- 使用Python进行数据分析和可视化2
- 使用Python进行数据分析和可视化2(1)
- 使用Python进行数据分析和可视化
- 使用Python进行数据分析和可视化 |设置 2(1)
- 使用Python进行数据分析和可视化 |设置 2
- 使用Python在 Pandas 中进行数据分析(1)
- 使用Python在 Pandas 中进行数据分析
- Python | 使用Pandas进行数据分析(1)
- Python | 使用Pandas进行数据分析
- 使用 Pandas 进行数据分析
- 使用 Pandas 进行数据分析(1)
- 大数据分析-数据可视化(1)
- 大数据分析-数据可视化
- Python Pandas-可视化(1)
- Python Pandas-可视化
- Excel数据分析-数据可视化
- Excel数据分析-数据可视化(1)
- 数据可视化和数据分析之间的区别(1)
- 数据可视化和数据分析之间的区别
- 数据可视化和数据分析之间的区别
- 数据可视化和数据分析之间的区别(1)
- 数据分析的使用(1)
- 数据分析的使用
- Python|使用Python可视化 O(n)
- Python|使用Python可视化 O(n)(1)
- 使用 SciPy 进行数据分析(1)
- 使用 SciPy 进行数据分析
- 使用Python Seaborn 进行数据可视化
- 使用Python Seaborn 进行数据可视化(1)
📅 最后修改于: 2020-04-17 01:20:10 🧑 作者: Mango
Python是进行数据分析的一种出色语言,主要是因为以数据为中心的Python软件包具有奇妙的生态系统。Pandas是其中的一种,使导入和分析数据更加容易。在本文中,我使用了Pandas来分析来自流行的“ statweb.stanford.edu”网站的联合国公共数据 Data.csv文件中的数据。
在分析印度国家/地区数据时,我介绍了以下Pandas的主要概念。在阅读本文之前,请大致了解一下matplotlib和csv的基础知识。
安装
安装Pandas的最简单方法是使用pip:
pip install pandas或者,从这里下载
在Pandas中创建一个DataFrame
通过使用pd.Series方法将多个Series传递到DataFrame类中来完成数据帧的创建。在这里,它在两个Series对象中传递,s1作为第一行,s2作为第二行。
例:
# 将两个系列分配给s1和s2
s1 = pd.Series([1,2])
s2 = pd.Series(["Ashish", "Sid"])
# 将系列合成对象数据
df = pd.DataFrame([s1,s2])
# 显示数据框
df
# 以另一种方式进行数据成帧,获取索引和列值
dframe = pd.DataFrame([[1,2],["Ashish", "Sid"]],
index=["r1", "r2"],
columns=["c1", "c2"])
dframe
# 以另一种方式构建框架
dframe = pd.DataFrame({
"c1": [1, "Ashish"],
"c2": [2, "Sid"]})
dframe输出:
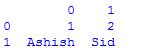


用Pandas导入数据
第一步是读取数据。数据存储为逗号分隔值或csv文件,其中每行用换行分隔,每列用逗号(,)分隔。为了能够使用Python中的数据,需要将csv文件读取到Pandas DataFrame中。DataFrame是表示和使用表格数据的一种方式。表格数据具有行和列,就像此csv文件一样(单击下载)。
例:
# 导入pandas库,重命名为pd
import pandas as pd
# 将IND_data.csv读取到分配给df的DataFrame中
df = pd.read_csv("IND_data.csv")
# 默认输出DataFrame的前5行
df.head()
# 打印DataFrame的行和列数
df.shape输出:

29,10用Pandas索引数据帧
使用pandas.DataFrame.iloc方法可以建立索引。iloc方法允许按位置检索行和列。
例子:
# 打印前5行以及复制df.head()的每一列
df.iloc[0:5,:]
# 打印整行和整列
df.iloc[:,:]
# 从第5行和前5列打印
df.iloc[5:,:5]
在Pandas中使用标签建立索引
可以使用pandas.DataFrame.loc方法对标签进行索引,该方法允许使用标签而非位置进行索引。
例子:
# 打印前五行,包括第五个索引和df的每一列
df.loc[0:5,:]
# 从第5行开始打印并整列打印
df = df.loc[5:,:]上面的内容实际上与df.iloc [0:5 ,:]并没有太大区别。这是因为虽然行标签可以采用任何值,但我们的行标签与位置完全匹配。但是,列标签可以使处理数据时变得更加容易。例:
# 打印时间段值的前5行
df.loc[:5,"Time period"]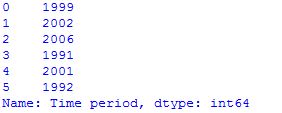
DataFrame Math与Pandas
数据帧的计算可以通过使用pandas工具的统计功能来完成。
例子:
# 计算各种汇总统计信息,不包括NaN值
df.describe()
# 用于计算相关
df.corr()
# 计算数值数据ranks
df.rank()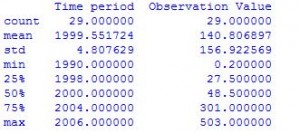


Pandas画图
这些示例中的图是使用用于引用matplotlib API的标准约定制作的,该API提供了Pandas的基础知识,可轻松创建美观的图。
例子:
# 导入所需的模块
import matplotlib.pyplot as plt
# 绘制直方图
df['Observation Value'].hist(bins=10)
# 显示存在许多异常值/极端值
df.boxplot(column='Observation Value', by = 'Time period')
# 绘制点作为散点图
x = df["Observation Value"]
y = df["Time period"]
plt.scatter(x, y, label= "stars", color= "m",
marker= "*", s=30)
# x轴标签
plt.xlabel('Observation Value')
# 频率标签
plt.ylabel('Time period')
# 显示图的功能
plt.show()


{kind=link}