RED 队列规则的类型
随机早期检测 (RED),也称为随机早期丢弃或随机早期丢弃,是适用于拥塞避免的网络调度程序的排队规则。有不同类型的 RED 队列规则:
- 温和的红
- 非线性红
- 自配置 RED
- 自适应 RED 队列规则
温和的红色:
当平均队列长度从最小阈值线性增加到最大阈值时,随机早期检测算法将丢弃概率从 0.05 增加到 0.50。但是当平均队列长度略微增加超过最大阈值时,丢包概率直接从 0.50 增加到 1。这种突然的跳跃是不温和的。这种突然的跳跃被温和的 RED 算法标准化。
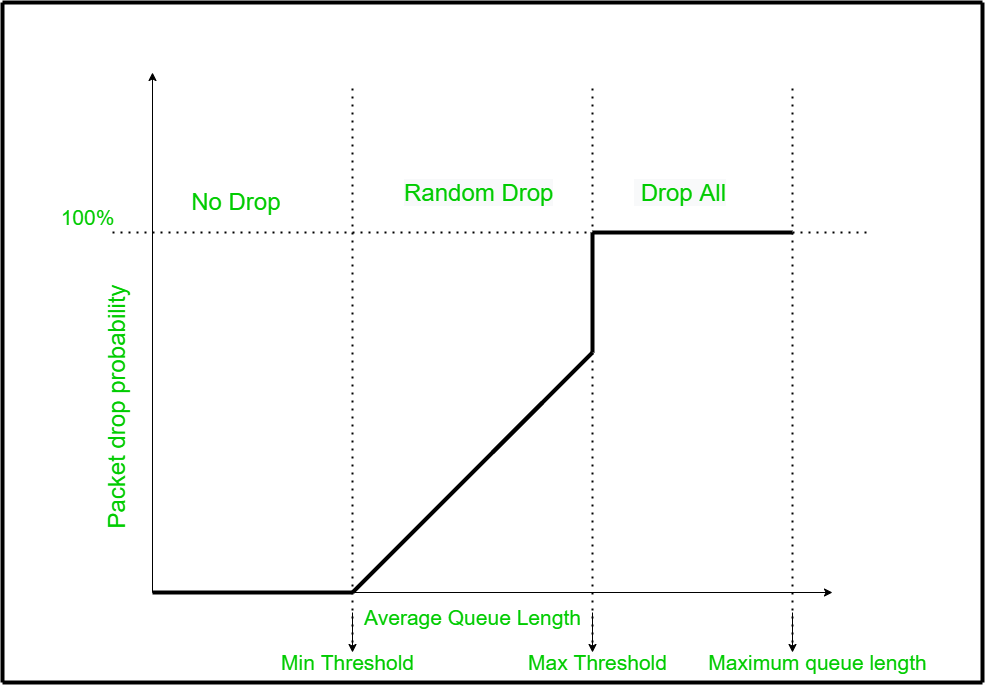
这种行为会导致严重的数据包丢弃,即,当平均队列长度增加到超过 max th时,丢弃概率急剧上升到 1。
Gentle RED 的工作原理:
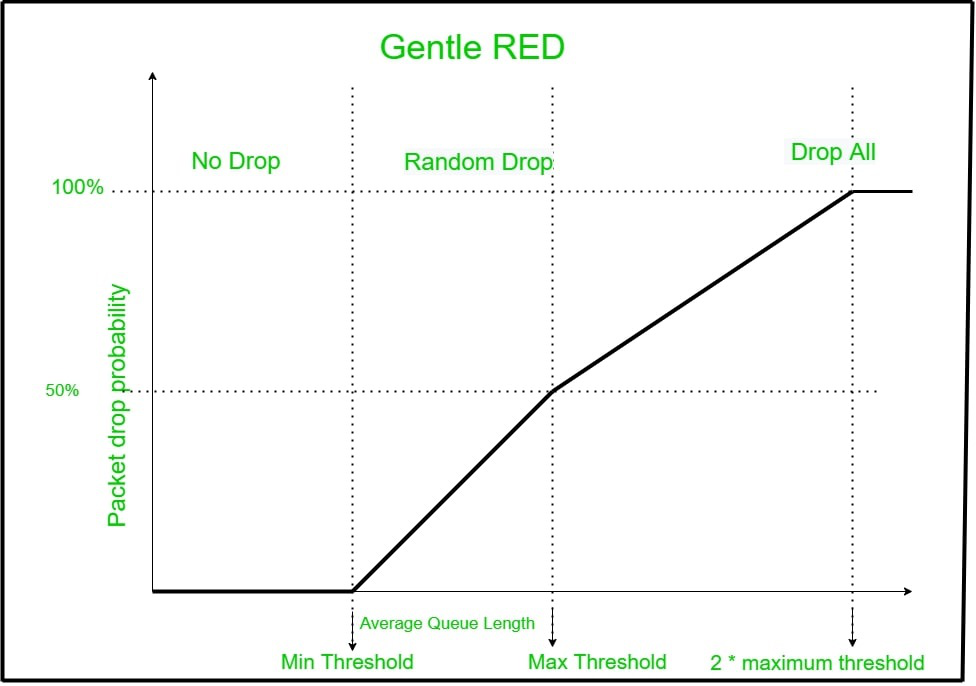
当平均队列长度在 max th和 max th的两倍之间时,Gentle RED 会尝试用类似于原始 RED 的斜率来使这条曲线变平。我们可以很容易地计算出 RED 曲线和 Gentle RED 曲线的斜率。 RED 的坡度约为 79 度,而 Gentle RED 的坡度约为 73 度。 Gentle RED 的工作原理与 RED 相同,只是将掉落概率从 0.5 线性增加到 1。
平均队列长度的计算:
在每个数据包到达时,RED 使用公式计算平均队列长度。 (1)。这种数学模型被称为“指数加权移动平均线”或 EWMA。
=> newavg = (1 – wq) x oldavg + wq x current_queue_len Eq. (1)
=> where, newavg = new average queue length being calculated in this sample.
=> oldavg = old average queue length obtained during the previous sample
=> current_queue_len = ‘instantaneous’ queue length at the router
=> wq = weight associated with the ‘current_queue_len’.
=> Default value: 0.002
掉落概率的计算:
一旦计算出“newavg”,RED 使用以下逻辑来计算丢弃概率 (Pd),其中 min th表示“平均队列长度”的最小阈值,max th表示“平均队列长度”的最大阈值。 min th和 max th是在平均队列长度的上下文中,而不是瞬时队列长度。在我们进一步深入之前,这是一个重要的收获。
=> default value of minth in the paper is 5 packets
=> if (newavg ≤ minth) enqueue the incoming packet
=> default value of maxth in the paper is 15 packets
=> else if (newavg > 2*maxth) it means Pd= 1
=> drop the incoming packet
=> else if(minth < newavg < maxth)
=> Pd= maxp x [(newavg – minth) ÷ (maxth – minth)]
=> else if(maxth < newavg < 2*maxth)
=> Pd= maxp + (1-maxp) x [(newavg – maxth) ÷ maxth] where, maxp = maximum drop probability.
=> Default: 0.5 (previously, it was 0.02)
非线性 RED 和自配置 RED:
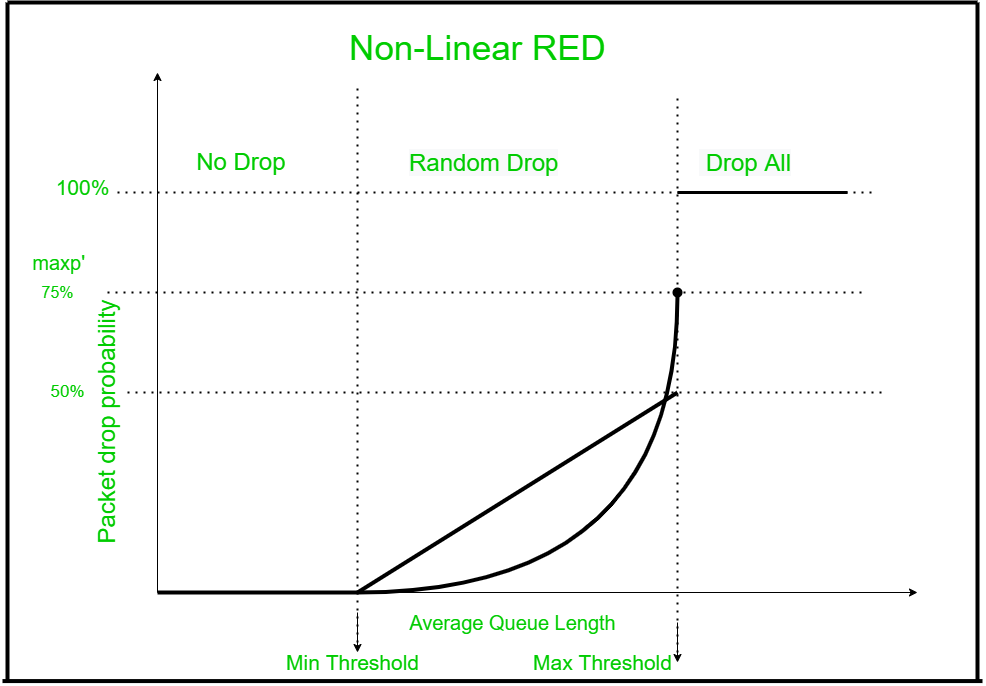
如果 P d在接近 min th时缓慢增加并在接近 max 时急剧增加,而不是线性增加 P d可能会更好。如果丢弃概率在最小阈值和最大阈值之间线性增加,那么即使平均队列长度不大,传入数据包也很有可能被丢弃。因此,为了获得平均队列长度接近最大阈值时丢包的高概率,研究人员继续进行实验,并提出了计算平均队列长度大于阈值时丢包概率的二次方程最小和小于最大阈值。
非线性RED的工作:
=> Pd= 0, when newavg <= minth
=> Pd= 1, when newavg < maxth
=> Pd= (maxp‘)2 * [(newavg – minth)/(maxth – minth)] where maxp‘ = 1.5 * maxp = 0.75
自配置RED的工作:
=> It adapts maxp as shown in the pseudocode below: On every update of ‘newavg’:
=> if (minth < newavg < maxth)
=> status = between;
=> else if (newavg < minth && status != below)
=> status = below;
=> maxp = maxp ÷ ?
=> else if (newavg > maxth && status != above)
=> status = above;
=> maxp = maxp x ?
这个算法中的max p有上限和下限吗?在原始论文中,使用的下限为 0.02,使用的上限为 1。
自适应 RED 队列规则:
Adaptive RED 的动机与自配置 RED 相同。自配置 RED 尝试使用最小和最大阈值来保持平均队列大小。但 Sally Floyd 说,为什么不将平均队列大小保持在最小和最大阈值的中心范围内。此外,Adaptive RED 移除旋钮并自动设置它们。最大丢弃概率根据网络可用性进行调整,不再像以前版本的 RED 那样是一个旋钮。
Adaptive RED 的主要贡献
- 自动设置最小阈值 (min th )。它被设置为链路容量 (C) 和目标队列延迟的函数。
- 自动设置最大阈值(max th) 。它的设置取决于 min th的值。
- wq的自动设置。它被设置为链路容量 (C) 的函数。
- 最大p 的自适应设置。它根据当前平均队列长度进行调整。
自适应 RED 与自配置 RED
1. max p不仅适用于将平均队列大小保持在 min th和 max th之间,而且将平均队列大小保持在 min th和 max th 中间的“目标范围”内。在自配置中,平均队列大小可能会在很大范围内波动,因此可能会频繁发生丢包。但是自适应 RED 所做的是它使平均队列大小几乎保持不变,因为它在一个非常接近的目标范围内波动,该范围仅为最小和最大阈值的一半。
例子:
=> if minth = 5 packets and maxth = 15 packets,
=> then: target range = [minth + 0.4 x (maxth – minth), minth + 0.6 x (maxth – minth)]
=> Hence, target range = [5 + 0.4 (15 – 5), 5 + 0.6 (15 – 5)] = [9, 11]
=> The average queue size will take the values 9, 10, and 11 always. There is no large fluctuation.
2. maxp 适应缓慢,随着时间的推移比典型的往返时间大,而且步幅很小。最大丢弃概率不是很频繁地调整。它每 500 毫秒进行一次调整,这通常是 4-5 RTT 的时间。
3. maxp 被限制在 [0.01, 0.5] 范围内(即 1% 到 50%)。自配置 RED 将最大丢弃概率保持在范围内(0.02 到 1)。
4. AIMD 策略用于适配 maxp,与自配置 RED 中使用的 MIMD 策略不同。与两者都是乘法的自配置不同,最大掉落概率是加法增加和乘法减少。
自动设置最小阈值 (min th )
- 如果 min th设置为低值会怎样?吞吐量下降。 RED 的主要目标是最大化吞吐量和最小化队列延迟时间。如果将最小阈值设置为较低的值,则链路将不会被充分利用,因此吞吐量会降低,这违反了 RED 算法的基本目标。
- 如果 minth 设置为高值会怎样?队列延迟增加。如果最小阈值使用较大的值,则队列大部分时间将满,并且会增加数据包的排队延迟。这再次违反了 RED 的目标。因此,Sally Floyd 表示必须谨慎选择最低阈值,并且它应该实现 RED 的目标。
- 估计 min th的合适值的最佳方法是什么?将最小值设置为链路容量 (C) 的函数。为什么?如果我们固定最小阈值,比如 5,那么如果链路很慢,那么泵送这 5 个数据包将需要更多时间,并且会增加排队延迟。如果链路高,这 5 个数据包将在短时间内被泵送,现在队列为空或占用较少。所以会导致吞吐量的损失。此最小阈值应根据可用链路设置。因此,如果链路很慢,minth 的错误设置会导致高排队延迟,如果链路很快,min th的错误设置会导致吞吐量损失。
确定合适的“目标队列延迟”(即可接受的队列延迟)。网络管理员知道可用带宽,我们可以决定我们可以容忍多少延迟。说 5 ms,这意味着一旦数据包入队,它必须在 5 ms 时间内离开。因此,将 min th设置为目标队列延迟的函数。
=> min is calculated as:
=> minth = (target_queue_delay x C) ÷ 2
=> where, C = capacity of the link in packets (can be obtained by: Bandwidth ÷ packet size), target_queue_delay is 5ms (is a user configurable parameter)
=> Sally Floyd’s recommendation to set the minth automatically is:
=> minth = max [5, (target_queue_delay x C) ÷ 2]
=> minth of 5 packets was found to work well for low and moderate link capacity. So minth of at least 5 packets is recommended to ensure that the throughput is not affected.
自动设置最大阈值 (max th ):
=> maxth is calculated as:
=> maxth = 3 x minth
=> This ensures that the ‘target range’ for average queue size is 2 x minth
=> Suppose, if minth = 5 packets and maxth = 15 packets,
=> then target range = [minth + 0.4 x (maxth – minth), minth + 0.6 x (maxth – minth)]
=> Hence, target range = [5 + 0.4 (15 – 5), 5 + 0.6 (15 – 5)] [9, 11]
wq的自动设置:
- wq 设置为链路容量 (C) 的函数:
wq= 1 - e(-1/C)其中,C 是以包/秒为单位的链路容量(即,带宽 ÷ 包大小)。如果 C 是一个大值,那么 Wq 将是一个太小的值。另一种方式,如果 C 很小,那么 Wq 会更大。
=> The significance of Wq is that:
=> If the queue size changes from one value (old) to another (new), say
=> 60 to 61, 0 to 1 or 50 to 55 or anything then, it takes “-1 / ln (1 – wq)” packet arrivals for the ‘average queue size’ to reach 63% of the ‘new queue size’.
=> If current queue size changes from 60 to 61 and Wq=0.002 then if
=> current queue size remains constant for 500 packet arrivals then average queue size will become 63% of current queue size, i.e. 38.
- 因此,“-1 / ln (1 – wq)”被称为平均队列大小的估计器的“时间常数”(但它是在数据包到达中指定的,而不是实际上在时间上)。
- 示例:如果 wq= 0.002,它对应于 500 个数据包到达。但假设如果可用带宽为 1Gbps,则 500 个数据包到达只占一小部分时间。因此,更小的 wq 值会更好。
调整最大p :
=> It is adapted in every 500 ms.
=> Every interval seconds: if(average_queue_size > target_range and maxp < 0.5)
=> increase maxp;
=> maxp <- maxp + α
=> else if(average_queue_size < target_range and maxp > 0.01)
=> decrease maxp;
=> maxp <- maxp * β
=> interval: 0.5 second
=> target_range: [minth + 0.4(maxth – minth),
=> minth + 0.6(maxth – minth)]
=> α: increament factor, α = min(0.01, maxp/4)
=>β: decrement factor, β = 0.9