MatPlotLib 中的堆积百分比条形图
堆叠百分比条形图是一个简单的堆叠形式的条形图,其中包含一个组中每个子组的百分比。堆积条形图代表不同组在彼此的顶部。条形的高度取决于组结果组合的结果高度。它从底部到值,而不是从零到值。百分比堆积条形图与堆积条形图几乎相同。子组显示在彼此的顶部,但数据被归一化以使每个子组的总和与每个子组的总和相同。
以下示例中使用的数据集如下所示:
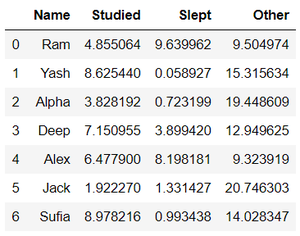
数据集可以从这里下载。
过程:绘制堆积百分比条形图的过程是以下步骤,下面通过示例进行描述:
1. 使用数据(数据集、字典等)绘制堆积条形图。
Python3
# importing packages
import pandas as pd
import matplotlib.pyplot as plt
# load dataset
df = pd.read_excel("Hours.xlsx")
# view dataset
print(df)
# plot a Stacked Bar Chart using matplotlib
df.plot(
x = 'Name',
kind = 'barh',
stacked = True,
title = 'Stacked Bar Graph',
mark_right = True)Python3
# importing packages
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# load dataset
df = pd.read_excel("Hours.xlsx")
# view dataset
print(df)
# plot a Stacked Bar Chart using matplotlib
df.plot(
x = 'Name',
kind = 'barh',
stacked = True,
title = 'Percentage Stacked Bar Graph',
mark_right = True)
df_total = df["Studied"] + df["Slept"] + df["Other"]
df_rel = df[df.columns[1:]].div(df_total, 0)*100
for n in df_rel:
for i, (cs, ab, pc) in enumerate(zip(df.iloc[:, 1:].cumsum(1)[n],
df[n], df_rel[n])):
plt.text(cs - ab / 2, i, str(np.round(pc, 1)) + '%',
va = 'center', ha = 'center')Python3
# importing packages
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# load dataset
df = pd.read_xlsx("Hours.xlsx")
# view dataset
print(df)
# plot a Stacked Bar Chart using matplotlib
df.plot(
x = 'Name',
kind = 'barh',
stacked = True,
title = 'Percentage Stacked Bar Graph',
mark_right = True)
df_total = df["Studied"] + df["Slept"] + df["Other"]
df_rel = df[df.columns[1:]].div(df_total, 0) * 100
for n in df_rel:
for i, (cs, ab, pc) in enumerate(zip(df.iloc[:, 1:].cumsum(1)[n],
df[n], df_rel[n])):
plt.text(cs - ab / 2, i, str(np.round(pc, 1)) + '%',
va = 'center', ha = 'center', rotation = 20, fontsize = 8)输出:
Name Studied Slept Other
0 Ram 4.855064 9.639962 9.504974
1 Yash 8.625440 0.058927 15.315634
2 Alpha 3.828192 0.723199 19.448609
3 Deep 7.150955 3.899420 12.949625
4 Alex 6.477900 8.198181 9.323919
5 Jack 1.922270 1.331427 20.746303
6 Sufia 8.978216 0.993438 14.028347
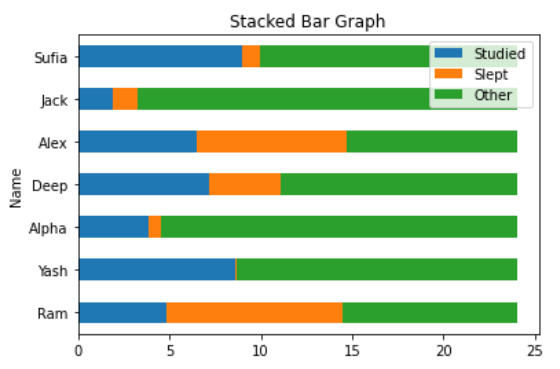
2. 在每个组的子组上添加百分比。
蟒蛇3
# importing packages
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# load dataset
df = pd.read_excel("Hours.xlsx")
# view dataset
print(df)
# plot a Stacked Bar Chart using matplotlib
df.plot(
x = 'Name',
kind = 'barh',
stacked = True,
title = 'Percentage Stacked Bar Graph',
mark_right = True)
df_total = df["Studied"] + df["Slept"] + df["Other"]
df_rel = df[df.columns[1:]].div(df_total, 0)*100
for n in df_rel:
for i, (cs, ab, pc) in enumerate(zip(df.iloc[:, 1:].cumsum(1)[n],
df[n], df_rel[n])):
plt.text(cs - ab / 2, i, str(np.round(pc, 1)) + '%',
va = 'center', ha = 'center')
输出:
Name Studied Slept Other
0 Ram 4.855064 9.639962 9.504974
1 Yash 8.625440 0.058927 15.315634
2 Alpha 3.828192 0.723199 19.448609
3 Deep 7.150955 3.899420 12.949625
4 Alex 6.477900 8.198181 9.323919
5 Jack 1.922270 1.331427 20.746303
6 Sufia 8.978216 0.993438 14.028347

3. 使用一些功能编辑图表(可选)。
蟒蛇3
# importing packages
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# load dataset
df = pd.read_xlsx("Hours.xlsx")
# view dataset
print(df)
# plot a Stacked Bar Chart using matplotlib
df.plot(
x = 'Name',
kind = 'barh',
stacked = True,
title = 'Percentage Stacked Bar Graph',
mark_right = True)
df_total = df["Studied"] + df["Slept"] + df["Other"]
df_rel = df[df.columns[1:]].div(df_total, 0) * 100
for n in df_rel:
for i, (cs, ab, pc) in enumerate(zip(df.iloc[:, 1:].cumsum(1)[n],
df[n], df_rel[n])):
plt.text(cs - ab / 2, i, str(np.round(pc, 1)) + '%',
va = 'center', ha = 'center', rotation = 20, fontsize = 8)
输出:
Name Studied Slept Other
0 Ram 4.855064 9.639962 9.504974
1 Yash 8.625440 0.058927 15.315634
2 Alpha 3.828192 0.723199 19.448609
3 Deep 7.150955 3.899420 12.949625
4 Alex 6.477900 8.198181 9.323919
5 Jack 1.922270 1.331427 20.746303
6 Sufia 8.978216 0.993438 14.028347
