(或箱线图) s 是描述数值数据组通过其四分位数与连续/分类数据的可视化表示。
箱线图由 5 件事组成。
- 最低限度
- 第一个四分位数或 25%
- 中位数(第二四分位数)或 50%
- 四分之三或 75%
- 最大值
Syntax:
seaborn.boxplot(x=None, y=None, hue=None, data=None)
Parameters:
- x, y, hue: Inputs for plotting long-form data.
- data: Dataset for plotting. If x and y are absent, this is interpreted as wide-form.
Returns: It returns the Axes object with the plot drawn onto it.
用 Pandas 绘制箱线图:
示例 1:
蟒蛇3
# import module
import seaborn as sns
import pandas
# read csv and ploting
data = pandas.read_csv( "nba.csv" )
sns.boxplot( data['Age'] )
输出:
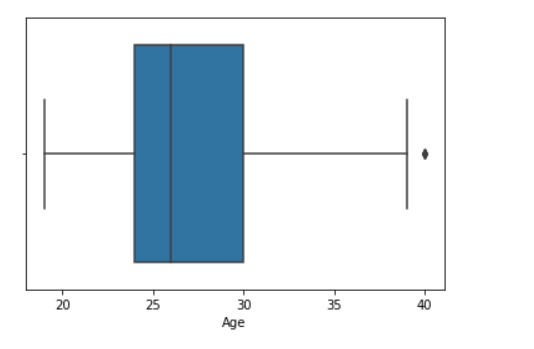
示例 2:
蟒蛇3
# import module
import seaborn as sns
import pandas
# read csv and ploting
data = pandas.read_csv( "nba.csv" )
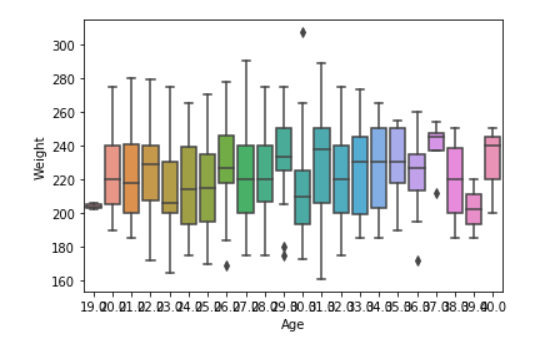
sns.boxplot( data['Age'], data['Weight'])
输出:
伏林情节:
voilin 图类似于箱线图。它显示了一个或多个分类变量的多个定量数据,以便可以比较这些分布。
Syntax: seaborn.violinplot(x=None, y=None, hue=None, data=None)
Parameters:
- x, y, hue: Inputs for plotting long-form data.
- data: Dataset for plotting.
用 Pandas 绘制小提琴图:
示例 1:
蟒蛇3
# import module
import seaborn as sns
import pandas
# read csv and plot
data = pandas.read_csv("nba.csv")
sns.violinplot(data['Age'])
输出:
示例 2:
蟒蛇3
# import module
import seaborn
seaborn.set(style = 'whitegrid')
# read csv and plot
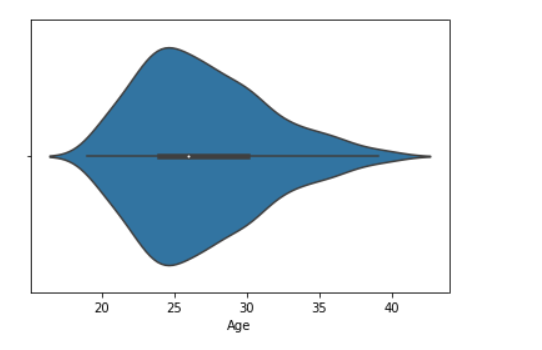
data = pandas.read_csv("nba.csv")
seaborn.violinplot(x ="Age", y ="Weight",data = data)
输出:

群图:
群图类似于带状图,我们可以根据分类数据绘制具有非重叠点的群图。
Syntax: seaborn.swarmplot(x=None, y=None, hue=None, data=None)
Parameters:
- x, y, hue: Inputs for plotting long-form data.
- data: Dataset for plotting.
用 Pandas 绘制群图:
示例 1:
蟒蛇3
# import module
import seaborn
seaborn.set(style = 'whitegrid')
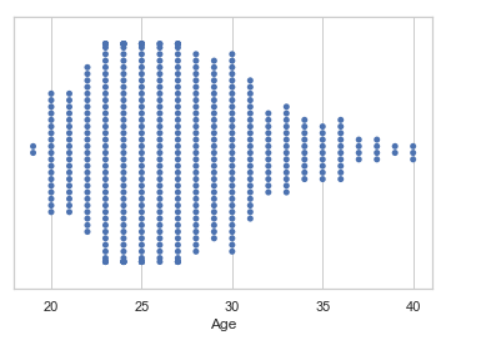
# read csv and plot
data = pandas.read_csv( "nba.csv" )
seaborn.swarmplot(x = data["Age"])
输出:
示例 2:
蟒蛇3
# import module
import seaborn
seaborn.set(style = 'whitegrid')
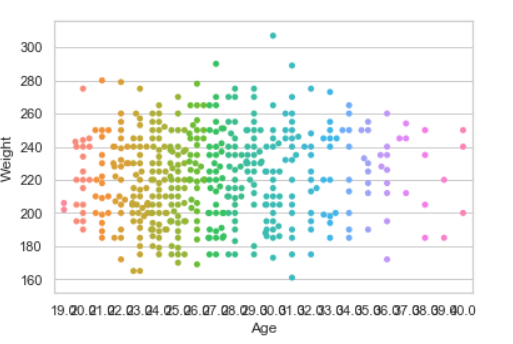
# read csv and plot
data = pandas.read_csv("nba.csv")
seaborn.swarmplot(x ="Age", y ="Weight",data = data)
输出:
条形图:
条形图表示具有每个矩形高度的数值变量的集中趋势估计,并使用误差条提供该估计周围不确定性的一些指示。
Syntax : seaborn.barplot(x=None, y=None, hue=None, data=None)
Parameters :
- x, y : This parameter take names of variables in data or vector data, Inputs for plotting long-form data.
- hue : (optional) This parameter take column name for colour encoding.
- data : (optional) This parameter take DataFrame, array, or list of arrays, Dataset for plotting. If x and y are absent, this is interpreted as wide-form. Otherwise it is expected to be long-form.
Returns : Returns the Axes object with the plot drawn onto it.
用 Pandas 绘制条形图:
示例 1:
蟒蛇3
# import module
import seaborn
seaborn.set(style = 'whitegrid')
# read csv and plot
data = pandas.read_csv("nba.csv")
seaborn.barplot(x =data["Age"])
输出:
示例 2:
蟒蛇3
# import module
import seaborn
seaborn.set(style = 'whitegrid')
# read csv and plot
data = pandas.read_csv("nba.csv")
seaborn.barplot(x ="Age", y ="Weight", data = data)
输出:

点图:
点图用于使用散点图字形显示点估计值和置信区间。点图表示通过散点图点的位置对数值变量集中趋势的估计,并使用误差线提供该估计周围不确定性的一些指示。
Syntax: seaborn.pointplot(x=None, y=None, hue=None, data=None)
Parameters:
- x, y: Inputs for plotting long-form data.
- hue: (optional) column name for color encoding.
- data: dataframe as a Dataset for plotting.
Return: The Axes object with the plot drawn onto it.
用 Pandas 绘制点图:
例子:
蟒蛇3
# import module
import seaborn
seaborn.set(style = 'whitegrid')
# read csv and plot
data = pandas.read_csv("nba.csv")
seaborn.pointplot(x = "Age", y = "Weight", data = data)
输出:
计数图:
计数图用于使用条形显示每个分类箱中的观察计数。
Syntax : seaborn.countplot(x=None, y=None, hue=None, data=None)
Parameters :
- x, y: This parameter take names of variables in data or vector data, optional, Inputs for plotting long-form data.
- hue : (optional) This parameter take column name for color encoding.
- data : (optional) This parameter take DataFrame, array, or list of arrays, Dataset for plotting. If x and y are absent, this is interpreted as wide-form. Otherwise, it is expected to be long-form.
Returns: Returns the Axes object with the plot drawn onto it.
用 Pandas 绘制计数图:
例子:
蟒蛇3
# import module
import seaborn
seaborn.set(style = 'whitegrid')
# read csv and plot
data = pandas.read_csv("nba.csv")
seaborn.countplot(data["Age"])
输出:

KDE 情节:
描述为核密度估计的 KDE 图用于可视化连续变量的概率密度。它描述了连续变量中不同值的概率密度。我们还可以为多个样本绘制单个图形,这有助于更有效的数据可视化。
Syntax: seaborn.kdeplot(x=None, *, y=None, vertical=False, palette=None, **kwargs)
Parameters:
x, y : vectors or keys in data
vertical : boolean (True or False)
data : pandas.DataFrame, numpy.ndarray, mapping, or sequence
用 Pandas 绘制 KDE 图:
示例 1:
蟒蛇3
# importing the required libraries
from sklearn import datasets
import pandas as pd
import seaborn as sns
# Setting up the Data Frame
iris = datasets.load_iris()
iris_df = pd.DataFrame(iris.data, columns=['Sepal_Length',
'Sepal_Width', 'Patal_Length', 'Petal_Width'])
iris_df['Target'] = iris.target
iris_df['Target'].replace([0], 'Iris_Setosa', inplace=True)
iris_df['Target'].replace([1], 'Iris_Vercicolor', inplace=True)
iris_df['Target'].replace([2], 'Iris_Virginica', inplace=True)
# Plotting the KDE Plot
sns.kdeplot(iris_df.loc[(iris_df['Target'] =='Iris_Virginica'),
'Sepal_Length'], color = 'b', shade = True, Label ='Iris_Virginica')
输出:

示例 2:
蟒蛇3
# import module
import seaborn as sns
import pandas
# read top 5 column
data = pandas.read_csv("nba.csv").head()
sns.kdeplot( data['Age'], data['Number'])
输出:

使用 seaborn 和 pandas 的双变量和单变量数据:
在开始之前,让我们先简单介绍一下双变量和单变量数据:
双变量数据:这种类型的数据涉及两个不同的变量。此类数据的分析处理原因和关系,并进行分析以找出两个变量之间的关系。
单变量数据:这种类型的数据仅由一个变量组成。因此,单变量数据的分析是最简单的分析形式,因为信息只处理一个变化的数量。它不处理原因或关系,分析的主要目的是描述数据并找到其中存在的模式。
让我们看一个二元数据扰动的例子:
示例 1:使用箱线图。
蟒蛇3
# import module
import seaborn as sns
import pandas
# read csv and ploting
data = pandas.read_csv( "nba.csv" )
sns.boxplot( data['Age'], data['Height'])
输出:
示例 2:使用 KDE 绘图。
蟒蛇3
# import module
import seaborn as sns
import pandas
# read top 5 column
data = pandas.read_csv("nba.csv").head()
sns.kdeplot( data['Age'], data['Weight'])
输出:
让我们看一个单变量数据分布的例子:
示例:使用 dist 图
蟒蛇3
# import module
import seaborn as sns
import pandas
# read top 5 column
data = pandas.read_csv("nba.csv").head()
sns.distplot( data['Age'])
输出:
