使用Python抓取 Indeed 工作数据
在本文中,我们将看到如何使用Python抓取 Indeed 工作数据。这里我们将使用 Beautiful Soup 和 request 模块来抓取数据。
需要的模块
- bs4 : Beautiful Soup(bs4) 是一个Python库,用于从 HTML 和 XML 文件中提取数据。这个模块没有内置于Python。要安装此类型,请在终端中输入以下命令。
pip install bs4
- requests : Request 允许您非常轻松地发送 HTTP/1.1 请求。这个模块也没有内置于Python。要安装此类型,请在终端中输入以下命令。
pip install requests
方法:
- 导入所有需要的模块。
- 将 getdata()函数(用户定义函数)中的 URL 传递给将请求 URL 的 URL,它返回一个响应。我们使用 get 方法从使用给定 URL 的给定服务器检索信息。
句法:
requests.get(url, args)
- 将该数据转换为 HTML 代码。
在给定的图像中,我们看到了链接,我们在其中搜索了工作及其位置,然后 URL 变成了这样的https://in.indeed.com/jobs?q=”+job+”&l=”+Location,因此我们将我们的字符串格式化为这种格式。

- 现在使用 bs4 解析 HTML 内容。
Syntax: soup = BeautifulSoup(r.content, ‘html5lib’)
Parameters:
- r.content : It is the raw HTML content.
- html.parser : Specifying the HTML parser we want to use.
- 现在使用soup.Find_all函数过滤所需的数据。
- 现在找到带有 class_ = jobtitle turntileLink 标签的列表。您可以在浏览器中打开网页,通过右键单击查看相关元素,如图所示。
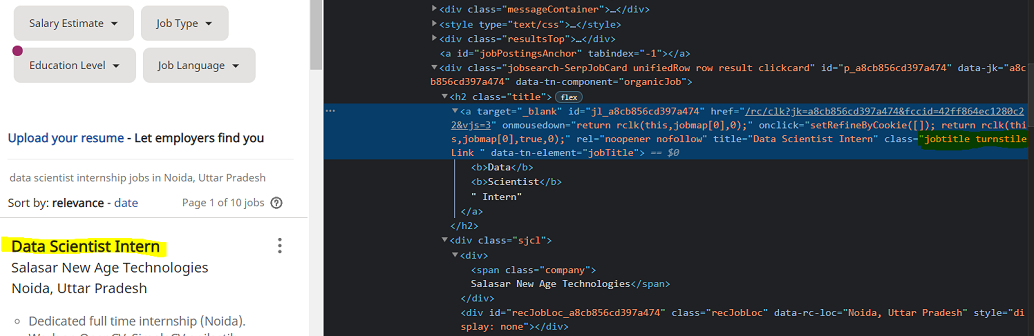
- 用上述方法查找公司名称和地址。
使用的功能:
此实现的代码分为用户定义的函数,以增加代码的可读性并增加易用性。
- geturl():获取要从中抓取数据的 URL
- html_code():获取提供的 URL 的 HTML 代码
- job_data():过滤掉作业数据
- Company_data():过滤公司数据
程序:
Python3
# import module
import requests
from bs4 import BeautifulSoup
# user define function
# Scrape the data
# and get in string
def getdata(url):
r = requests.get(url)
return r.text
# Get Html code using parse
def html_code(url):
# pass the url
# into getdata function
htmldata = getdata(url)
soup = BeautifulSoup(htmldata, 'html.parser')
# return html code
return(soup)
# filter job data using
# find_all function
def job_data(soup):
# find the Html tag
# with find()
# and convert into string
data_str = ""
for item in soup.find_all("a", class_="jobtitle turnstileLink"):
data_str = data_str + item.get_text()
result_1 = data_str.split("\n")
return(result_1)
# filter company_data using
# find_all function
def company_data(soup):
# find the Html tag
# with find()
# and convert into string
data_str = ""
result = ""
for item in soup.find_all("div", class_="sjcl"):
data_str = data_str + item.get_text()
result_1 = data_str.split("\n")
res = []
for i in range(1, len(result_1)):
if len(result_1[i]) > 1:
res.append(result_1[i])
return(res)
# driver nodes/main function
if __name__ == "__main__":
# Data for URL
job = "data+science+internship"
Location = "Noida%2C+Uttar+Pradesh"
url = "https://in.indeed.com/jobs?q="+job+"&l="+Location
# Pass this URL into the soup
# which will return
# html string
soup = html_code(url)
# call job and company data
# and store into it var
job_res = job_data(soup)
com_res = company_data(soup)
# Traverse the both data
temp = 0
for i in range(1, len(job_res)):
j = temp
for j in range(temp, 2+temp):
print("Company Name and Address : " + com_res[j])
temp = j
print("Job : " + job_res[i])
print("-----------------------------")输出:
